DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
by DeepSeek-AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
최근 코드 생성과 이해를 위한 대규모 언어 모델의 발전이 가속화되고 있으나, 대부분의 강력한 코드 생성 모델들이 비공개로 운영되어 연구와 발전이 제한되어 왔습니다. 특히 OpenAI의 Codex나 GPT 시리즈와 같은 비공개 모델들은 뛰어난 성능을 보여주지만, 연구 커뮤니티가 접근하기 어려운 상황이었습니다. 이러한 한계를 극복하고 코드 지능 분야의 발전을 가속화하기 위해 DeepSeek-Coder 연구가 시작되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
DeepSeek-Coder는 크게 세 가지 혁신적인 접근 방식을 제시합니다. 첫째, 저장소 수준의 데이터 구성을 도입하여 프로젝트 전체 컨텍스트 내에서 코드를 이해하고 생성하는 능력을 향상시켰습니다. 둘째, Fill-In-Middle(FIM) 학습 전략을 사전 학습 단계에서 적용하여 코드 완성 능력을 강화했습니다. 셋째, 16K 컨텍스트 윈도우를 도입하여 더 긴 코드 시퀀스를 효과적으로 처리할 수 있게 했습니다.
제안된 방법은 어떻게 구현되었습니까?
DeepSeek-Coder는 1.3B부터 33B 파라미터에 이르는 다양한 규모의 모델로 구현되었으며, 2조 개의 토큰으로 학습되었습니다. 학습 데이터는 소스 코드 87%, 영어 코드 관련 자연어 말뭉치 10%, 중국어 자연어 말뭉치 3%로 구성되었습니다. 특히 데이터 품질 관리를 위해 엄격한 필터링 규칙을 적용했으며, 의존성 파싱과 저장소 수준의 중복 제거 등 체계적인 데이터 처리 과정을 거쳤습니다. 또한 DeepSeek-Coder-v1.5에서는 자연어 이해와 수학적 추론 능력을 향상시키기 위해 추가적인 사전 학습을 진행했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
DeepSeek-Coder는 여러 벤치마크에서 기존 오픈소스 코드 모델들을 능가하는 성능을 보여주었으며, 특히 DeepSeek-Coder-Instruct 33B는 GPT-3.5 Turbo의 성능을 뛰어넘는 결과를 달성했습니다. 더욱 주목할 만한 점은 6.7B 규모의 모델이 34B 파라미터를 가진 CodeLlama와 대등한 성능을 보여주어, 효율적인 학습 전략과 고품질 데이터의 중요성을 입증했다는 것입니다. 이러한 성과는 코드 지능 분야에서 오픈소스 모델의 새로운 기준을 제시했으며, 학계와 산업계 모두에서 활용 가능한 강력한 도구를 제공했다는 점에서 큰 의의를 가집니다.
DeepSeek-Coder: 코드 지능의 부상과 대규모 언어 모델의 만남
DeepSeek-AI에서 개발한 DeepSeek-Coder는 프로그래밍 분야에서 대규모 언어 모델(Large Language Model, LLM)의 새로운 지평을 여는 혁신적인 연구입니다. 이 연구는 Guo와 Zhu를 주축으로 하는 연구진이 DeepSeek-AI와 북경대학교 HCST 연구실의 협력을 통해 진행되었습니다.
최근 Code Llama와 StarCoder 등의 연구에서 보여준 것처럼, 대규모 언어 모델을 코드 생성과 이해에 활용하는 것은 소프트웨어 개발 분야에서 큰 주목을 받고 있습니다. DeepSeek-Coder는 이러한 흐름을 한 단계 더 발전시켜, 코드 지능(Code Intelligence)이라는 새로운 패러다임을 제시합니다.
DeepSeek-Coder의 개발은 DeepSeek LLM의 연구에서 확립된 스케일링 법칙(scaling laws)을 기반으로 하고 있습니다. 이 모델은 대규모 코드 데이터셋에 대한 학습을 통해, 프로그래밍 작업에서 뛰어난 성능을 보여주는 것을 목표로 합니다. 특히 GitHub를 통해 공개된 소스 코드를 활용하여, 다양한 프로그래밍 언어와 개발 패러다임을 포괄하는 범용적인 코드 이해 및 생성 능력을 갖추고 있습니다.
이 연구의 소스 코드와 모델은 GitHub를 통해 공개되어 있어, 연구 커뮤니티와 개발자들이 직접 활용하고 발전시킬 수 있습니다. 이는 코드 지능 분야의 발전을 가속화하고, 오픈 소스 생태계를 통한 협력적 혁신을 촉진하는데 기여할 것으로 기대됩니다.
DeepSeek-Coder: 코드 지능의 새로운 지평
대규모 언어 모델의 급속한 발전은 소프트웨어 개발 분야에서 코드 지능의 혁신을 이끌어왔습니다. 그러나 현재까지 대부분의 강력한 코드 생성 모델들이 비공개 소스로 운영되어 왔기 때문에, 이 분야의 광범위한 연구와 발전이 제한되어 왔습니다. 이러한 한계를 극복하고자 연구진은 DeepSeek-Coder 시리즈를 소개합니다.
DeepSeek-Coder는 1.3B부터 33B 파라미터에 이르는 다양한 규모의 오픈소스 코드 모델들로 구성되어 있으며, 2조 개의 토큰으로 처음부터 학습되었습니다. 이 모델들은 고품질의 프로젝트 수준 코드 말뭉치를 기반으로 사전 학습되었으며, 16K 윈도우를 가진 빈칸 채우기(fill-in-the-blank) 작업을 통해 코드 생성과 채우기 능력을 향상시켰습니다.
아래 그림은 LeetCode 주간 코딩 대회에서 다양한 AI/ML 모델들의 성능을 비교한 결과를 보여줍니다. 레이더 차트를 통해 Python과 JavaScript가 C++, PHP, TypeScript 등 다른 프로그래밍 언어들보다 전반적으로 우수한 성능을 보이는 것을 확인할 수 있습니다. 하단의 선 그래프는 여러 DeepSeek-Coder 모델들의 성능을 보여주며, 특히 GPT-4-Turbo 변형 모델이 가장 높은 점수를 달성했음을 보여줍니다.
