From Local to Global: A Graph RAG Approach to Query-Focused Summarization
by Microsoft Research
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델(LLM)의 발전에도 불구하고, 방대한 문서 컬렉션에 대한 포괄적인 이해와 의미 파악은 여전히 도전적인 과제로 남아있습니다. 기존의 검색 증강 생성(RAG) 시스템들은 지역적 문맥만을 고려하여 “데이터셋의 주요 주제는 무엇인가요?”와 같은 전체적인 이해를 요구하는 질문에 효과적으로 대응하지 못했습니다. 또한 기존의 쿼리 중심 요약(QFS) 방법들은 RAG 시스템이 다루는 방대한 텍스트를 처리하는 데 한계가 있었습니다. 이러한 간극을 메우기 위해 연구진은 문서 간의 복잡한 관계와 정보의 흐름을 효과적으로 포착할 수 있는 새로운 접근법의 필요성을 인식했습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
연구진은 그래프 RAG(Graph RAG)라는 혁신적인 접근법을 제안했습니다. 이 방법은 대규모 언어 모델을 활용하여 두 단계로 그래프 기반 텍스트 색인을 구축합니다. 첫째, 소스 문서에서 엔티티 지식 그래프를 도출하고, 둘째, 밀접하게 관련된 엔티티 그룹들에 대한 커뮤니티 요약을 사전에 생성합니다. 이러한 계층적 구조를 통해 사용자 질문에 대해 각 커뮤니티 요약을 활용하여 부분 응답을 생성하고, 이를 종합하여 포괄적인 최종 응답을 만들어냅니다. 특히 그래프의 모듈성을 활용하여 효율적인 정보 조직화와 검색을 가능하게 했습니다.
제안된 방법은 어떻게 구현되었습니까?
구현은 크게 네 단계로 이루어집니다. 먼저 소스 문서를 의미 있는 청크로 분할하고, LLM을 사용하여 엔티티와 관계를 추출합니다. 다음으로 Leiden 알고리즘을 사용하여 그래프의 커뮤니티 구조를 탐지하고, 각 커뮤니티에 대한 요약을 생성합니다. 마지막으로 사용자 쿼리가 주어지면 관련 커뮤니티 요약들을 활용하여 맵-리듀스 방식으로 최종 답변을 생성합니다. 실험은 약 100만 토큰 규모의 두 데이터셋(팟캐스트 전사본과 뉴스 기사)에서 수행되었으며, 다양한 커뮤니티 레벨과 컨텍스트 윈도우 크기에 대한 철저한 평가가 이루어졌습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
실험 결과는 그래프 RAG가 기존 RAG 시스템과 비교하여 답변의 포괄성(72-83%)과 다양성(62-82%) 측면에서 상당한 개선을 달성했음을 보여줍니다. 특히 주목할 만한 점은 효율성입니다. 루트 레벨 커뮤니티 요약은 소스 텍스트 요약보다 97% 더 적은 토큰을 사용하면서도 경쟁력 있는 성능을 유지했습니다. 이는 대규모 문서 컬렉션에 대한 의미 파악과 전역적 이해를 위한 실용적인 솔루션의 가능성을 제시합니다. 또한 오픈소스로 공개될 예정인 이 구현은 향후 그래프 기반 RAG 시스템의 발전을 위한 중요한 기반이 될 것으로 기대됩니다.
로컬에서 글로벌로: 쿼리 중심 요약을 위한 그래프 RAG 접근법
최근 검색 증강 생성(Retrieval-Augmented Generation, RAG) 기술은 대규모 언어 모델의 성능을 크게 향상시키는 중요한 방법론으로 주목받고 있습니다. Microsoft Research를 중심으로 한 연구진은 쿼리 중심 요약(Query-Focused Summarization) 작업에 특화된 새로운 그래프 기반 RAG 접근법을 제안했습니다.
이 연구는 기존 RAG 시스템들이 지역적 문맥만을 고려하는 한계를 극복하고자 합니다. 저자들은 문서 간의 복잡한 관계와 정보의 흐름을 효과적으로 포착하기 위해 그래프 구조를 활용하는 방법을 제시했습니다. 이는 Gao와 연구진이 제시한 전통적인 RAG 프레임워크를 확장한 것으로, 단순히 개별 문서를 검색하는 것을 넘어 문서들 간의 연결성을 고려할 수 있게 합니다.
특히 이 연구는 He와 연구진이 개발한 G-Retriever의 개념을 확장하여, 텍스트 그래프에 대한 이해를 쿼리 중심 요약 작업에 적용했습니다. 이를 통해 문서 집합에서 쿼리와 관련된 정보를 더욱 정확하게 추출하고, 이를 바탕으로 응집력 있는 요약을 생성할 수 있게 되었습니다.
연구진은 Microsoft Research, Microsoft Strategic Missions and Technologies, 그리고 Microsoft Office of the CTO의 협력을 통해 이 혁신적인 접근법을 개발했습니다. 이는 학계와 산업계의 전문성을 결합하여 실제 응용 가능한 솔루션을 만들어내고자 하는 노력을 보여줍니다.
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 대규모 언어 모델(Large Language Models, LLMs)이 외부 지식 소스에서 관련 정보를 검색하여 비공개 문서나 이전에 보지 못한 문서 모음에 대한 질문에 답변할 수 있게 해주는 혁신적인 기술입니다. 하지만 RAG는 “데이터셋의 주요 주제는 무엇인가요?”와 같이 전체 텍스트 말뭉치를 대상으로 하는 포괄적인 질문에 대해서는 효과적으로 작동하지 못하는 한계가 있습니다. 이는 이러한 유형의 질문이 본질적으로 명시적인 검색 작업이 아닌 쿼리 중심 요약(Query-Focused Summarization, QFS) 작업이기 때문입니다.
반면, 기존의 QFS 방법들은 일반적인 RAG 시스템이 색인화하는 방대한 양의 텍스트를 처리하는 데 어려움을 겪습니다. 이러한 상반된 방법론의 장점을 결합하기 위해, 연구진은 그래프 RAG(Graph RAG)라는 새로운 접근 방식을 제안했습니다. 이 방법은 사용자 질문의 일반성과 색인화해야 할 소스 텍스트의 양 모두에 효과적으로 대응할 수 있습니다.
그래프 RAG는 대규모 언어 모델을 활용하여 두 단계로 그래프 기반 텍스트 색인을 구축합니다. 첫째, 소스 문서에서 엔티티 지식 그래프를 도출하고, 둘째, 밀접하게 관련된 엔티티 그룹들에 대한 커뮤니티 요약을 사전에 생성합니다. 사용자가 질문을 하면, 각 커뮤니티 요약을 활용하여 부분 응답을 생성한 후, 이러한 부분 응답들을 다시 종합하여 최종 응답을 만들어냅니다.
연구진은 100만 토큰 규모의 데이터셋에 대한 전반적인 이해를 요구하는 질문들에 대해, 그래프 RAG가 기본적인 RAG 방식과 비교하여 생성된 답변의 포괄성과 다양성 측면에서 상당한 개선을 이끌어냈음을 입증했습니다. 이 연구의 글로벌 및 로컬 그래프 RAG 접근법에 대한 파이썬 기반 오픈소스 구현은 Github에서 공개될 예정입니다.
서론
대규모 문서 컬렉션을 읽고 이해하여 문서에 명시적으로 언급되지 않은 결론까지 도출하는 능력은 다양한 분야의 인간 활동에서 핵심적인 역량입니다. 최근 대규모 언어 모델(Large Language Models, LLMs)의 등장으로 과학적 발견이나 정보 분석과 같은 복잡한 영역에서 인간과 유사한 의미 파악을 자동화하려는 시도가 이루어지고 있습니다.
여기서 ‘의미 파악(sensemaking)’이란 Klein과 연구진이 정의한 바와 같이 “사람, 장소, 사건 간의 연결을 이해하고 이들의 궤적을 예측하여 효과적으로 행동하기 위한 동기 부여된 지속적인 노력”을 의미합니다. 하지만 전체 텍스트 말뭉치에 대한 인간 주도의 의미 파악을 지원하기 위해서는 사용자가 데이터에 대한 자신의 멘탈 모델을 적용하고 개선할 수 있는 방법이 필요합니다.
