DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
by DeepSeek-AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
오픈소스 대규모 언어 모델(LLMs)의 발전이 가속화되면서, 모델의 효과적인 확장 방법에 대한 불확실성이 대두되었습니다. 기존 연구에서 제시된 스케일링 법칙들이 서로 다른 결론을 보여주었고, 하이퍼파라미터 설정에 대한 명확한 지침이 부족했습니다. 특히 컴퓨팅 예산 증가에 따른 모델과 데이터의 최적 스케일링 비율에 대한 체계적인 연구가 필요했습니다. 이러한 배경에서 DeepSeek 연구진은 장기적 관점에서 오픈소스 LLM을 효과적으로 확장하기 위한 포괄적인 연구를 시작하게 되었습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
연구진은 세 가지 주요 혁신을 제시했습니다. 첫째, 비임베딩 FLOPs/토큰(M)이라는 새로운 모델 규모 측정 방식을 도입하여 기존의 파라미터 기반 측정 방식의 한계를 극복했습니다. 둘째, 데이터 품질이 스케일링 법칙에 미치는 영향을 체계적으로 분석하여, 데이터 품질이 향상될수록 모델 스케일링에 더 많은 컴퓨팅 자원을 할당해야 한다는 새로운 통찰을 제시했습니다. 셋째, 다단계 학습률 스케줄러를 도입하여 모델의 지속적 학습과 성능 향상을 가능하게 했습니다.
제안된 방법은 어떻게 구현되었습니까?
연구진은 2조 개의 토큰으로 구성된 다국어 데이터셋을 구축하고, 7B와 67B 파라미터의 두 가지 모델 구성을 개발했습니다. 모델 정렬을 위해 150만 개의 지시 데이터를 수집하여 지도 학습 미세조정(SFT)과 직접 선호도 최적화(DPO)를 수행했습니다. 특히 데이터 처리 과정에서는 중복 제거, 필터링, 재혼합의 세 단계를 거쳐 데이터의 품질을 향상시켰습니다. 또한 HAI-LLM이라는 효율적인 학습 프레임워크를 개발하여 다양한 병렬화 기법과 최적화 전략을 구현했습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
이 연구는 오픈소스 LLM의 효과적인 확장을 위한 체계적인 방법론을 제시했다는 점에서 중요한 의미를 가집니다. DeepSeek LLM 67B 모델은 코드 생성, 수학, 추론 등 다양한 벤치마크에서 LLaMA-2 70B를 능가했으며, 채팅 모델은 GPT-3.5보다 우수한 성능을 보여주었습니다. 특히 데이터 품질과 스케일링 법칙의 관계에 대한 새로운 발견은 향후 LLM 개발에 중요한 지침이 될 것으로 기대됩니다. 또한 97.8%의 높은 안전성 점수는 대규모 언어 모델의 책임있는 개발 가능성을 보여주었습니다.
DeepSeek LLM: 장기적 관점으로 오픈소스 언어 모델 확장하기
오픈소스 대규모 언어 모델(Large Language Models, LLMs)의 발전은 최근 몇 년간 놀라운 속도로 이루어져 왔습니다. 그러나 기존 연구에서 제시된 스케일링 법칙들은 서로 다른 결론을 보여주며, 이는 LLM의 확장에 대한 불확실성을 야기했습니다. DeepSeek 연구진은 이러한 문제를 해결하기 위해 스케일링 법칙에 대한 심도 있는 연구를 수행하였고, 7B와 67B 파라미터라는 두 가지 주요 오픈소스 모델 구성에서 대규모 모델의 효과적인 확장을 가능하게 하는 독특한 발견을 제시합니다.
DeepSeek LLM 프로젝트는 장기적 관점에서 오픈소스 언어 모델을 발전시키는 것을 목표로 합니다. 이를 위해 연구진은 현재 2조 개의 토큰으로 구성되어 있으며 지속적으로 확장되고 있는 사전학습 데이터셋을 구축했습니다. 이는 Kaplan과 연구진이 제시한 스케일링 법칙에서 강조된 대규모 데이터의 중요성을 반영한 것입니다.
DeepSeek 연구진은 기본 모델(Base Model)에 대해 지도 학습 미세조정(Supervised Fine-tuning, SFT)과 직접 선호도 최적화(Direct Preference Optimization, DPO)를 수행하여 DeepSeek Chat 모델을 개발했습니다. 이러한 접근 방식은 Hoffmann과 연구진이 제시한 컴퓨팅 최적 스케일링 원칙을 따르면서도, 모델의 실용적 성능을 향상시키는데 초점을 맞춘 것입니다.