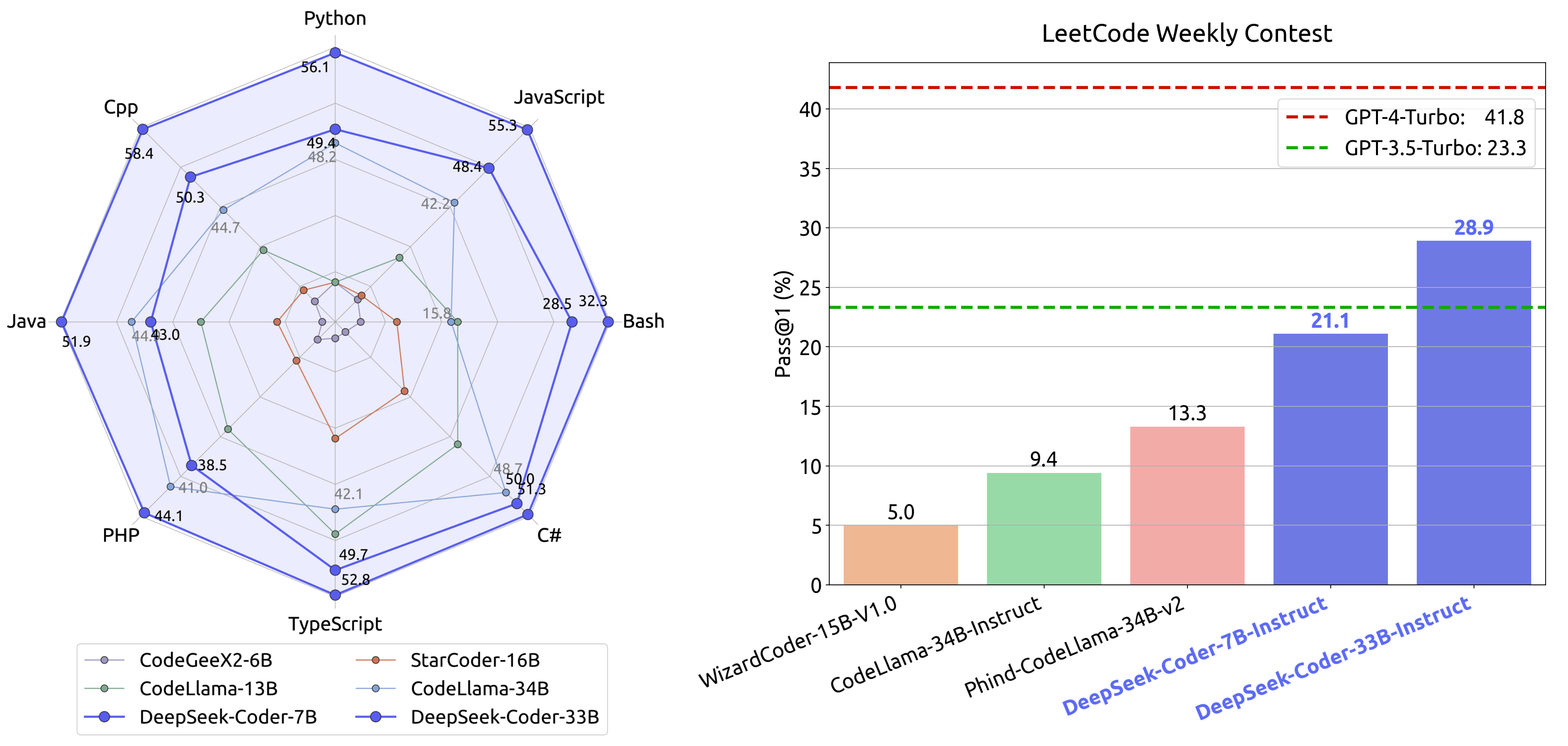
연구진의 광범위한 평가 결과에 따르면, DeepSeek-Coder는 여러 벤치마크에서 기존의 오픈소스 코드 모델들을 능가하는 성능을 보여주었을 뿐만 아니라, Codex와 GPT-3.5와 같은 비공개 모델들의 성능도 뛰어넘었습니다. 특히 주목할 만한 점은 DeepSeek-Coder-Base 7B 모델이 CodeLlama-33B와 같은 5배 더 큰 모델들과 비교해도 경쟁력 있는 성능을 보여주었다는 것입니다.
더욱이 DeepSeek-Coder 모델들은 연구와 상업적 사용 모두를 허용하는 관대한 라이선스 하에 공개되어 있어, 학계와 산업계 모두에서 자유롭게 활용할 수 있습니다. 이는 코드 지능 분야의 발전을 가속화하고, 더 많은 혁신을 이끌어낼 수 있는 기반을 마련했다는 점에서 큰 의의가 있습니다.
소프트웨어 개발의 새로운 시대
소프트웨어 개발 분야는 대규모 언어 모델의 급속한 발전으로 인해 큰 변화를 겪고 있습니다. Touvron과 연구진, OpenAI 등이 개발한 언어 모델들은 버그 감지부터 코드 생성에 이르기까지 다양한 코딩 작업을 자동화하고 간소화하는 데 큰 잠재력을 보여주고 있습니다. 이는 개발자의 생산성을 향상시키고 인적 오류의 가능성을 줄이는 데 크게 기여하고 있습니다.
그러나 이 분야에서 가장 큰 도전 과제는 오픈소스 모델과 비공개 모델 간의 성능 격차입니다. Roziere와 연구진, Li와 연구진, Nijkamp과 연구진, Wang과 연구진 등이 개발한 오픈소스 모델들은 OpenAI와 Gemini Team이 개발한 거대 비공개 모델들과 비교했을 때 상대적으로 제한된 성능을 보여왔습니다. 특히 이러한 강력한 비공개 모델들은 대부분의 연구자와 개발자들이 접근하기 어려운 상황이었습니다.
이러한 도전 과제를 해결하기 위해 연구진은 DeepSeek-Coder 시리즈를 개발했습니다. 이 시리즈는 기본 버전과 지시 학습 버전을 포함하여 1.3B부터 33B까지 다양한 크기의 오픈소스 코드 모델들로 구성되어 있습니다. 각 모델은 87개의 프로그래밍 언어로 작성된 2조 개의 토큰으로 처음부터 학습되어, 광범위한 코딩 언어와 문법에 대한 포괄적인 이해를 갖추고 있습니다.
특히 주목할 만한 점은 저장소 수준에서 사전 학습 데이터를 구성하려는 시도입니다. 이는 저장소 내의 여러 파일 간의 맥락을 이해하는 모델의 능력을 향상시키는 것을 목표로 합니다. 또한 다음 토큰 예측 손실을 사용하는 기존의 학습 방식에 더해, Li와 연구진과 Bavarian과 연구진이 제안한 Fill-In-Middle(FIM) 접근 방식을 도입하여 모델의 코드 완성 능력을 더욱 강화했습니다.
더 긴 코드 입력을 처리할 수 있도록 컨텍스트 길이를 16K로 확장한 것도 중요한 특징입니다. 이러한 조정을 통해 모델들은 더 복잡하고 광범위한 코딩 작업을 처리할 수 있게 되었으며, 다양한 코딩 시나리오에서의 활용성과 적용 가능성이 크게 향상되었습니다.