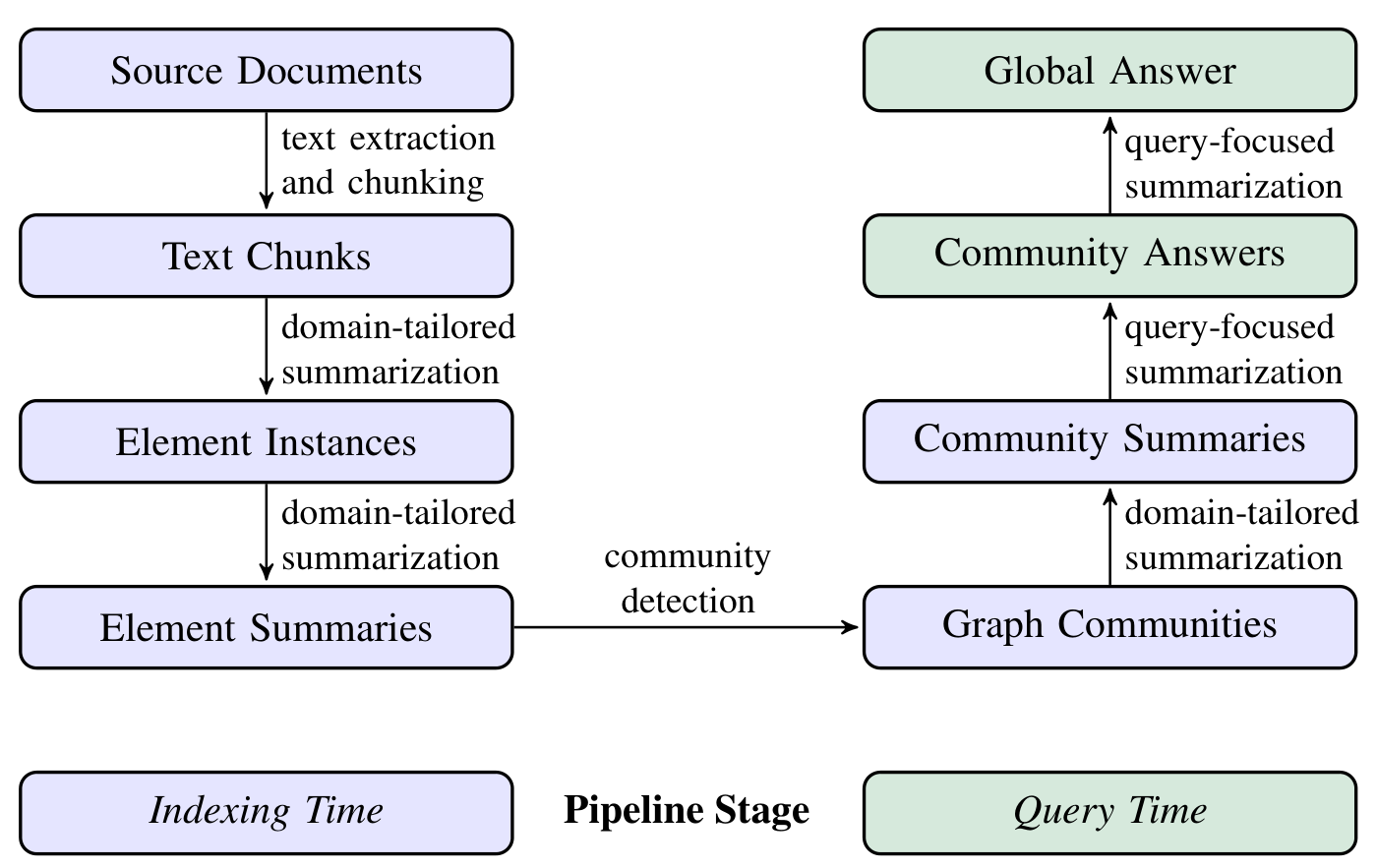
이 연구에서는 텍스트 기반 질의응답 시스템을 위한 파이프라인을 제시합니다. 소스 문서로부터 텍스트를 추출하고 청킹한 후, 도메인에 특화된 요약과 커뮤니티 탐지를 통해 커뮤니티 요약을 생성합니다. 이러한 요약은 최종적으로 쿼리 중심 요약을 통해 글로벌 답변을 생성하는 데 활용됩니다.
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 전체 데이터셋에 대한 사용자 질문에 답변하는 확립된 접근 방식이지만, 이는 검색된 텍스트 영역 내에서 답변이 포함되어 있는 상황에 적합하도록 설계되었습니다. 대신, 더 적절한 과제 프레임은 쿼리 중심 요약(Query-Focused Summarization, QFS)이며, 특히 자연어 요약을 생성하는 쿼리 중심 추상적 요약이 필요합니다.
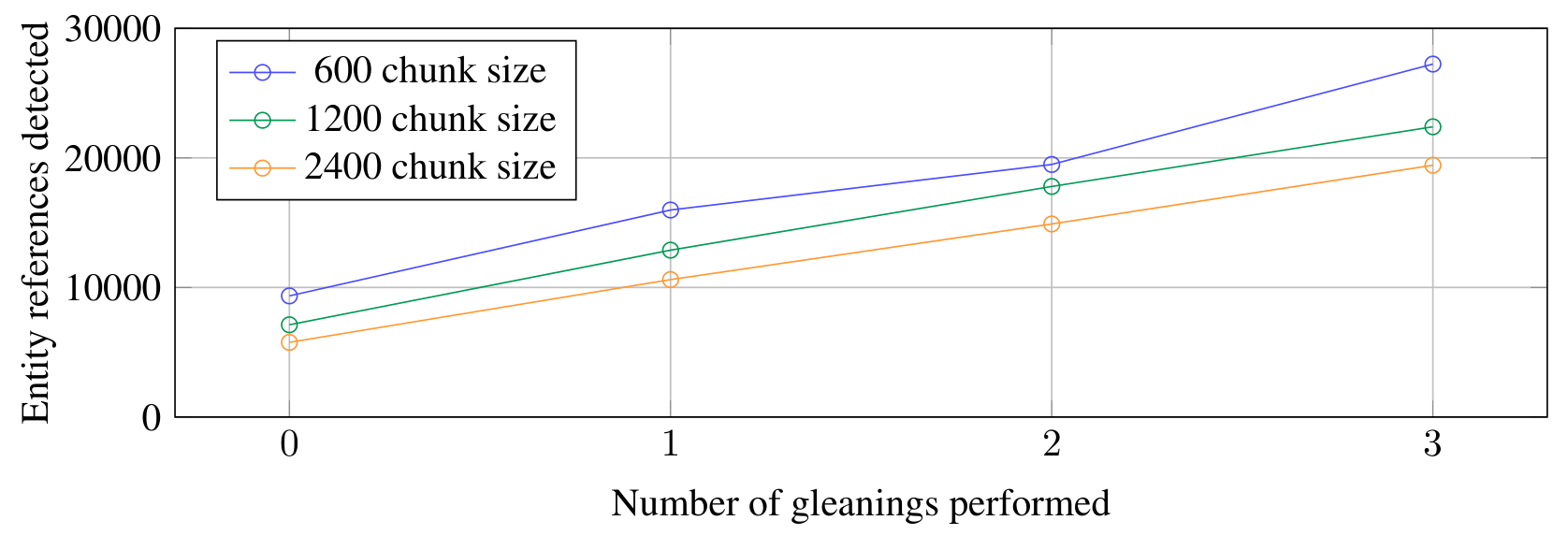
이 그래프는 HotPotQA 데이터셋에서 청크 크기와 글리닝(gleaning) 횟수에 따른 엔티티 참조 탐지 결과를 보여줍니다. 일반적인 엔티티 추출 프롬프트를 GPT-4-turbo에 적용한 결과, 더 큰 청크 크기에서 더 많은 엔티티 참조가 탐지되었음을 알 수 있습니다.
최근 트랜스포머 아키텍처의 발전으로 다양한 요약 작업에서 상당한 성능 향상이 이루어졌으며, GPT, Llama, Gemini 시리즈와 같은 현대적 LLM들은 문맥 학습을 통해 주어진 컨텍스트 윈도우 내의 모든 콘텐츠를 요약할 수 있게 되었습니다. 하지만 전체 말뭉치에 대한 쿼리 중심 추상적 요약이라는 과제는 여전히 도전적입니다. 이러한 도전 과제의 핵심은 텍스트의 양이 LLM의 컨텍스트 윈도우 제한을 크게 초과할 수 있다는 점입니다. 컨텍스트 윈도우의 확장만으로는 이 문제를 해결하기에 충분하지 않을 수 있는데, 이는 Liu와 연구진이 지적한 바와 같이 긴 컨텍스트에서 정보가 “중간에 손실되는” 현상이 발생하기 때문입니다.
이러한 한계를 극복하기 위해 연구진은 전역 요약을 위한 새로운 형태의 사전 색인화가 필요하다고 판단했습니다. 이에 따라 본 논문에서는 LLM으로 도출된 지식 그래프의 전역 요약을 기반으로 하는 그래프 RAG(Graph RAG) 접근법을 제시합니다.
기존의 그래프 색인을 활용한 연구들이 구조화된 검색과 탐색의 이점을 활용하는 데 중점을 둔 것과 달리, 이 연구는 그래프의 새로운 특성에 주목합니다. 바로 Newman이 연구한 그래프의 본질적 모듈성과 Leiden이나 Louvain과 같은 커뮤니티 탐지 알고리즘을 통해 밀접하게 연관된 노드들의 커뮤니티로 그래프를 분할할 수 있다는 점입니다.
연구진은 이 접근법의 효과를 검증하기 위해 두 가지 대표적인 실제 데이터셋에서 활동 중심의 의미 파악 질문들을 LLM을 통해 생성했습니다. 평가는 포괄성(comprehensiveness), 다양성(diversity), 그리고 권한 부여(empowerment)라는 세 가지 목표 품질을 기준으로 수행되었으며, 이는 광범위한 이슈와 주제에 대한 이해를 발전시키는 데 필수적인 요소들입니다.
실험에서는 쿼리에 답변하는 데 사용되는 커뮤니티 요약의 계층적 수준을 다양화하면서 그 영향을 탐구했고, 기본적인 RAG 방식 및 소스 텍스트의 전역 맵-리듀스 요약과도 비교를 수행했습니다. 그 결과, 모든 전역 접근법이 포괄성과 다양성 측면에서 기본적인 RAG를 능가했으며, 특히 중간 및 하위 수준의 커뮤니티 요약을 활용한 그래프 RAG가 더 적은 토큰 비용으로도 소스 텍스트 요약보다 우수한 성능을 보여주었습니다.