평가 결과에 따르면, DeepSeek LLM 67B 모델은 코드 생성, 수학, 추론 등 다양한 벤치마크에서 LLaMA-2 70B 모델을 능가하는 성능을 보여주었습니다. 특히 주목할 만한 점은 DeepSeek LLM 67B Chat 모델이 개방형 평가에서 GPT-3.5보다 우수한 성능을 보였다는 것입니다. 이는 Touvron과 연구진이 LLaMA 모델에서 보여준 성과를 한 단계 더 발전시킨 것으로 볼 수 있습니다.
이 논문은 스케일링 법칙에 대한 체계적인 연구를 통해 오픈소스 LLM의 효과적인 확장 방법을 제시하고, 실제 구현을 통해 그 유효성을 입증했다는 점에서 중요한 의미를 가집니다. 특히 지속적으로 확장되는 데이터셋과 체계적인 모델 정렬 방법론은 향후 오픈소스 LLM 발전의 중요한 이정표가 될 것으로 기대됩니다.
최근 몇 년간 디코더 전용 트랜스포머(Decoder-only Transformer)를 기반으로 하는 대규모 언어 모델(Large Language Models, LLMs)은 인공일반지능(Artificial General Intelligence, AGI)을 달성하기 위한 핵심 요소로 자리잡았습니다. Vaswani와 연구진이 제안한 트랜스포머 아키텍처를 기반으로, 이러한 모델들은 연속된 텍스트에서 다음 단어를 예측하는 자기지도 학습(self-supervised pre-training)을 통해 창작, 요약, 코드 완성 등 다양한 능력을 갖추게 되었습니다.
이러한 발전은 지도 학습 미세조정(supervised fine-tuning)과 보상 모델링(reward modeling)을 통해 더욱 가속화되었으며, 이를 통해 LLM은 사용자의 의도와 지시를 더 잘 따르고 더욱 다재다능한 대화 능력을 갖추게 되었습니다. ChatGPT, Claude, Bard와 같은 상용 제품들이 이러한 혁신의 물결을 주도했으며, 이들은 막대한 컴퓨팅 자원과 데이터 주석 비용을 투자하여 개발되었습니다.
이러한 상용 제품들의 성공은 오픈소스 LLM에 대한 커뮤니티의 기대치를 크게 높였고, 이는 일련의 연구들로 이어졌습니다. 특히 Touvron과 연구진이 개발한 LLaMA 시리즈는 7B에서 70B 파라미터에 이르는 효율적이고 안정적인 아키텍처를 구축하여 오픈소스 모델의 기준점이 되었습니다.
그러나 LLaMA 이후 오픈소스 커뮤니티는 주로 고정된 크기(7B, 13B, 34B, 70B)의 고품질 모델 개발에 집중하면서, Kaplan과 Hoffmann 연구진이 강조한 LLM 스케일링 법칙에 대한 연구는 상대적으로 소홀히 다뤄졌습니다. 현재 오픈소스 모델들이 AGI 발전의 초기 단계에 있다는 점을 고려할 때, 스케일링 법칙에 대한 연구는 매우 중요합니다.
특히 초기 연구들은 컴퓨팅 예산 증가에 따른 모델과 데이터의 스케일링에 대해 서로 다른 결론을 도출했으며, 하이퍼파라미터에 대한 논의도 충분히 이루어지지 않았습니다. 이에 본 논문에서는 언어 모델의 스케일링 동작을 광범위하게 조사하고, 이를 7B와 67B라는 두 가지 널리 사용되는 대규모 모델 구성에 적용했습니다.
연구진은 배치 크기와 학습률의 스케일링 법칙을 먼저 조사하여 모델 크기에 따른 경향성을 파악했으며, 이를 바탕으로 데이터와 모델 규모의 스케일링 법칙에 대한 포괄적인 연구를 수행했습니다. 이를 통해 최적의 모델/데이터 스케일링 할당 전략을 도출하고 대규모 모델의 예상 성능을 예측할 수 있었습니다. 연구 과정에서 주목할 만한 발견은 서로 다른 데이터셋에서 도출된 스케일링 법칙이 상당한 차이를 보인다는 점입니다. 이는 데이터셋의 선택이 스케일링 동작에 큰 영향을 미친다는 것을 시사하며, 스케일링 법칙을 다른 데이터셋에 일반화할 때 신중한 접근이 필요함을 보여줍니다.