DeepSeek-Coder의 주요 기여점
DeepSeek-Coder 시리즈의 개발은 코드 지능 분야에 네 가지 중요한 기여를 했습니다. 첫째, DeepSeek-Coder-Base와 DeepSeek-Coder-Instruct라는 두 가지 버전의 고급 코드 중심 대규모 언어 모델을 소개했습니다. 이 모델들은 방대한 코드 말뭉치에 대한 광범위한 학습을 통해 87개의 프로그래밍 언어를 이해하는 능력을 갖추었으며, 다양한 계산 및 응용 요구사항을 충족시키기 위해 여러 규모로 제공됩니다.
둘째, 연구진은 모델의 사전 학습 단계에서 처음으로 저장소 수준의 데이터 구성을 도입했습니다. 이는 단순히 개별 파일 단위의 학습을 넘어서, 전체 프로젝트 컨텍스트 내에서 코드를 이해하고 생성하는 능력을 크게 향상시켰습니다. 특히 여러 파일에 걸친 코드 생성 능력이 현저히 향상되어, 실제 소프트웨어 개발 환경에서 더욱 실용적인 도움을 제공할 수 있게 되었습니다.
셋째, 연구진은 코드 모델의 사전 학습 단계에서 FIM(Fill-In-Middle) 학습 전략의 영향을 철저히 분석했습니다. 이 연구를 통해 FIM 구성의 다양한 측면에 대한 흥미로운 통찰을 얻었으며, 이는 코드 사전 학습 모델의 발전과 개선에 중요한 기여를 했습니다.
마지막으로, 연구진은 다양한 코드 관련 작업을 포괄하는 광범위한 벤치마크에 대해 철저한 평가를 수행했습니다. 이 평가를 통해 DeepSeek-Coder-Base가 모든 기존 오픈소스 코드 언어 모델들을 능가하는 성능을 보여주었음을 입증했습니다. 더욱이 지시 데이터를 통한 세심한 미세 조정을 거친 DeepSeek-Coder-Instruct는 코드 관련 작업에서 OpenAI GPT-3.5 Turbo 모델보다 우수한 성능을 달성했습니다.
이러한 기여들은 코드 지능 분야에서 오픈소스 모델의 새로운 기준을 제시했으며, 학계와 산업계 모두에서 활용할 수 있는 강력한 도구를 제공했다는 점에서 큰 의의를 가집니다.
DeepSeek-Coder의 학습 데이터셋 구성
DeepSeek-Coder의 학습 데이터셋은 소스 코드 87%, 영어 코드 관련 자연어 말뭉치 10%, 코드와 무관한 중국어 자연어 말뭉치 3%로 구성되어 있습니다. 영어 말뭉치는 GitHub의 마크다운 문서와 StackExchange에서 수집한 자료로 구성되어 있으며, 이는 모델이 코드 관련 개념을 이해하고 라이브러리 사용법이나 버그 수정과 같은 작업을 수행하는 능력을 향상시키는 데 활용됩니다. 중국어 말뭉치는 모델의 중국어 이해력을 높이기 위한 고품질 문서들로 구성되어 있습니다.
데이터셋 구축 과정은 다음과 같은 단계로 이루어집니다.

위 그림은 데이터셋 생성을 위한 파이프라인을 보여줍니다. 데이터 수집부터 시작하여 규칙 기반 필터링, 의존성 파싱, 저장소 수준의 중복 제거, 품질 검사에 이르는 전체 과정을 나타냅니다.
GitHub 데이터 수집 및 필터링 단계에서는 2023년 2월 이전에 생성된 공개 저장소들을 수집하고, 87개의 프로그래밍 언어만을 선별합니다. StarCoder 프로젝트에서 사용된 것과 유사한 필터링 규칙을 적용하여 낮은 품질의 코드를 제거하며, 이를 통해 전체 데이터의 32.8%만이 남게 됩니다.
주요 필터링 규칙은 다음과 같습니다.
- 평균 줄 길이가 100자를 초과하거나 최대 줄 길이가 1000자를 넘는 파일 제외
- 알파벳 문자가 25% 미만인 파일 제외
- XSLT를 제외한 모든 언어에서 처음 100자 내에 “<?xml version=”이 포함된 파일 제외
- HTML 파일의 경우 가시적 텍스트가 전체 코드의 20% 이상이며 최소 100자 이상인 경우만 유지
- JSON과 YAML 파일은 50자에서 5000자 사이의 파일만 유지하여 데이터 중심 파일 제거
의존성 파싱 단계에서는 프로젝트 내 파일들 간의 의존 관계를 분석합니다. 기존의 연구들이 주로 개별 파일 수준의 소스 코드만을 다루었던 것과 달리, DeepSeek-Coder는 프로젝트 전체 수준에서의 코드 시나리오를 효과적으로 처리하기 위해 파일 간 의존성을 고려합니다. 구체적으로 의존성 파싱 과정에서는 파일 간의 의존 관계를 분석하고, 각 파일이 의존하는 컨텍스트가 해당 파일보다 입력 시퀀스에서 앞서 위치하도록 파일들을 정렬합니다. 이를 위해 Python의 “import”, C#의 “using”, C의 “include”와 같은 호출 관계를 정규 표현식을 통해 추출합니다.
의존성 분석을 위한 위상 정렬 알고리즘은 다음과 같은 수학적 구조를 가집니다.
\[G = (V, E)\]여기서 \(G\)는 방향 그래프이며, \(V\)는 파일들의 집합, \(E\)는 파일 간 의존 관계를 나타내는 간선들의 집합입니다. 각 파일 \(v \in V\)에 대해 진입 차수(in-degree)를 다음과 같이 정의합니다.
\[inDegree(v) = \vert \{u \in V : (u,v) \in E\} \vert\]알고리즘은 먼저 그래프를 초기화하고, 각 파일 쌍에 대해 의존성을 검사하여 그래프를 구성합니다. 이후 연결되지 않은 부분 그래프들을 식별하고, 각 부분 그래프에 대해 수정된 위상 정렬을 수행합니다. 기존의 위상 정렬이 진입 차수가 0인 노드를 선택하는 것과 달리, 이 알고리즘은 최소 진입 차수를 가진 노드를 선택함으로써 순환 의존성이 있는 경우도 처리할 수 있습니다.
저장소 수준의 중복 제거 단계에서는 Lee와 연구진이 제시한 연구 결과를 바탕으로, 언어 모델 학습 데이터에서 발견되는 많은 중복 데이터를 제거합니다. Kocetkov와 연구진의 연구에서 보여준 것처럼, 근접 중복 제거는 코드 벤치마크 작업에서 경쟁력 있는 성능을 달성하는 데 중요한 전처리 단계입니다.