그래프 RAG 접근법과 파이프라인
그래프 RAG의 데이터 흐름과 파이프라인을 자세히 살펴보겠습니다. 이 접근법은 문서 컬렉션에서 의미 있는 정보를 추출하고 구조화하기 위한 체계적인 프레임워크를 제공합니다.
파이프라인은 크게 세 가지 주요 단계로 구성됩니다. 첫째, 소스 문서에서 텍스트를 추출하고 이를 관리 가능한 청크로 분할합니다. 이 과정에서 문서의 구조적 특성을 보존하면서도 효율적인 처리가 가능한 단위로 텍스트를 나눕니다.
둘째, 도메인에 특화된 요약과 커뮤니티 탐지 작업을 수행합니다. 이 단계에서는 Louvain이나 Leiden과 같은 커뮤니티 탐지 알고리즘을 활용하여 텍스트 청크들 간의 의미적 연관성을 파악하고, 이를 바탕으로 커뮤니티를 식별합니다. 각 커뮤니티는 특정 주제나 개념을 중심으로 형성된 텍스트 그룹을 나타냅니다.
셋째, 식별된 커뮤니티들에 대해 요약을 생성합니다. 이 과정에서는 대규모 언어 모델을 활용하여 각 커뮤니티의 핵심 내용을 응집력 있게 요약합니다. 이러한 커뮤니티 요약들은 최종적으로 사용자의 쿼리에 대한 글로벌 답변을 생성하는 데 활용됩니다.
파이프라인의 핵심 설계 매개변수들은 다음과 같은 수식으로 표현될 수 있습니다.
\[C(d) = \{c_1, c_2, ..., c_n\} \text{ where } c_i \text{ represents chunk } i \text{ of document } d\]여기서 \(C(d)\)는 문서 \(d\)의 청크 집합을 나타내며, 각 청크 \(c_i\)는 의미적으로 일관된 텍스트 단위입니다.
커뮤니티 탐지 과정은 다음과 같이 모델링됩니다.
\[G = (V, E, W) \text{ where } V \text{ represents chunks, } E \text{ represents edges, and } W \text{ represents edge weights}\]이때 엣지 가중치 \(W\)는 청크 간의 의미적 유사도를 반영하며, 커뮤니티 \(K\)는 다음과 같이 정의됩니다.
\[K = \{k_1, k_2, ..., k_m\} \text{ where each } k_i \text{ is a subset of } V \text{ with high internal connectivity}\]이러한 수학적 프레임워크를 바탕으로, 그래프 RAG는 문서 컬렉션의 구조적 특성을 효과적으로 포착하고 활용할 수 있습니다.
그래프 RAG 접근법과 파이프라인
그래프 RAG 파이프라인의 구현 세부사항과 최적화 전략을 살펴보겠습니다. 파이프라인의 각 단계는 특정 설계 매개변수와 기술을 활용하여 효율적인 처리를 보장합니다.
텍스트 청킹 단계에서는 문서의 의미적 일관성을 유지하면서도 효율적인 처리가 가능한 크기로 분할하는 것이 중요합니다. 청크 크기 \(s\)는 다음과 같은 제약 조건을 만족해야 합니다.
\[L_{min} \leq s \leq L_{max} \text{ where } L_{min} \text{ is minimum coherent unit and } L_{max} \text{ is LLM context window}\]엔티티 추출과 관계 모델링 과정에서는 대규모 언어 모델을 활용하여 각 청크에서 의미 있는 엔티티들을 식별하고, 이들 간의 관계를 그래프 구조로 표현합니다. 이때 엔티티 간 관계의 강도 \(r_{ij}\)는 다음과 같이 계산됩니다.
\[r_{ij} = f(e_i, e_j, c) \text{ where } f \text{ is a relation scoring function based on context } c\]커뮤니티 탐지 알고리즘의 구현에서는 모듈성(modularity) 최적화를 통해 의미적으로 응집력 있는 그룹을 식별합니다. 모듈성 \(Q\)는 다음과 같이 정의됩니다.
\[Q = \frac{1}{2m}\sum_{ij} \left(A_{ij} - \frac{k_i k_j}{2m}\right)\delta(c_i, c_j)\]여기서 \(A_{ij}\)는 인접 행렬의 원소, \(k_i\)와 \(k_j\)는 노드의 차수, \(m\)은 전체 엣지 수, \(\delta(c_i, c_j)\)는 두 노드가 같은 커뮤니티에 속하는지를 나타내는 지시 함수입니다.
커뮤니티 요약 생성 단계에서는 각 커뮤니티의 특성을 고려한 계층적 접근 방식을 사용합니다. 요약의 품질 \(Q_s\)는 다음 세 가지 측면을 고려하여 평가됩니다.
\[Q_s = \alpha C + \beta D + \gamma E\]여기서 \(C\)는 포괄성(comprehensiveness), \(D\)는 다양성(diversity), \(E\)는 권한 부여(empowerment)를 나타내며, \(\alpha\), \(\beta\), \(\gamma\)는 각각의 가중치입니다.
이러한 수학적 프레임워크를 바탕으로, 그래프 RAG는 ForceAtlas2와 같은 그래프 레이아웃 알고리즘을 활용하여 시각화와 분석을 위한 효과적인 그래프 표현을 생성합니다. 이는 사용자가 문서 컬렉션의 구조를 직관적으로 이해하고 탐색할 수 있게 해줍니다.
그래프 RAG 접근법과 파이프라인
그래프 RAG 파이프라인의 구현에서 가장 중요한 기술적 혁신은 지식 그래프 구축과 커뮤니티 기반 요약의 통합입니다. 이 접근법은 Khattab과 연구진이 제안한 Demonstrate-Search-Predict (DSP) 프레임워크의 장점을 활용하면서도, 그래프 구조를 통해 더 효과적인 정보 조직화를 달성합니다.
파이프라인의 핵심 구성 요소 중 하나는 엔티티 참조 탐지 시스템입니다. 이 시스템은 GPT-4-turbo와 같은 대규모 언어 모델을 활용하여 텍스트에서 의미 있는 엔티티들을 추출합니다. 엔티티 추출의 정확도 \(A_e\)는 다음과 같이 정의됩니다.
\[A_e = \frac{\text{correctly identified entities}}{\text{total number of true entities}} \times \frac{\text{correctly identified entities}}{\text{total predicted entities}}\]추출된 엔티티들 간의 관계는 그래프 구조로 모델링되며, 이때 Zhang과 연구진이 제안한 Graph-ToolFormer의 접근 방식을 확장하여 더 정교한 관계 추론을 수행합니다. 관계의 신뢰도 점수 \(S_r\)는 다음과 같이 계산됩니다.
\[S_r(e_i, e_j) = \text{LLM}(\text{context}(e_i, e_j)) \cdot w_r\]여기서 \(\text{LLM}\)은 언어 모델의 관계 평가 함수이고, \(w_r\)은 관계 유형별 가중치입니다.
커뮤니티 탐지 과정에서는 Fortunato가 제안한 엣지 비트니스(edge betweenness) 기반 알고리즘을 개선하여 사용합니다. 엣지 비트니스 \(B_e\)는 다음과 같이 계산됩니다.
\[B_e = \sum_{s,t \in V} \frac{\sigma_{st}(e)}{\sigma_{st}}\]여기서 \(\sigma_{st}\)는 노드 \(s\)와 \(t\) 사이의 최단 경로의 수이고, \(\sigma_{st}(e)\)는 그 중 엣지 \(e\)를 통과하는 경로의 수입니다.
이러한 기술적 구성 요소들이 통합되어 작동하는 파이프라인은 Shao와 연구진이 제안한 Iterative Retrieval-Generation Synergy의 개념을 그래프 도메인으로 확장한 것으로 볼 수 있습니다. 이를 통해 문서 컬렉션의 전역적 구조를 효과적으로 포착하고 활용할 수 있게 됩니다.
소스 문서에서 텍스트 청크로의 변환
소스 문서를 처리하는 과정에서 가장 중요한 설계 결정은 입력 텍스트를 어떤 크기의 청크(chunk)로 분할할 것인가 하는 점입니다. 이러한 청크 단위는 이후 그래프 인덱스의 다양한 요소들을 추출하기 위한 LLM 프롬프트에 입력으로 사용됩니다.
청크 크기 선택에는 중요한 트레이드오프가 존재합니다. 더 긴 텍스트 청크를 사용하면 LLM 호출 횟수를 줄일 수 있다는 장점이 있지만, Kuratov와 연구진이 발견한 것처럼 LLM의 컨텍스트 윈도우가 길어질수록 정보 회수(recall) 성능이 저하되는 문제가 있습니다. Liu와 연구진의 연구에서도 이러한 현상이 확인되었습니다.
이러한 트레이드오프는 HotpotQA 데이터셋을 사용한 실험 결과에서 명확하게 드러납니다. 단일 추출 라운드(gleaning이 0인 경우)에서 600 토큰 크기의 청크를 사용했을 때는 2400 토큰 크기의 청크를 사용했을 때보다 거의 두 배에 가까운 엔티티 참조를 추출할 수 있었습니다. 이는 다음과 같은 수식으로 표현할 수 있습니다.
\[R_{600} \approx 2 \times R_{2400}\]여기서 \(R_n\)은 청크 크기가 \(n\) 토큰일 때의 엔티티 참조 추출 수를 나타냅니다.