DeepSeek-Coder의 접근 방식은 기존 연구들과 차별화되는데, 개별 파일 수준이 아닌 저장소 수준에서 중복 제거를 수행합니다. 이는 저장소 내 특정 파일들만 필터링되어 저장소의 구조가 손상되는 것을 방지하기 위함입니다. 구체적으로, 저장소 수준에서 연결된 코드를 하나의 샘플로 취급하고 동일한 근접 중복 제거 알고리즘을 적용하여 저장소 구조의 무결성을 보장합니다. 품질 검사와 오염 제거 단계에서는 앞서 설명한 기본적인 필터링 규칙 외에도 컴파일러와 품질 모델, 그리고 휴리스틱 규칙을 추가로 적용하여 낮은 품질의 데이터를 걸러냅니다. 이는 구문 오류가 있는 코드, 가독성이 떨어지는 코드, 모듈화가 잘 되지 않은 코드 등을 포함합니다.
최종적으로 구축된 소스 코드 데이터셋은 총 798GB 규모로, 6억 3백만 개의 파일을 포함하고 있습니다. Java가 전체의 18.63%로 가장 큰 비중을 차지하며, 그 뒤를 이어 Python이 15.12%, C++가 11.39%를 차지합니다. TypeScript(7.60%), PHP(7.38%), JavaScript(6.75%) 등도 상당한 비중을 차지하고 있어, 현대 소프트웨어 개발에서 널리 사용되는 주요 프로그래밍 언어들이 균형있게 포함되어 있습니다.
테스트 셋 오염을 방지하기 위해 n-gram 필터링 과정을 구현했습니다. 이는 HumanEval, MBPP, GSM8K, MATH 등의 벤치마크에서 나온 문제와 해답이 포함된 docstring이나 코드 세그먼트를 제거하는 과정입니다. 구체적인 필터링 기준으로는 테스트 데이터와 동일한 10-gram 문자열을 포함하는 코드는 제외하며, 테스트 데이터가 10-gram보다 짧지만 3-gram 이상인 경우에는 정확한 매칭 방식을 사용하여 필터링합니다.
이러한 엄격한 데이터 품질 관리와 오염 방지 절차를 통해, DeepSeek-Coder는 높은 품질의 학습 데이터셋을 확보할 수 있었습니다. 이는 모델이 실제 개발 환경에서 마주치는 다양한 프로그래밍 과제를 효과적으로 해결할 수 있는 능력을 갖추는데 핵심적인 역할을 합니다.
학습 전략과 모델 아키텍처
DeepSeek-Coder의 학습 전략은 크게 두 가지 주요 목표를 중심으로 구성됩니다. 첫 번째는 다음 토큰 예측(Next Token Prediction)이며, 두 번째는 중간 채우기(Fill-in-the-Middle, FIM) 방식입니다.
다음 토큰 예측은 고정 길이의 입력을 기반으로 후속 토큰을 예측하는 기본적인 학습 방식입니다. 여러 파일들을 연결하여 고정 길이의 입력을 구성하고, 이를 통해 모델이 주어진 컨텍스트를 바탕으로 다음에 올 토큰을 예측하는 능력을 학습합니다.
중간 채우기(FIM) 방식은 Bavarian과 연구진, Li와 연구진이 제안한 방법을 기반으로 합니다. 코드 사전 학습 과정에서는 주어진 컨텍스트와 후속 텍스트를 바탕으로 중간에 들어갈 내용을 생성해야 하는 경우가 많습니다. 프로그래밍 언어의 특수한 의존성 때문에 단순한 다음 토큰 예측만으로는 이러한 중간 채우기 능력을 충분히 학습하기 어렵습니다.
FIM 방식은 두 가지 모드로 구현됩니다. PSM(Prefix-Suffix-Middle)과 SPM(Suffix-Prefix-Middle)입니다. PSM 모드에서는 텍스트를 Prefix, Suffix, Middle 순서로 배열하며, SPM 모드에서는 Suffix, Prefix, Middle 순서로 배열합니다. 연구진은 다양한 하이퍼파라미터 설정에 대한 실험을 통해 FIM 방식의 효과를 검증했습니다.
실험에서는 DeepSeek-Coder-Base 1.3B 모델을 사용하여 Python 서브셋에 대해 평가를 진행했습니다. HumanEval-FIM 벤치마크를 통해 FIM 기법의 효과를 측정했는데, 이 벤치마크는 Python 코드에서 한 줄을 무작위로 가려두고 모델이 이를 예측하는 능력을 평가합니다.
실험 결과, 100% FIM 비율에서 HumanEval-FIM 성능이 가장 높았지만, 이 경우 코드 완성 능력이 가장 낮은 것으로 나타났습니다. 이는 FIM 능력과 코드 완성 능력 사이에 트레이드오프가 존재함을 보여줍니다. 50% PSM 비율이 MSP(Masked Span Prediction) 전략보다 더 나은 성능을 보였으며, 결과적으로 연구진은 FIM 효율성과 코드 완성 능력의 균형을 위해 50% PSM 비율을 최종 학습 정책으로 선택했습니다.
구현 과정에서는 세 개의 특수 토큰을 도입했습니다. 각 코드 파일을 \(f_{pre}\), \(f_{middle}\), \(f_{suf}\) 세 부분으로 나누고, PSM 모드를 사용하여 다음과 같은 형태로 학습 예제를 구성합니다.
\[\texttt{<|fim_start|>}f_{pre}\texttt{<|fim_hole|>}f_{suf}\texttt{<|fim_end|>}f_{middle}\texttt{<|eos_token|>}\]이러한 FIM 방식은 Bavarian과 연구진이 제안한 원래 연구를 따라 문서 수준에서 구현되며, 0.5의 FIM 비율로 PSM 모드를 적용합니다.
토크나이저와 모델 아키텍처
DeepSeek-Coder의 토크나이저는 HuggingFace Tokenizer 라이브러리를 활용하여 구현되었습니다. Sennrich와 연구진이 제안한 바이트 페어 인코딩(Byte Pair Encoding, BPE) 방식을 사용하여 학습 데이터의 일부에서 토크나이저를 학습시켰으며, 최종적으로 32,000개의 어휘 크기를 가진 토크나이저를 구축했습니다.
모델 아키텍처는 다양한 응용 분야를 지원하기 위해 1.3B, 6.7B, 33B 파라미터를 가진 여러 규모의 모델들로 구성되어 있습니다. 이 모델들은 DeepSeek-AI가 개발한 DeepSeek Large Language Model(LLM)의 프레임워크를 기반으로 합니다. 각 모델은 디코더 전용 트랜스포머 구조를 채택하고 있으며, Su와 연구진이 제안한 회전 위치 임베딩(Rotary Position Embedding, RoPE)을 통합했습니다.
특히 DeepSeek 33B 모델은 그룹 크기가 8인 그룹 쿼리 어텐션(Grouped-Query-Attention, GQA)을 도입하여 학습과 추론 효율성을 향상시켰습니다. 또한 Dao가 개발한 FlashAttention v2를 적용하여 어텐션 메커니즘의 계산 속도를 개선했습니다.
최적화 과정에서는 DeepSeek LLM의 접근 방식을 따라 AdamW 옵티마이저를 사용했으며, \(\beta_1\)과 \(\beta_2\) 값은 각각 0.9와 0.95로 설정했습니다. 배치 크기와 학습률은 DeepSeek LLM에서 제시한 스케일링 법칙에 따라 조정되었습니다. 학습률 스케줄링은 2,000 스텝의 웜업 단계를 포함한 3단계 정책을 구현했으며, 최종 학습률은 초기 학습률의 10%로 설정했습니다. 각 단계에서의 학습률은 이전 단계 학습률의 \(\sqrt{\frac{1}{10}}\)로 감소됩니다.
실험 환경은 High-Flyer가 개발한 HAI-LLM 프레임워크를 기반으로 구축되었습니다. 이 프레임워크는 대규모 언어 모델 학습을 위한 효율적이고 경량화된 접근 방식을 제공합니다. 텐서 병렬화, ZeRO 데이터 병렬화, PipeDream 파이프라인 병렬화 등 다양한 병렬 처리 전략을 활용하여 계산 효율성을 최적화했습니다.
실험에는 NVIDIA A100과 H800 GPU가 장착된 클러스터가 사용되었습니다. A100 클러스터의 각 노드는 8개의 GPU로 구성되어 있으며, NVLink 브리지를 통해 페어로 연결되어 있습니다. H800 클러스터도 유사한 구성을 가지고 있으며, NVLink와 NVSwitch 기술을 조합하여 노드 내 GPU 간의 효율적인 데이터 전송을 보장합니다. 두 클러스터 모두 노드 간 통신을 위해 높은 처리량과 낮은 지연 시간을 특징으로 하는 InfiniBand 인터커넥트를 사용합니다.
긴 컨텍스트 처리와 지시 학습
DeepSeek-Coder의 저장소 수준 코드 처리와 같은 확장된 컨텍스트 처리 능력을 향상시키기 위해, 연구진은 회전 위치 임베딩(RoPE) 파라미터를 재구성했습니다. Chen과 연구진, kaiokendev의 이전 연구 사례를 따라 선형 스케일링 전략을 적용했는데, 구체적으로 스케일링 팩터를 1에서 4로 증가시키고 기본 주파수를 10000에서 100000으로 변경했습니다.
이러한 수정을 통해 이론적으로는 모델이 최대 64K 토큰까지 처리할 수 있게 되었습니다. 모델은 512의 배치 크기와 16K의 시퀀스 길이를 사용하여 추가로 1000 스텝의 학습을 진행했으며, 학습률은 사전 학습의 마지막 단계와 동일하게 유지했습니다. 그러나 실제 실험 결과, 모델이 가장 안정적인 출력을 보이는 범위는 16K 토큰 이내인 것으로 관찰되었습니다.
DeepSeek-Coder-Instruct는 DeepSeek-Coder-Base를 기반으로 고품질 데이터를 활용한 지시 학습을 통해 개발되었습니다. 이 과정에서 Taori와 연구진이 제안한 Alpaca 지시 형식을 따르는 도움이 되고 공정한 인간 지시사항들이 사용되었습니다. 각 대화 턴의 구분을 위해 특별한 구분자 토큰인 <|EOT|>를 도입했습니다.
지시 학습을 위한 최적화 과정에서는 100 스텝의 웜업을 포함하는 코사인 스케줄을 사용했으며, 초기 학습률은 1e-5로 설정했습니다. 4M 토큰의 배치 크기를 사용했으며, 총 2B 토큰에 대해 학습을 진행했습니다.
아래 그림은 DeepSeek-Coder-Instruct 33B를 사용한 다중 턴 대화 예시를 보여줍니다. 이 예시에서는 Pygame을 사용한 스네이크 게임 구현 과정을 보여주는데, 초기에 기본적인 스네이크 게임을 구현한 후, 왼쪽 상단에 점수 시스템을 추가하는 과정을 통해 모델의 다중 턴 대화 능력을 잘 보여줍니다.

이 예시는 모델이 복잡한 프로그래밍 작업을 단계적으로 수행하고, 사용자의 추가 요구사항을 이해하여 기존 코드를 수정하고 확장하는 능력을 갖추고 있음을 보여줍니다. 특히 점수 변수의 도입과 display_score 함수의 구현을 통해 게임의 기능을 확장하는 과정에서 모델의 코드 이해 및 생성 능력이 잘 드러납니다.
DeepSeek-Coder의 성능 평가
DeepSeek-Coder의 성능 평가는 네 가지 주요 과제를 중심으로 진행되었습니다. 코드 생성, FIM 코드 완성, 크로스 파일 코드 완성, 그리고 프로그램 기반 수학적 추론 능력을 평가했습니다. 이러한 종합적인 평가를 통해 모델의 실제 개발 환경에서의 실용성과 효과성을 검증했습니다.
평가 과정에서 DeepSeek-Coder는 여러 최신 대규모 언어 모델들과 비교되었습니다. CodeGeeX2는 ChatGLM2 아키텍처를 기반으로 개발된 다국어 코드 생성 모델의 2세대 버전입니다. StarCoder는 15B 파라미터를 가진 공개 모델로, Stack 데이터셋의 엄선된 부분집합을 통해 86개 프로그래밍 언어에 대한 학습을 진행했습니다. CodeLlama는 LLaMA2를 기반으로 하여 7B, 13B, 34B 세 가지 규모로 개발되었으며, 5천억 토큰의 코드 말뭉치로 추가 학습되었습니다.
또한 OpenAI의 code-cushman-001과 GPT 시리즈(GPT-3.5, GPT-4)도 비교 대상에 포함되었습니다. 특히 GPT 모델들은 코드 생성을 위해 특별히 학습되지는 않았지만, 거대한 파라미터 규모를 바탕으로 코드 생성 분야에서도 뛰어난 성능을 보여주고 있습니다.
HumanEval과 MBPP 벤치마크를 통한 코드 생성 능력 평가에서는 주목할 만한 결과가 나타났습니다. HumanEval은 164개의 수작업으로 작성된 Python 문제로 구성되어 있으며, 제로샷 설정에서 테스트 케이스를 통해 모델의 코드 생성 능력을 평가합니다. MBPP는 500개의 문제를 포함하고 있으며, 퓨샷 설정에서 평가가 이루어집니다.
다국어 능력 평가를 위해 HumanEval의 Python 문제들을 C++, Java, PHP, TypeScript, C#, Bash, JavaScript 등 7개의 추가 프로그래밍 언어로 확장했습니다. 모든 평가는 동일한 스크립트와 환경에서 그리디 서치 방식을 사용하여 공정한 비교가 이루어지도록 했습니다.