이러한 현상은 LLM의 컨텍스트 처리 능력과 관련이 있으며, 다음과 같은 일반적인 관계로 모델링할 수 있습니다.
\[E(c) = \frac{K}{1 + \alpha \cdot \text{size}(c)}\]여기서 \(E(c)\)는 청크 \(c\)에서의 엔티티 추출 효율성, \(K\)는 상수, \(\text{size}(c)\)는 청크의 크기, \(\alpha\)는 성능 저하 계수를 나타냅니다.
따라서 실제 응용에서는 더 많은 엔티티 참조를 추출하는 것이 일반적으로 유리하지만, 대상 작업의 특성에 따라 정밀도(precision)와 재현율(recall) 사이의 적절한 균형을 찾는 것이 중요합니다. 이는 다음과 같은 최적화 문제로 볼 수 있습니다.
\[\text{optimal_size} = \arg\max_{\text{size}} \left(\beta \cdot \text{precision}(\text{size}) + (1-\beta) \cdot \text{recall}(\text{size})\right)\]여기서 \(\beta\)는 정밀도와 재현율의 상대적 중요도를 조절하는 가중치입니다.
텍스트 청크에서 엔티티 인스턴스로의 변환
텍스트 청크에서 그래프 노드와 엣지의 인스턴스를 식별하고 추출하는 과정은 그래프 RAG 시스템의 핵심 단계입니다. 이 과정은 다단계 LLM 프롬프트를 활용하여 수행됩니다.
프롬프트의 첫 번째 단계에서는 텍스트에서 모든 엔티티를 식별합니다. 각 엔티티에 대해 이름(name), 유형(type), 설명(description)을 추출합니다. 두 번째 단계에서는 명확하게 관련된 엔티티들 간의 모든 관계를 식별하며, 이때 소스 엔티티와 타겟 엔티티, 그리고 이들 간의 관계에 대한 설명을 함께 추출합니다. 이러한 두 종류의 요소 인스턴스는 구분자로 분리된 튜플 리스트 형태로 출력됩니다.
이 프로세스의 핵심적인 특징은 문서 말뭉치의 도메인에 맞춰 프롬프트를 조정할 수 있다는 점입니다. Brown과 연구진이 제안한 컨텍스트 내 학습(in-context learning)을 위한 퓨 샷 예제를 선택하는 것이 이러한 도메인 적응의 주요 수단이 됩니다. 예를 들어, 기본 프롬프트는 사람, 장소, 조직과 같은 일반적인 “명명된 엔티티”를 추출하도록 설계되어 있지만, 과학, 의학, 법률과 같은 전문 지식이 필요한 도메인에서는 해당 도메인에 특화된 퓨 샷 예제를 활용하여 성능을 향상시킬 수 있습니다.
추출된 노드 인스턴스와 연관시키고자 하는 추가적인 공변량(covariate)을 위한 보조 추출 프롬프트도 지원됩니다. 기본 공변량 프롬프트는 검출된 엔티티와 연결된 주장(claim)을 추출하는 것을 목표로 하며, 이는 주체(subject), 객체(object), 유형(type), 설명(description), 소스 텍스트 범위(source text span), 시작 및 종료 날짜를 포함합니다.
효율성과 품질의 균형을 맞추기 위해, 시스템은 지정된 최대치까지 여러 라운드의 “글리닝(gleaning)”을 수행합니다. 이는 LLM이 이전 추출 라운드에서 놓쳤을 수 있는 추가 엔티티를 감지하도록 장려하는 과정입니다. 이는 다단계 프로세스로, 먼저 LLM에게 모든 엔티티가 추출되었는지 평가하도록 요청하며, 이때 yes/no 결정을 강제하기 위해 100의 로짓 바이어스를 적용합니다. LLM이 엔티티가 누락되었다고 응답하면, “이전 추출에서 많은 엔티티가 누락되었음”이라는 연속 프롬프트를 통해 LLM이 이러한 누락된 엔티티를 추가로 추출하도록 유도합니다.
이러한 접근 방식을 통해 품질 저하나 노이즈 도입 없이도 더 큰 청크 크기를 사용할 수 있게 됩니다. 이는 다음과 같은 수식으로 표현될 수 있습니다.
\[Q(c, g) = \sum_{i=1}^g E_i(c)\]여기서 \(Q(c, g)\)는 청크 크기 \(c\)와 글리닝 횟수 \(g\)에 대한 전체 추출 품질을 나타내며, \(E_i(c)\)는 \(i\)번째 글리닝 라운드에서의 엔티티 추출 성능을 나타냅니다.
엔티티 인스턴스에서 엔티티 요약으로의 변환
대규모 언어 모델(LLM)을 활용한 엔티티, 관계, 그리고 주장의 추출 과정은 그 자체로 추상적 요약의 한 형태입니다. 이는 텍스트에 명시적으로 언급되지 않았더라도 내포된 개념들을 LLM이 독립적으로 의미 있는 요약으로 생성할 수 있기 때문입니다. 예를 들어, 텍스트에 암시적으로 존재하는 관계성을 파악하여 명시적으로 표현할 수 있습니다.
이러한 인스턴스 수준의 요약들을 그래프의 각 요소(엔티티 노드, 관계 엣지, 주장 공변량)에 대한 단일 설명 블록으로 변환하기 위해서는 LLM을 통한 추가적인 요약 단계가 필요합니다. 이 과정은 다음과 같은 수학적 표현으로 나타낼 수 있습니다.
\[S(E) = \text{LLM}(\{i_1, i_2, ..., i_n\}) \text{ where } i_k \in I_E\]여기서 \(S(E)\)는 엔티티 \(E\)에 대한 최종 요약이며, \(I_E\)는 해당 엔티티와 관련된 모든 인스턴스 수준 요약의 집합입니다.
이 단계에서 발생할 수 있는 주요 우려사항은 LLM이 동일한 엔티티를 일관되지 않은 텍스트 형식으로 추출할 수 있다는 점입니다. 이로 인해 그래프에 중복된 엔티티 요소가 생성될 수 있습니다. 하지만 연구진은 이러한 문제에 대해 두 가지 측면에서 해결책을 제시합니다.
- 밀접하게 연관된 엔티티들의 “커뮤니티”가 다음 단계에서 탐지되고 요약됩니다.
- LLM은 서로 다른 이름 변형들 사이의 공통된 엔티티를 이해할 수 있습니다.
이러한 특성으로 인해, 모든 이름 변형들이 공통된 밀접 관련 엔티티 집합과 충분한 연결성을 가지고 있다면, 전체적인 접근 방식은 이러한 변형에 대해 견고성을 유지할 수 있습니다. 이는 다음과 같은 수식으로 표현될 수 있습니다.
\[C(v_1, v_2) = \frac{|N(v_1) \cap N(v_2)|}{|N(v_1) \cup N(v_2)|} > \theta\]여기서 \(C(v_1, v_2)\)는 두 이름 변형 \(v_1\)과 \(v_2\) 사이의 연결성 측도이며, \(N(v)\)는 노드 \(v\)의 이웃 집합, \(\theta\)는 연결성 임계값입니다.
이러한 접근 방식의 특징은 잠재적으로 노이즈가 있는 그래프 구조에서 동질적인 노드들에 대해 풍부한 설명 텍스트를 사용한다는 점입니다. 이는 LLM의 능력과 전역적, 쿼리 중심 요약의 요구사항에 모두 부합합니다. 또한 이러한 특성은 이 그래프 인덱스를 전통적인 지식 그래프와 차별화합니다. 전통적인 지식 그래프는 주로 간결하고 일관된 지식 트리플(주어, 술어, 목적어)에 의존하여 추론 작업을 수행하는 반면, 이 접근 방식은 더 풍부하고 유연한 텍스트 기반 표현을 활용합니다.
요소 요약에서 그래프 커뮤니티로의 변환
이전 단계에서 생성된 인덱스는 동종 무방향 가중 그래프(homogeneous undirected weighted graph)로 모델링될 수 있습니다. 이 그래프에서 엔티티 노드들은 관계 엣지로 연결되며, 엣지 가중치는 탐지된 관계 인스턴스의 정규화된 빈도를 나타냅니다. 이러한 그래프 구조에서 커뮤니티를 탐지하기 위해 다양한 알고리즘을 적용할 수 있는데, 이는 Fortunato와 Jin 등이 포괄적으로 정리한 바 있습니다.
연구진은 Leiden 알고리즘을 선택했는데, 이는 대규모 그래프의 계층적 커뮤니티 구조를 효율적으로 식별할 수 있기 때문입니다. Leiden 알고리즘은 모듈성(modularity) \(Q\)를 최적화하여 커뮤니티를 탐지합니다.
\[Q = \frac{1}{2m}\sum_{ij} \left(A_{ij} - \frac{k_i k_j}{2m}\right)\delta(c_i, c_j)\]여기서:
- \(A_{ij}\)는 인접 행렬의 원소
- \(k_i\)와 \(k_j\)는 각각 노드 \(i\)와 \(j\)의 차수
- \(m\)은 전체 엣지 수
- \(\delta(c_i, c_j)\)는 두 노드가 같은 커뮤니티에 속하는지를 나타내는 지시 함수입니다
Leiden 알고리즘은 다음과 같은 중요한 특성을 보장합니다.
- \(\gamma\)-분리(separation): 각 반복 후 모든 커뮤니티가 \(\gamma\)-분리되어 있음을 보장합니다.