평가 결과, DeepSeek-Coder-Base는 HumanEval에서 평균 50.3%, MBPP에서 66.0%의 정확도를 달성하며 최고 수준의 성능을 보여주었습니다. 특히 비슷한 규모의 오픈소스 모델인 CodeLlama-Base 34B와 비교했을 때 각각 9%와 11%의 성능 향상을 달성했습니다. 주목할 만한 점은 더 작은 규모인 DeepSeek-Coder-Base 6.7B 모델도 CodeLlama-Base 34B의 성능을 뛰어넘었다는 것입니다. 지시 학습을 통한 미세 조정 이후, DeepSeek-Coder는 HumanEval 벤치마크에서 GPT-3.5-Turbo 모델의 성능을 뛰어넘으며, 오픈소스 모델과 비공개 모델 간의 성능 격차를 크게 줄였습니다.
DS-1000 벤치마크는 HumanEval과 MBPP가 가진 한계를 보완하기 위해 도입되었습니다. 기존 벤치마크들이 단순한 프로그래밍 과제에 치중되어 있어 실제 프로그래머들이 작성하는 코드의 특성을 제대로 반영하지 못한다는 문제가 있었습니다. Lai와 연구진이 제안한 DS-1000 벤치마크는 7개의 서로 다른 라이브러리에 걸쳐 1,000개의 실용적이고 현실적인 데이터 사이언스 워크플로우를 포함하고 있습니다. 이 벤치마크는 특정 테스트 케이스에 대한 코드 실행을 통해 코드 생성 능력을 평가하며, Matplotlib, NumPy, Pandas, SciPy, Scikit-Learn, PyTorch, TensorFlow와 같은 라이브러리별로 문제를 분류하여 평가합니다.
DS-1000 벤치마크 평가 결과에서 DeepSeek-Coder 모델은 모든 라이브러리에서 높은 정확도를 보여주었습니다. 특히 DeepSeek-Coder-Base 33B 모델은 Matplotlib에서 56.1%, NumPy에서 49.6%, PyTorch에서 36.8%의 정확도를 달성했으며, 전체 평균 40.2%의 성능을 보여주었습니다. 이는 모델이 단순한 코드 생성을 넘어 실제 데이터 사이언스 워크플로우에서 라이브러리를 더 정확하게 활용할 수 있음을 입증합니다.
LeetCode 콘테스트 벤치마크는 모델의 실제 프로그래밍 문제 해결 능력을 검증하기 위해 새롭게 구성되었습니다. 사전 학습 데이터와의 중복을 피하기 위해 2023년 7월부터 2024년 1월까지의 최신 LeetCode 콘테스트 문제 180개를 수집했으며, 각 문제마다 100개의 테스트 케이스를 포함시켜 테스트 커버리지를 확보했습니다.
평가 결과, DeepSeek-Coder-Instruct 모델들은 기존 오픈소스 코딩 모델들을 크게 앞서는 성능을 보여주었습니다. DeepSeek-Coder-Instruct 6.7B와 33B는 각각 19.4%와 27.8%의 Pass@1 점수를 달성했으며, 특히 33B 모델은 오픈소스 모델 중 유일하게 GPT-3.5-Turbo의 성능을 뛰어넘었습니다. 그러나 GPT-4-Turbo와 비교했을 때는 여전히 상당한 성능 격차가 존재합니다. Chain-of-Thought(CoT) 프롬프팅의 효과성도 LeetCode 콘테스트 벤치마크를 통해 분석되었습니다. “먼저 단계별 개요를 작성한 다음 코드를 작성하세요.”라는 지시를 초기 프롬프트에 추가함으로써, DeepSeek-Coder-Instruct 모델들의 성능이 향상되는 것을 확인할 수 있었습니다. 특히 복잡한 과제에서 이러한 성능 향상이 두드러졌습니다.
DeepSeek-Coder-Instruct 33B 모델의 경우, CoT 프롬프팅을 적용했을 때 중간 난이도 문제에서의 성능이 22.0%에서 25.3%로 향상되었습니다. 이는 코드를 작성하기 전에 상세한 설명을 먼저 작성하는 과정이 모델이 로직과 의존성을 더 효과적으로 이해하고 처리하는 데 도움이 된다는 것을 보여줍니다. 따라서 연구진은 복잡한 코딩 과제에서 DeepSeek-Coder-Instruct 모델을 사용할 때 CoT 프롬프팅 전략을 적극적으로 활용할 것을 권장합니다.
FIM(Fill-in-the-Middle) 코드 완성 평가에서는 DeepSeek-Coder 모델들이 사전 학습 단계에서 0.5의 FIM 비율로 학습되었다는 점이 중요합니다. 이러한 학습 전략은 모델이 주어진 코드 스니펫의 앞뒤 문맥을 모두 고려하여 빈 칸을 채우는 능력을 향상시켰습니다. SantaCoder, StarCoder, CodeLlama와 같은 여러 오픈소스 모델들도 유사한 기능을 제공하고 있습니다.
단일 라인 채우기 벤치마크에서 DeepSeek-Coder 모델들은 Python, Java, JavaScript 세 가지 프로그래밍 언어에 대해 평가되었습니다. 특히 주목할 만한 점은 1.3B 파라미터라는 작은 규모에도 불구하고, DeepSeek-Coder가 StarCoder와 CodeLlama와 같은 더 큰 모델들보다 우수한 성능을 보여주었다는 것입니다. 이는 DeepSeek-Coder의 사전 학습 데이터의 높은 품질을 입증하는 결과입니다.
모델 크기와 성능 간의 상관관계도 명확하게 관찰되었습니다. 모델의 크기가 증가함에 따라 코드 완성 작업에서의 정확도도 비례하여 향상되었습니다. 이러한 발견을 바탕으로 연구진은 코드 완성 도구에 DeepSeek-Coder-Base 6.7B 모델을 사용할 것을 권장합니다. 이 모델은 효율성과 정확성 사이의 최적의 균형을 제공하며, 실제 개발 환경에서 충분히 활용 가능한 수준의 성능을 보여줍니다. 크로스 파일 코드 완성 평가에서는 기존 오픈소스 모델들의 성능을 CrossCodeEval 벤치마크를 통해 검증했습니다. 코드 생성과는 달리, 크로스 파일 코드 완성은 여러 파일에 걸친 의존성을 가진 저장소의 맥락을 이해하고 활용해야 하는 더 복잡한 과제입니다.
Ding과 연구진이 개발한 CrossCodeEval은 Python, Java, TypeScript, C# 네 가지 프로그래밍 언어를 대상으로 하며, 실제 오픈소스 저장소에서 추출한 크로스 파일 의존성이 필수적인 코드 완성 과제들로 구성되어 있습니다. 특히 이 데이터셋은 2023년 3월에서 6월 사이에 생성된 저장소들을 기반으로 하며, DeepSeek-Coder의 사전 학습 데이터가 2023년 2월 이전의 코드만을 포함하고 있어 데이터 유출 문제를 방지했습니다.