- \(\gamma\)-연결성(connectivity): 각 반복 후 모든 커뮤니티가 \(\gamma\)-연결되어 있음을 보장합니다.
- 부분 파티션 \(\gamma\)-밀도(density): 안정적인 반복에서 모든 커뮤니티가 연결이 끊어지지 않은 부분으로 분할될 수 없음을 보장합니다.
이렇게 식별된 계층 구조의 각 레벨은 그래프의 노드들을 상호 배타적이면서도 전체를 포괄하는(mutually-exclusive, collective-exhaustive) 방식으로 커뮤니티들로 분할합니다. 이는 분할 정복(divide-and-conquer) 방식의 전역 요약을 가능하게 합니다.
그래프 커뮤니티에서 커뮤니티 요약으로
그래프 RAG 시스템의 다음 단계는 Leiden 계층 구조의 각 커뮤니티에 대해 보고서 형식의 요약을 생성하는 것입니다. 이 요약 생성 방법은 대규모 데이터셋에도 효과적으로 적용할 수 있도록 설계되었습니다. 이러한 커뮤니티 요약은 데이터셋의 전역적 구조와 의미를 이해하는 데 독립적으로도 유용하며, 질문 없이도 말뭉치를 이해하는 데 활용될 수 있습니다.
예를 들어, 사용자는 한 레벨의 커뮤니티 요약을 살펴보면서 관심 있는 일반적인 주제를 찾은 다음, 각 하위 주제에 대한 더 자세한 정보를 제공하는 하위 레벨의 보고서로 연결되는 링크를 따라갈 수 있습니다. 하지만 이 연구에서는 주로 전역적 쿼리에 답변하기 위한 그래프 기반 인덱스의 일부로서 이러한 커뮤니티 요약의 유용성에 초점을 맞추고 있습니다.
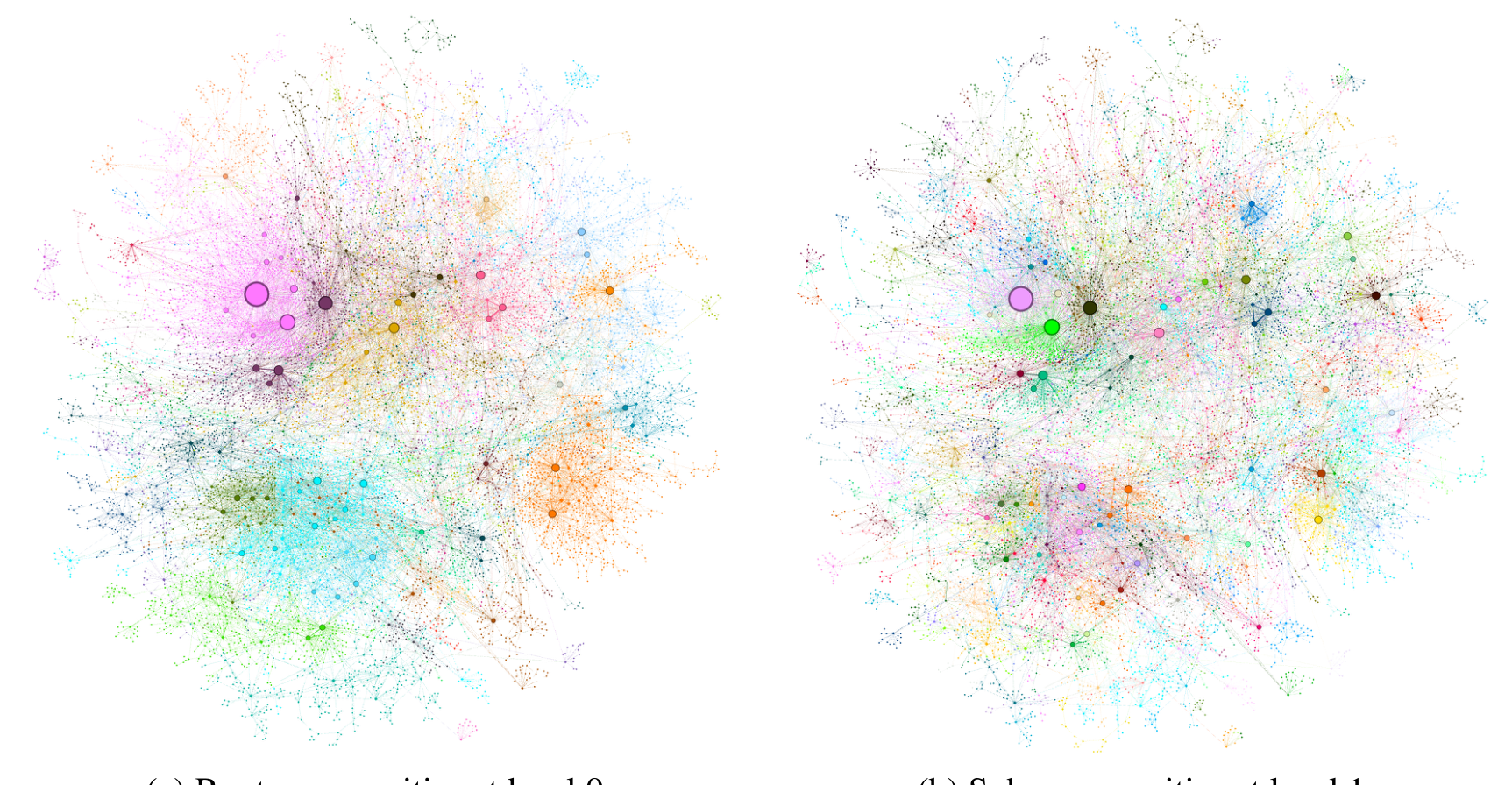
이 시각화는 MultiHop-RAG 데이터셋에서 Leiden 알고리즘을 사용하여 탐지된 그래프 커뮤니티를 보여줍니다. 원은 엔티티 노드를 나타내며, 크기는 노드의 차수에 비례합니다. 노드 레이아웃은 OpenORD와 Force Atlas 2 알고리즘을 사용하여 생성되었습니다. 노드 색상은 엔티티 커뮤니티를 나타내며, 두 가지 수준의 계층적 클러스터링을 보여줍니다. (a) 최대 모듈성을 가진 계층적 분할에 해당하는 레벨 0과 (b) 이러한 루트 레벨 커뮤니티 내의 내부 구조를 보여주는 레벨 1입니다.
커뮤니티 요약은 다음과 같은 방식으로 생성됩니다.
리프 레벨 커뮤니티의 경우, 요소 요약(노드, 엣지, 공변량)을 우선순위화한 다음 토큰 제한에 도달할 때까지 LLM 컨텍스트 윈도우에 반복적으로 추가합니다. 우선순위화는 다음과 같이 진행됩니다. 소스 노드와 타겟 노드의 결합 차수(즉, 전반적인 중요도)를 기준으로 내림차순으로 정렬된 각 커뮤니티 엣지에 대해, 소스 노드, 타겟 노드, 연결된 공변량, 그리고 엣지 자체에 대한 설명을 추가합니다.
상위 레벨 커뮤니티의 경우, 모든 요소 요약이 컨텍스트 윈도우의 토큰 제한 내에 들어가면 리프 레벨 커뮤니티와 동일한 방식으로 진행하여 커뮤니티 내의 모든 요소 요약을 요약합니다. 그렇지 않은 경우, 요소 요약 토큰을 기준으로 하위 커뮤니티를 내림차순으로 정렬하고, 컨텍스트 윈도우 내에 맞출 수 있을 때까지 하위 커뮤니티 요약(더 짧음)을 연관된 요소 요약(더 김)으로 반복적으로 대체합니다.
커뮤니티 요약에서 글로벌 답변으로
사용자의 쿼리가 주어지면, 이전 단계에서 생성된 커뮤니티 요약을 활용하여 다단계 프로세스를 통해 최종 답변을 생성합니다. 커뮤니티 구조의 계층적 특성으로 인해 다양한 수준의 커뮤니티 요약을 활용할 수 있으며, 이는 일반적인 의미 파악 질문에 대해 요약의 상세도와 범위 사이의 최적의 균형을 찾는 데 도움이 됩니다.
주어진 커뮤니티 레벨에 대해, 글로벌 답변은 다음과 같은 단계로 생성됩니다.
첫째, 커뮤니티 요약을 준비합니다. 이 과정에서 커뮤니티 요약은 무작위로 섞이고 사전 지정된 토큰 크기의 청크로 분할됩니다. 이는 관련 정보가 단일 컨텍스트 윈도우에 집중되어 손실되는 것을 방지하고, 대신 청크 전체에 고르게 분산되도록 보장합니다. 이 과정은 다음과 같은 수식으로 표현될 수 있습니다.
\[C = \{c_1, c_2, ..., c_n\} \text{ where } \text{size}(c_i) \leq T\]여기서 \(C\)는 분할된 청크의 집합이고, \(T\)는 최대 토큰 크기 제한입니다.
둘째, 커뮤니티 답변을 매핑합니다. 각 청크에 대해 병렬로 중간 답변을 생성합니다. 이때 대규모 언어 모델은 목표 질문에 대한 답변의 유용성을 0-100 사이의 점수로 평가하도록 요청받습니다. 점수가 0인 답변은 필터링됩니다. 이 과정은 다음과 같이 표현됩니다.
\[R_i = \text{LLM}(c_i, q) \text{ where } R_i = \{(a_i, s_i) | s_i > 0\}\]여기서 \(R_i\)는 청크 \(c_i\)에 대한 응답 집합이며, \(a_i\)는 생성된 답변, \(s_i\)는 해당 답변의 유용성 점수입니다.
셋째, 글로벌 답변으로 축소합니다. 중간 커뮤니티 답변들은 유용성 점수를 기준으로 내림차순 정렬되고, 토큰 제한에 도달할 때까지 새로운 컨텍스트 윈도우에 반복적으로 추가됩니다. 이 최종 컨텍스트는 사용자에게 반환될 글로벌 답변을 생성하는 데 사용됩니다.
\[G = \text{LLM}\left(\bigcup_{i=1}^k R_i, q\right) \text{ where } k = \arg\max_j \left\{\sum_{i=1}^j \text{tokens}(R_i) \leq T\right\}\]여기서 \(G\)는 최종 글로벌 답변이며, \(k\)는 토큰 제한 \(T\)를 초과하지 않는 최대 응답 수입니다. 이러한 다단계 답변 생성 프로세스의 구현은 Microsoft Research의 연구진이 개발한 그래프 RAG 시스템의 핵심 요소입니다. 이 시스템은 대규모 언어 모델의 컨텍스트 처리 한계를 극복하고 더 포괄적인 답변을 생성하기 위해 정교한 매핑-축소(map-reduce) 아키텍처를 활용합니다.
매핑 단계에서는 각 커뮤니티 요약 청크가 독립적으로 처리되며, 이는 다음과 같은 프롬프트 템플릿을 통해 구현됩니다.
MAP_SYSTEM_PROMPT = """
주어진 컨텍스트를 기반으로 질문에 답변하고, 각 답변의 유용성을 평가하세요.
응답 형식:
{
"points": [
{
"description": "답변 내용",
"score": "유용성 점수 (0-100)"
}
]
}
"""
이때 유용성 점수는 답변의 관련성과 품질을 종합적으로 평가하며, Liu와 연구진이 제안한 “중간 손실(lost in the middle)” 현상을 완화하기 위해 각 청크의 정보가 독립적으로 평가됩니다.
축소 단계에서는 점수화된 중간 답변들이 통합되는데, 이 과정은 다음과 같은 최적화 문제로 정식화됩니다.
\[\max_{S \subseteq R} \sum_{r \in S} \text{score}(r) \text{ subject to } \sum_{r \in S} \text{tokens}(r) \leq T\]여기서 \(R\)은 모든 중간 답변의 집합이고, \(S\)는 선택된 답변들의 부분집합입니다. 이 최적화는 탐욕 알고리즘(greedy algorithm)을 통해 해결되며, 점수가 높은 답변부터 순차적으로 선택하여 토큰 제한을 만족시킵니다.
최종 답변 생성 시에는 Shao와 연구진이 제안한 반복적 검색-생성 시너지(Iterative Retrieval-Generation Synergy) 개념이 적용되어, 선택된 중간 답변들이 하나의 응집력 있는 글로벌 답변으로 통합됩니다. 이 과정에서는 답변의 포괄성(comprehensiveness), 다양성(diversity), 그리고 권한 부여(empowerment)라는 세 가지 품질 지표가 고려됩니다.
시스템은 또한 일반 지식 통합을 위한 선택적 메커니즘을 제공합니다. 데이터셋에서 충분한 관련 정보를 찾지 못한 경우, 대규모 언어 모델의 사전 학습된 지식을 활용하여 답변을 보완할 수 있습니다. 이는 다음과 같은 프롬프트를 통해 구현됩니다.
GENERAL_KNOWLEDGE_INSTRUCTION = """
데이터셋의 정보가 불충분한 경우, 관련된 일반 지식을 활용하여 답변을 보완하되,
명확히 데이터셋 외부의 지식임을 표시하세요.
"""
평가
데이터셋
연구진은 실제 사용자들이 접할 수 있는 텍스트 말뭉치의 특성을 대표할 수 있는 약 100만 토큰 규모(약 10개의 소설에 해당하는 분량)의 두 가지 데이터셋을 선정했습니다.
첫 번째 데이터셋은 Microsoft CTO인 Kevin Scott와 다른 기술 리더들 간의 팟캐스트 대화 내용을 전사한 텍스트입니다(Behind the Tech). 이 데이터셋은 1,669개의 600토큰 크기 텍스트 청크로 구성되어 있으며, 각 청크 간에는 100토큰의 중첩이 있습니다. 전체 데이터셋의 크기는 약 100만 토큰입니다.
두 번째 데이터셋은 2013년 9월부터 2023년 12월까지 발행된 뉴스 기사들로 구성된 벤치마크 데이터셋입니다(MultiHop-RAG). 엔터테인먼트, 비즈니스, 스포츠, 기술, 건강, 과학 등 다양한 카테고리의 기사들을 포함하고 있습니다. 이 데이터셋은 3,197개의 600토큰 크기 텍스트 청크로 구성되어 있으며, 역시 청크 간에 100토큰의 중첩이 있습니다. 전체 데이터셋의 크기는 약 170만 토큰입니다.
쿼리
HotpotQA, MultiHop-RAG, MT-Bench와 같은 오픈 도메인 질의응답을 위한 다양한 벤치마크 데이터셋이 존재합니다. 하지만 이러한 데이터셋들의 질문들은 데이터 의미 파악(sensemaking)을 위한 요약이 아닌, 명시적인 사실 검색에 초점을 맞추고 있습니다. 여기서 데이터 의미 파악이란 Koesten과 연구진이 정의한 바와 같이, 사람들이 실제 활동의 더 넓은 맥락 안에서 데이터를 검사하고, 상호작용하며, 맥락화하는 과정을 의미합니다.
비슷하게, Xu와 Lapata가 제안한 것처럼 소스 텍스트에서 잠재적 요약 쿼리를 추출하는 방법들도 존재하지만, 이러한 추출된 질문들은 텍스트에 대한 사전 지식을 전제로 하는 세부사항을 대상으로 할 수 있습니다. RAG 시스템의 전역적 의미 파악 작업에 대한 효과성을 평가하기 위해서는, 특정 텍스트의 세부사항이 아닌 데이터셋 내용에 대한 높은 수준의 이해만을 전달하는 질문들이 필요합니다.
연구진은 이러한 질문들을 자동으로 생성하기 위해 활동 중심 접근법을 사용했습니다. 데이터셋에 대한 간단한 설명이 주어지면, LLM에게 N명의 잠재적 사용자와 사용자당 N개의 작업을 식별하도록 요청합니다. 그런 다음 각 (사용자, 작업) 조합에 대해, LLM에게 전체 말뭉치의 이해를 필요로 하는 N개의 질문을 생성하도록 요청합니다. 이 평가에서는 N=5를 사용하여 데이터셋당 125개의 테스트 질문을 생성했습니다.
실험 조건
연구진은 분석에서 6가지 조건을 비교했습니다. 여기에는 4개 수준의 그래프 커뮤니티를 사용하는 Graph RAG(C0, C1, C2, C3), 맵-리듀스 접근법을 소스 텍스트에 직접 적용하는 텍스트 요약 방법(TS), 그리고 기본적인 “시맨틱 검색” RAG 접근법(SS)이 포함됩니다.
- C0: 루트 레벨 커뮤니티 요약(가장 적은 수)을 사용하여 사용자 쿼리에 답변
- C1: 상위 레벨 커뮤니티 요약을 사용. C0의 하위 커뮤니티가 있는 경우 이를 사용하고, 없는 경우 C0 커뮤니티를 투영
- C2: 중간 레벨 커뮤니티 요약을 사용. C1의 하위 커뮤니티가 있는 경우 이를 사용하고, 없는 경우 C1 커뮤니티를 투영
- C3: 하위 레벨 커뮤니티 요약(가장 많은 수)을 사용. C2의 하위 커뮤니티가 있는 경우 이를 사용하고, 없는 경우 C2 커뮤니티를 투영
- TS: 2.6절에서 설명한 것과 동일한 방법을 사용하되, 커뮤니티 요약 대신 소스 텍스트를 섞고 청크로 나누어 맵-리듀스 요약 단계에 사용
- SS: 텍스트 청크를 검색하여 지정된 토큰 제한에 도달할 때까지 사용 가능한 컨텍스트 윈도우에 추가하는 기본적인 RAG 구현
모든 6가지 조건에서 컨텍스트 윈도우의 크기와 답변 생성에 사용되는 프롬프트는 동일했습니다(컨텍스트 정보 유형에 맞게 참조 스타일을 약간 수정한 것 제외). 조건들은 오직 컨텍스트 윈도우의 내용이 어떻게 생성되는지에서만 차이가 있었습니다.
C0-C3 조건을 지원하는 그래프 인덱스는 엔티티와 관계 추출을 위한 일반적인 프롬프트만을 사용하여 생성되었으며, 엔티티 유형과 퓨 샷 예제는 데이터의 도메인에 맞게 조정되었습니다. 그래프 인덱싱 과정에서는 팟캐스트 데이터셋의 경우 1회의 글리닝(gleaning)을, 뉴스 데이터셋의 경우 0회의 글리닝을 사용하여 600토큰의 컨텍스트 윈도우 크기를 적용했습니다.