평가 과정에서는 시퀀스 길이를 2048 토큰으로 제한하고, 출력 길이는 50 토큰, 크로스 파일 컨텍스트는 512 토큰으로 제한했습니다. 크로스 파일 컨텍스트 검색을 위해 Ding과 연구진이 제공한 공식 BM25 검색 결과를 활용했으며, 정확한 매치(EM)와 편집 유사도(ES)를 평가 지표로 사용했습니다.
평가 결과는 DeepSeek-Coder가 다른 모델들과 비교해 모든 언어에서 일관되게 우수한 성능을 보여주었습니다. 특히 Python에서는 16.14%의 정확한 매치율과 66.51%의 편집 유사도를 달성했으며, Java에서도 17.72%의 정확한 매치율을 기록했습니다. 이는 StarCoder나 CodeLlama와 같은 다른 7B 규모 모델들의 성능을 크게 앞서는 결과입니다.
프로그램 기반 수학 추론 능력 평가에서는 Gao와 연구진이 제안한 PAL(Program-Aided Math Reasoning) 방법을 활용했습니다. 이 평가는 GSM8K, MATH, GSM-Hard, SVAMP, TabMWP, ASDiv, MAWPS 등 7개의 서로 다른 벤치마크를 통해 이루어졌습니다. 각 벤치마크에서 모델은 자연어로 해결 단계를 설명하고 코드로 그 단계를 실행하는 방식으로 문제를 해결합니다.
DeepSeek-Coder 모델들은 이러한 수학 추론 과제에서도 탁월한 성능을 보여주었습니다. 특히 33B 모델은 GSM8K에서 60.7%, MATH에서 29.1%, GSM-Hard에서 54.1%의 정확도를 달성했으며, 전체 평균 65.8%의 성능을 기록했습니다. 이는 모델이 복잡한 수학적 계산과 문제 해결 능력을 필요로 하는 응용 분야에서도 효과적으로 활용될 수 있음을 보여줍니다.
DeepSeek-Coder-v1.5: 자연어 이해와 수학적 추론 능력의 향상
DeepSeek-Coder의 자연어 이해와 수학적 추론 능력을 더욱 향상시키기 위해, 연구진은 DeepSeek-LLM-7B Base 모델을 기반으로 2조 개의 토큰을 사용하여 추가 사전 학습을 진행했습니다. 이를 통해 개발된 DeepSeek-Coder-v1.5 7B는 이전 모델과 비교하여 주목할 만한 성능 향상을 보여주었습니다.
DeepSeek-Coder-v1.5의 사전 학습 데이터는 다음과 같은 비율로 구성되었습니다.
- 소스 코드: 70%
- 마크다운과 StackExchange 데이터: 10%
- 코드 관련 자연어: 7%
- 수학 관련 자연어: 7%
- 중국어-영어 이중 언어 자연어: 6%
이전 버전과의 주요한 차이점은 사전 학습 과정에서 4K 컨텍스트 길이를 가진 다음 토큰 예측 목표만을 사용했다는 점입니다. 이러한 변화를 통해 모델의 성능을 다양한 벤치마크에서 평가했으며, 평가 범주는 크게 세 가지로 나눌 수 있습니다.
프로그래밍 능력 평가에서는 Chen과 연구진이 개발한 HumanEval 데이터셋을 사용하여 다국어 환경에서의 성능을, Austin과 연구진이 개발한 MBPP 데이터셋을 통해 Python 환경에서의 성능을 측정했습니다.
수학적 추론 능력 평가에서는 Cobbe와 연구진이 개발한 GSM8K 벤치마크와 Hendrycks와 연구진이 개발한 MATH 벤치마크를 활용했습니다. 이러한 과제들은 프로그램을 생성하여 수학 문제를 해결하는 능력을 평가합니다.
자연어 처리 능력 평가에서는 Hendrycks와 연구진의 MMLU, Suzgun과 연구진의 BBH, Zellers와 연구진의 HellaSwag, Sakaguchi와 연구진의 Winogrande, Clark과 연구진의 ARC-Challenge 벤치마크를 사용했습니다.
평가 결과, DeepSeek-Coder-Base-v1.5는 코딩 성능에서 약간의 감소를 보였지만, 대부분의 과제에서 이전 모델인 DeepSeek-Coder-Base보다 현저한 성능 향상을 보여주었습니다. 특히 수학적 추론과 자연어 처리 분야에서 모든 벤치마크에서 큰 폭의 성능 향상을 달성했습니다.
구체적인 성능 향상을 살펴보면, GSM8K에서는 43.2%에서 62.4%로, MATH에서는 19.2%에서 24.7%로 수학적 추론 능력이 크게 향상되었습니다. 자연어 처리 분야에서도 MMLU(36.6%→49.1%), BBH(44.3%→55.2%), HellaSwag(53.8%→69.9%), Winogrande(57.1%→63.8%), ARC-Challenge(32.5%→47.2%) 등 모든 벤치마크에서 상당한 성능 향상을 보여주었습니다.
결론: DeepSeek-Coder의 혁신과 미래 전망
본 기술 보고서는 코딩에 특화된 대규모 언어 모델(LLM) 시리즈인 DeepSeek-Coder를 소개합니다. 이 모델은 1.3B, 6.7B, 33B 파라미터의 세 가지 규모로 개발되었으며, 프로젝트 수준의 코드 말뭉치를 기반으로 세심하게 학습되었습니다. 특히 “빈칸 채우기(fill-in-the-blank)” 사전 학습 목표를 도입하여 코드 채우기 능력을 향상시켰으며, 컨텍스트 윈도우를 16,384 토큰으로 확장하여 광범위한 코드 생성 작업에서의 효과성을 크게 개선했습니다.
평가 결과에 따르면, DeepSeek-Coder 시리즈의 최상위 모델인 DeepSeek-Coder-Base 33B는 다양한 표준 테스트에서 기존의 오픈소스 코드 모델들을 능가하는 성능을 보여주었습니다. 특히 주목할 만한 점은 더 작은 규모인 DeepSeek-Coder-Base 6.7B 모델이 34B 파라미터를 가진 CodeLlama와 대등한 성능을 달성했다는 것입니다. 이는 연구진이 구축한 사전 학습 말뭉치의 우수한 품질을 입증하는 결과입니다.
DeepSeek-Coder-Base 모델의 제로샷 지시 능력을 향상시키기 위해, 연구진은 고품질 지시 데이터를 활용한 미세 조정을 진행했습니다. 그 결과로 개발된 DeepSeek-Coder-Instruct 33B 모델은 다양한 코딩 관련 작업에서 OpenAI의 GPT-3.5 Turbo를 능가하는 성능을 보여주었으며, 코드 생성과 이해 분야에서 탁월한 능력을 입증했습니다.