평가
평가 지표
대규모 언어 모델은 자연어 생성의 평가에서 뛰어난 성능을 보여왔으며, Wang과 연구진, 그리고 Zheng과 연구진의 연구에 따르면 인간 평가와 비교했을 때 최신 기술 수준 또는 경쟁력 있는 결과를 달성할 수 있습니다. 이러한 LLM 기반 평가 방식은 정답이 알려진 경우 참조 기반 메트릭을 생성할 수 있을 뿐만 아니라, Wang과 연구진이 보여준 것처럼 참조 없이도 생성된 텍스트의 품질(예: 유창성)을 측정하거나, Zheng과 연구진이 제안한 것처럼 경쟁하는 출력들을 직접 비교(LLM-as-a-judge)할 수 있습니다.
또한 Es와 연구진이 개발한 RAGAS와 같이, LLM은 기존 RAG 시스템의 성능을 평가하는 데도 유망한 결과를 보여주었으며, 컨텍스트 관련성, 충실도, 답변 관련성과 같은 품질을 자동으로 평가할 수 있습니다.
연구진은 Graph RAG 메커니즘의 다단계 특성, 비교하고자 하는 여러 조건들, 그리고 활동 기반 의미 파악 질문에 대한 정답이 없다는 점을 고려하여, LLM 평가자를 사용한 일대일 비교 접근법을 채택했습니다. 의미 파악 활동에 바람직한 품질을 포착하는 세 가지 목표 메트릭과 함께 타당성 지표로 사용되는 하나의 제어 메트릭(직접성)을 선택했습니다. 직접성은 본질적으로 포괄성과 다양성에 반대되는 특성이므로, 어떤 방법도 모든 네 가지 메트릭에서 우수한 성능을 보이지는 않을 것으로 예상됩니다.
LLM 평가자를 사용한 일대일 비교 메트릭은 다음과 같습니다.
-
포괄성(Comprehensiveness): 답변이 질문의 모든 측면과 세부사항을 다루는 데 얼마나 많은 상세 정보를 제공하는가?
-
다양성(Diversity): 답변이 질문에 대한 서로 다른 관점과 통찰을 제공하는 데 있어 얼마나 다양하고 풍부한가?
-
권한 부여(Empowerment): 답변이 독자가 주제를 이해하고 정보에 기반한 판단을 내리는 데 얼마나 잘 도움을 주는가?
-
직접성(Directness): 답변이 얼마나 구체적이고 명확하게 질문을 다루는가?
평가 과정에서 LLM에게는 질문, 목표 메트릭, 그리고 한 쌍의 답변이 제공되며, 메트릭에 따라 어떤 답변이 더 나은지 평가하고 그 이유를 설명하도록 요청됩니다. LLM은 승자가 있는 경우 승자를 반환하고, 두 답변이 근본적으로 유사하고 차이가 무시할 만한 수준인 경우 동점을 반환합니다. LLM의 확률적 특성을 고려하여, 각 비교는 5회 실행되어 평균 점수를 사용합니다.
구성 및 실험 설정
연구진은 실험에서 컨텍스트 윈도우 크기가 특정 작업에 미치는 영향을 면밀히 조사했습니다. 특히 gpt-4-turbo와 같이 128k 토큰의 큰 컨텍스트 크기를 가진 모델에서도, Kuratov와 연구진, 그리고 Liu와 연구진이 발견한 “중간 손실(lost in the middle)” 현상으로 인해 긴 컨텍스트에서 정보가 손실될 수 있다는 점을 고려했습니다. 이에 따라 연구진은 데이터셋, 질문, 메트릭의 조합에 대해 컨텍스트 윈도우 크기를 변화시키며 그 효과를 탐구했습니다.
특히 기준 조건(SS)에 대한 최적의 컨텍스트 크기를 결정하고 이를 모든 쿼리 시점 LLM 사용에 균일하게 적용하는 것을 목표로 했습니다. 이를 위해 8k, 16k, 32k, 64k의 네 가지 컨텍스트 윈도우 크기를 테스트했습니다. 흥미롭게도, 테스트한 가장 작은 컨텍스트 윈도우 크기(8k)가 모든 비교에서 포괄성 측면에서 보편적으로 더 나은 성능을 보였습니다(평균 승률 58.1%). 또한 다양성(평균 승률 52.4%)과 권한 부여(평균 승률 51.3%) 측면에서도 더 큰 컨텍스트 크기와 비슷한 성능을 보였습니다. 연구진은 더 포괄적이고 다양한 답변에 대한 선호도를 고려하여 최종 평가에서 8k 토큰의 고정된 컨텍스트 윈도우 크기를 사용했습니다.
실험 결과
인덱싱 과정은 팟캐스트 데이터셋에서 8,564개의 노드와 20,691개의 엣지로 구성된 그래프를, 뉴스 데이터셋에서는 15,754개의 노드와 19,520개의 엣지로 구성된 더 큰 그래프를 생성했습니다. 각 그래프 커뮤니티 계층의 다양한 레벨에서 생성된 커뮤니티 요약의 수는 다음과 같은 특징을 보입니다.
팟캐스트 데이터셋의 경우:
- C0: 34개 유닛 (26,657 토큰, 최대의 2.6%)
- C1: 367개 유닛 (22,575 토큰, 최대의 22.2%)
- C2: 969개 유닛 (65,720 토큰, 최대의 65.8%)
- C3: 1,310개 유닛 (74,610 토큰, 최대의 73.5%)
- TS: 1,669개 유닛 (101,014 토큰, 최대의 100%)
뉴스 데이터셋의 경우:
- C0: 55개 유닛 (39,770 토큰, 최대의 2.3%)
- C1: 555개 유닛 (35,264 토큰, 최대의 20.7%)
- C2: 1,972개 유닛 (98,089 토큰, 최대의 57.4%)
- C3: 1,423개 유닛 (114,026 토큰, 최대의 66.8%)
- TS: 3,197개 유닛 (170,769 토큰, 최대의 100%)
이러한 결과는 소스 텍스트의 맵-리듀스 요약이 가장 많은 컨텍스트 토큰을 필요로 하는 리소스 집약적인 접근법임을 보여줍니다. 반면 루트 레벨 커뮤니티 요약(C0)은 쿼리당 필요한 토큰이 크게 감소하여(9배에서 43배까지) 효율적인 처리가 가능합니다. 실험 결과를 자세히 살펴보면, 전역적 접근법과 기본적인 RAG 방식을 비교했을 때 흥미로운 패턴이 발견됩니다. 전역적 접근법들은 두 데이터셋 모두에서 포괄성과 다양성 메트릭에서 기본적인 RAG(SS) 접근법을 일관되게 능가했습니다. 구체적으로, 팟캐스트 전사본 데이터셋에서는 포괄성 승률이 72-83%, 다양성 승률이 75-82%를 기록했습니다. 뉴스 기사 데이터셋에서도 비슷한 패턴이 관찰되어 포괄성 승률이 72-80%, 다양성 승률이 62-71%를 기록했습니다.
연구진이 타당성 검증을 위해 사용한 직접성 메트릭에서도 예상된 결과가 확인되었습니다. 기본적인 RAG가 모든 비교에서 가장 직접적인 응답을 생성했는데, 이는 지역적 컨텍스트에 집중하는 접근법의 특성을 잘 반영합니다.
커뮤니티 요약과 소스 텍스트를 비교했을 때, Graph RAG의 커뮤니티 요약은 루트 레벨을 제외하고 일반적으로 답변의 포괄성과 다양성에서 작지만 일관된 개선을 보여주었습니다. 팟캐스트 데이터셋에서는 중간 레벨 요약이 57%의 포괄성 승률과 57%의 다양성 승률을 달성했으며, 뉴스 데이터셋에서는 하위 레벨 커뮤니티 요약이 각각 64%와 60%의 승률을 기록했습니다.
특히 주목할 만한 점은 Graph RAG의 확장성 이점입니다. 하위 레벨 커뮤니티 요약(C3)의 경우 소스 텍스트 요약보다 26-33% 더 적은 컨텍스트 토큰을 필요로 했으며, 루트 레벨 커뮤니티 요약(C0)의 경우에는 97% 이상 더 적은 토큰을 필요로 했습니다. 이는 다른 전역적 방법들과 비교했을 때 성능 저하가 크지 않으면서도, 의미 파악 활동에서 특징적인 반복적 질문 응답에 매우 효율적인 방법을 제공합니다. 실제로 루트 레벨 Graph RAG는 기본적인 RAG 대비 여전히 포괄성에서 72%, 다양성에서 62%의 승률을 유지했습니다.
권한 부여 메트릭에 대한 비교 결과는 다소 혼재된 양상을 보였습니다. 기본적인 RAG(SS)와 비교한 전역적 접근법들의 성능, 그리고 소스 텍스트 요약(TS)과 비교한 Graph RAG 접근법들의 성능 모두 명확한 우위를 보이지 않았습니다. LLM의 평가 근거를 분석한 결과, 구체적인 예시, 인용구, 그리고 출처 제시 능력이 사용자가 정보에 기반한 이해에 도달하는 데 핵심적인 것으로 판단되었습니다. 연구진은 Graph RAG 인덱스에서 이러한 세부사항들을 더 잘 보존하기 위해 요소 추출 프롬프트를 조정하는 것이 도움이 될 수 있다고 제안했습니다.