더 나아가 DeepSeek-Coder-Base 모델의 자연어 이해 능력을 향상시키기 위해, DeepSeek-LLM 7B 체크포인트를 기반으로 추가 사전 학습을 진행했습니다. 이 과정에서 자연어, 코드, 수학 데이터를 포함하는 20억 토큰 규모의 다양한 데이터셋이 활용되었습니다. 그 결과로 탄생한 DeepSeek-Coder-v1.5는 이전 모델의 뛰어난 코딩 성능을 유지하면서도 자연어 이해력이 크게 향상된 것으로 나타났습니다.
이러한 연구 결과는 효과적인 코드 중심 대규모 언어 모델이 강력한 일반 LLM을 기반으로 구축되어야 한다는 저자들의 견해를 뒷받침합니다. 그 이유는 명확합니다. 코딩 작업을 효과적으로 해석하고 실행하기 위해서는 다양한 형태의 자연어로 표현되는 인간의 지시사항을 깊이 있게 이해할 수 있어야 하기 때문입니다.
연구진은 앞으로 더 큰 규모의 일반 LLM을 기반으로 하여 더욱 강력한 코드 중심 LLM을 개발하고 공개할 계획을 밝혔습니다. 이는 코드 지능 분야의 발전을 가속화하고, 소프트웨어 개발 생태계를 더욱 풍부하게 만드는데 기여할 것으로 기대됩니다.
DeepSeek-Coder의 실제 활용 사례 분석
DeepSeek-Coder의 실제 활용 능력을 검증하기 위해 연구진은 두 가지 주요 상호작용 시나리오를 제시했습니다. 첫 번째는 데이터베이스 구축과 데이터 분석을 포함하는 다중 턴 대화이며, 두 번째는 LeetCode 문제 해결에 관한 것입니다.
첫 번째 시나리오에서는 Python을 사용한 학생 데이터베이스 구축과 분석 과정을 보여줍니다. 아래 그림은 SQLite 데이터베이스를 생성하고, 무작위로 생성된 10개의 학생 정보를 삽입한 후, matplotlib 라이브러리를 활용하여 학생들의 연령 분포를 시각화하는 과정을 보여줍니다.

이 예시는 DeepSeek-Coder가 실제 개발 환경에서 마주치는 복잡한 작업을 얼마나 효과적으로 처리할 수 있는지를 보여줍니다. 특히 데이터베이스 조작, 데이터 분석, 시각화와 같은 여러 기술적 요소들을 통합적으로 다룰 수 있는 능력이 돋보입니다.
두 번째 시나리오에서는 모델의 도메인 외 문제 해결 능력을 평가하기 위해 2023년 11월에 출시된 LeetCode 콘테스트 문제를 활용했습니다. 이 문제는 모델의 학습 데이터 수집 시점 이후에 공개된 것으로, 학습 데이터에 포함되지 않은 새로운 과제입니다.

위 그림은 토너먼트 스타일 경쟁에서 우승 팀을 찾는 알고리즘 문제의 해결 과정을 보여줍니다. 이는 방향 그래프 구성, 우승 팀 식별, 각 팀의 진입 차수 계산 등 복잡한 알고리즘적 사고를 요구하는 문제입니다. DeepSeek-Coder는 이러한 도전적인 문제도 효과적으로 해결할 수 있음을 입증했습니다.
이어서 연구진은 DeepSeek-Coder-Base의 학습 과정에서의 성능 변화를 보여주는 벤치마크 곡선을 제시했습니다. 검증을 위해 학습 코퍼스에서 신중하게 선별된 8,000개의 코드 파일로 구성된 부분집합이 사용되었습니다.
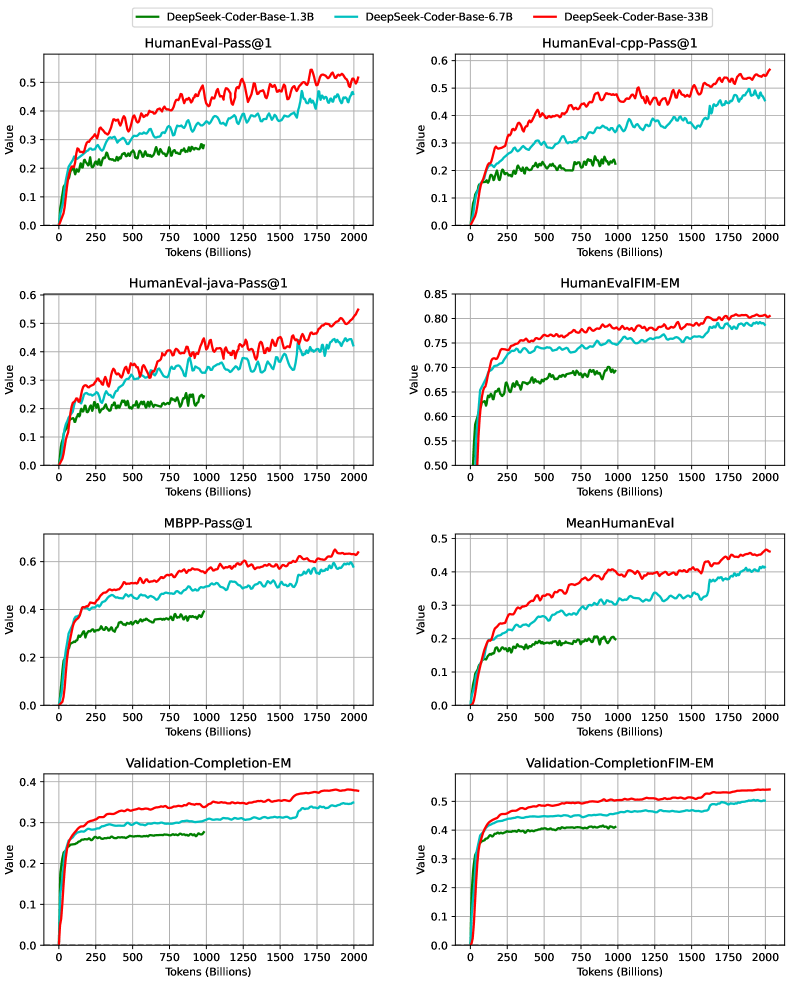
이 그래프는 학습이 진행됨에 따른 다양한 평가 지표들의 변화를 보여줍니다. HumanEval-Pass, HumanEval-java-Pass, MBPP-Pass, MeanHumanEval, Validation-Completion-EM, Validation-Completion-FIM-EM 등의 지표들이 포함되어 있으며, 이를 통해 모델의 점진적인 성능 향상을 확인할 수 있습니다.
References
Subscribe via RSS