관련 연구
RAG 접근법과 시스템
검색 증강 생성(Retrieval-Augmented Generation, RAG)은 대규모 언어 모델(LLM)을 사용할 때 외부 데이터 소스에서 관련 정보를 먼저 검색한 후, 이를 원래 쿼리와 함께 LLM의 컨텍스트 윈도우에 추가하는 방식으로 작동합니다. Gao와 연구진이 설명한 기본적인 RAG 접근법은 문서를 텍스트로 변환하고, 이를 청크로 분할한 뒤, 이러한 청크들을 의미적으로 유사한 위치가 유사한 의미를 나타내는 벡터 공간에 임베딩하는 방식을 사용합니다. 쿼리는 동일한 벡터 공간에 임베딩되며, 가장 가까운 k개의 벡터에 해당하는 텍스트 청크들이 컨텍스트로 사용됩니다.
더 발전된 RAG 시스템들은 사전 검색, 검색, 사후 검색 전략을 포함하여 기본적인 RAG의 한계를 극복하고자 하며, 모듈형 RAG 시스템들은 검색과 생성이 교차되는 반복적이고 동적인 사이클을 위한 패턴들을 포함합니다. 본 연구의 그래프 RAG 구현은 다른 시스템들과 관련된 여러 개념들을 통합했습니다. 예를 들어, 커뮤니티 요약은 Cheng과 연구진이 제안한 자체 메모리(Selfmem)의 한 형태로, Mao와 연구진이 연구한 생성 증강 검색(Generation-Augmented Retrieval, GAR)을 통해 향후 생성 사이클을 용이하게 합니다. 또한 이러한 요약들로부터 커뮤니티 답변을 병렬로 생성하는 것은 Shao와 연구진이 제안한 반복적(Iter-RetGen) 또는 Wang과 연구진이 연구한 연합형(FeB4RAG) 검색-생성 전략의 한 형태입니다.
다른 시스템들도 이러한 개념들을 다중 문서 요약(Su와 연구진의 CAiRE-COVID)과 다중 홉 질의응답(Feng과 연구진의 ITRG, Trivedi와 연구진의 IR-CoT, Khattab과 연구진의 DSP)을 위해 결합했습니다. 본 연구의 계층적 인덱스와 요약 사용은 텍스트 청크의 벡터를 클러스터링하여 계층적 인덱스를 생성하는 Sarthi와 연구진의 RAPTOR나, Kim과 연구진이 제안한 모호한 질문의 여러 해석에 답하기 위한 “명확화 트리” 생성과 같은 다른 접근법들과도 유사점이 있습니다. 하지만 이러한 반복적이거나 계층적인 접근법들 중 어느 것도 그래프 RAG를 가능하게 하는 자체 생성 그래프 인덱스를 사용하지는 않습니다.
그래프와 LLM
LLM과 RAG와 관련된 그래프 활용은 여러 방향으로 발전하고 있는 연구 분야입니다. 여기에는 Trajanoska와 연구진이 연구한 지식 그래프 생성과 Yao와 연구진이 연구한 지식 그래프 완성, 그리고 Ban과 연구진, Zhang과 연구진이 연구한 소스 텍스트로부터의 인과 그래프 추출이 포함됩니다. 또한 Gao와 연구진이 제시한 고급 RAG의 형태로, Baek과 연구진의 KAPING과 같이 인덱스가 지식 그래프인 경우, He와 연구진의 G-Retriever와 같이 그래프 구조의 부분집합이나 Zhang의 GraphToolFormer와 같이 도출된 그래프 메트릭이 조회 대상인 경우, Kang과 연구진의 SURGE와 같이 검색된 서브그래프의 사실에 강하게 근거한 내러티브 출력을 생성하는 경우, Ranade와 Joshi의 FABULA와 같이 검색된 이벤트-플롯 서브그래프를 내러티브 템플릿을 사용하여 직렬화하는 경우, 그리고 Wang과 연구진이 연구한 것처럼 다중 홉 질의응답을 위한 텍스트-관계 그래프의 생성과 탐색을 모두 지원하는 경우가 있습니다.
오픈소스 소프트웨어 측면에서는 LangChain과 LlamaIndex 라이브러리에서 다양한 그래프 데이터베이스를 지원하며, Neo4J의 NaLLM과 NebulaGraph의 GraphRAG를 포함하여 더 일반적인 그래프 기반 RAG 애플리케이션들도 등장하고 있습니다. 하지만 본 연구의 그래프 RAG 접근법과 달리, 이러한 시스템들 중 어느 것도 전역 요약을 위해 그래프의 자연스러운 모듈성을 활용하여 데이터를 분할하지는 않습니다.
논의 및 한계점
본 연구의 평가 접근법에는 몇 가지 중요한 한계점이 있습니다. 우선, 현재까지의 평가는 약 100만 토큰 규모의 두 코퍼스에 대해 특정 유형의 의미 파악 질문들만을 검토했습니다. 다양한 질문 유형, 데이터 유형, 그리고 데이터셋 크기에 따른 성능 변화를 더 깊이 이해하기 위해서는 추가적인 연구가 필요합니다. 또한 의미 파악 질문들과 목표 메트릭의 타당성을 최종 사용자들과 함께 검증하는 작업도 필요합니다.
현재 분석의 개선을 위해 Manakul과 연구진이 개발한 SelfCheckGPT와 같은 접근법을 활용하여 답변 생성 과정에서 발생하는 허위 정보(fabrication) 비율을 비교하는 것이 도움이 될 수 있습니다. SelfCheckGPT는 대규모 언어 모델의 출력에서 허위 정보를 탐지하기 위한 제로 리소스 방식을 제공하며, 이는 그래프 RAG 시스템의 신뢰성을 더욱 향상시키는 데 기여할 수 있습니다.
그래프 인덱스 구축과 관련된 트레이드오프도 중요한 고려사항입니다. 실험에서 그래프 RAG는 다른 방법들과의 일대일 비교에서 일관되게 가장 우수한 결과를 보여주었지만, 많은 경우에 그래프를 사용하지 않는 소스 텍스트의 전역 요약 접근법도 경쟁력 있는 성능을 보였습니다. 실제 환경에서 그래프 인덱스 구축 여부를 결정할 때는 여러 요소를 고려해야 합니다.
- 컴퓨팅 예산: 그래프 구축과 유지보수에 필요한 컴퓨팅 리소스
- 데이터셋당 예상되는 평생 쿼리 수: 구축 비용 대비 활용도
- 그래프 인덱스의 다른 측면에서 얻을 수 있는 가치: 일반적인 커뮤니티 요약과 다른 그래프 관련 RAG 접근법의 활용 가능성
향후 연구 방향과 관련하여, 현재의 그래프 RAG 접근법을 지원하는 그래프 인덱스, 풍부한 텍스트 주석, 그리고 계층적 커뮤니티 구조는 다양한 개선과 적용 가능성을 제공합니다. 예를 들어, 사용자 쿼리와 그래프 주석 간의 임베딩 기반 매칭을 통해 더 지역적으로 작동하는 RAG 접근법을 개발할 수 있습니다. 또한 맵-리듀스 요약 메커니즘을 적용하기 전에 커뮤니티 보고서에 대한 임베딩 기반 매칭을 결합하는 하이브리드 RAG 방식도 가능합니다.
이러한 “롤업” 작업은 커뮤니티 계층의 더 많은 레벨로 확장될 수 있으며, 상위 레벨 커뮤니티 요약에 포함된 정보의 흐름을 따라가는 탐색적인 “드릴 다운” 메커니즘으로도 구현될 수 있습니다. 이는 Liu와 연구진이 지적한 “중간 손실” 현상을 완화하면서도 효과적인 정보 탐색을 가능하게 할 것입니다.
결론
이 연구는 전체 텍스트 말뭉치에 대한 글로벌 접근법으로서 그래프 RAG를 제시했습니다. 지식 그래프 생성, 검색 증강 생성(RAG), 그리고 쿼리 중심 요약(QFS)을 결합하여 사용자의 데이터 의미 파악을 지원하는 혁신적인 방법론을 개발했습니다. 초기 평가 결과는 기본적인 RAG 방식과 비교했을 때 답변의 포괄성과 다양성 측면에서 상당한 개선을 보여주었으며, 맵-리듀스 소스 텍스트 요약을 사용하는 그래프가 없는 글로벌 접근법과 비교해도 경쟁력 있는 성능을 달성했습니다.
특히 동일한 데이터셋에 대해 여러 번의 글로벌 쿼리가 필요한 상황에서, 엔티티 기반 그래프 인덱스의 루트 레벨 커뮤니티 요약은 기본적인 RAG보다 우수하면서도 다른 글로벌 방법들과 비교할 때 토큰 비용을 크게 절감할 수 있는 데이터 인덱스를 제공합니다. 이는 Fortunato와 연구진이 제안한 그래프의 모듈성을 효과적으로 활용한 결과입니다.
연구진은 글로벌 및 로컬 그래프 RAG 접근법에 대한 파이썬 기반 오픈소스 구현을 Github에서 공개할 예정입니다. 이는 He와 연구진이 개발한 G-Retriever와 같은 기존의 그래프 기반 RAG 시스템들을 보완하고 확장하는 중요한 기여가 될 것으로 기대됩니다.
이 연구는 Shao와 연구진이 제안한 반복적 검색-생성 시너지의 개념을 그래프 도메인으로 확장하고, Kim과 연구진의 트리 기반 접근법을 커뮤니티 구조에 적용함으로써, 대규모 텍스트 말뭉치에 대한 더욱 효과적이고 효율적인 의미 파악 방법을 제시했습니다. 특히 Baumel과 연구진이 연구한 쿼리 중심 요약의 한계를 그래프 기반 접근법으로 극복하여, 더욱 포괄적이고 다양한 답변을 생성할 수 있게 되었습니다.
References
Subscribe via RSS