이러한 연구 결과를 바탕으로, 연구진은 처음부터 오픈소스 대규모 언어 모델을 구축했습니다. 사전학습을 위해 중국어와 영어를 중심으로 2조 개의 토큰을 수집했으며, 모델 아키텍처는 기본적으로 LLaMA를 따르되 중요한 변경을 가했습니다. 특히 코사인 학습률 스케줄러를 다단계 학습률 스케줄러로 대체하여 성능을 유지하면서도 지속적인 학습이 용이하도록 했습니다.
모델의 성능 향상을 위해 다양한 출처에서 100만 개 이상의 지도 학습 미세조정(SFT) 데이터를 수집했으며, 여러 SFT 전략과 데이터 선별 기법을 실험했습니다. 또한 직접 선호도 최적화(DPO)를 활용하여 모델의 대화 성능을 개선했습니다. Rafailov와 연구진이 제안한 DPO 방법론은 기존의 인간 피드백을 통한 강화학습(RLHF) 접근방식보다 더 효율적이고 안정적인 학습을 가능하게 했습니다.
기본 모델과 채팅 모델에 대한 광범위한 평가 결과, DeepSeek LLM은 코드, 수학, 추론 등 다양한 벤치마크에서 LLaMA-2 70B를 능가하는 성능을 보여주었습니다. SFT와 DPO를 거친 DeepSeek 67B 채팅 모델은 중국어와 영어 모두에서 GPT-3.5보다 우수한 성능을 보였으며, 안전성 평가에서도 해롭지 않은 응답을 제공할 수 있음이 확인되었습니다.
본 논문의 나머지 부분에서는 DeepSeek LLM의 사전학습 기본 개념, 스케일링 법칙의 상세한 설명과 의미, 미세조정 방법론, 그리고 평가 결과를 순차적으로 다룰 예정입니다. 마지막으로 DeepSeek LLM의 현재 한계점과 향후 연구 방향에 대해 논의합니다.
DeepSeek LLM의 데이터셋 구축 과정은 데이터의 풍부성과 다양성을 포괄적으로 향상시키는 것을 주요 목표로 삼았습니다. 이를 위해 연구진은 Gao와 연구진, Touvron과 연구진 등의 선행 연구에서 얻은 통찰을 바탕으로 세 가지 핵심 단계를 설계했습니다. 중복 제거(deduplication), 필터링(filtering), 그리고 재혼합(remixing)입니다.
중복 제거 단계에서는 특히 공격적인 전략을 채택했습니다. 기존의 접근 방식과 달리 단일 덤프 내에서의 중복 제거를 넘어, Common Crawl 전체 코퍼스를 대상으로 중복을 제거했습니다. 이러한 확장된 중복 제거 범위는 상당한 효과를 보였는데, 실험 결과에 따르면 91개의 덤프에 걸친 중복 제거는 단일 덤프 방식에 비해 4배 더 많은 문서를 제거할 수 있었습니다. 구체적으로, 사용된 덤프의 수가 1개에서 91개로 증가함에 따라 중복 제거율은 22.2%에서 89.8%까지 점진적으로 증가했습니다.
필터링 단계에서는 문서의 품질을 평가하기 위한 엄격한 기준을 개발했습니다. 이 과정에서는 언어적 평가와 의미론적 평가를 모두 포함하는 상세한 분석을 수행했으며, 개별 문서 수준과 전체 데이터셋 수준 모두에서 데이터 품질을 평가했습니다.
재혼합 단계에서는 데이터의 불균형을 해소하는 데 중점을 두었습니다. 특히 과소 대표된 도메인의 비중을 높이는 데 초점을 맞추어, 더욱 균형 잡히고 포용적인 데이터셋을 구축하고자 했습니다.
토크나이저 구현에 있어서는 Huggingface Team이 개발한 tokenizers 라이브러리를 기반으로 바이트 수준 바이트-페어 인코딩(BBPE) 알고리즘을 채택했습니다. GPT-2의 접근 방식을 따라, 개행 문자, 문장 부호, 한중일(CJK) 기호와 같은 서로 다른 문자 범주 간의 토큰 병합을 방지하기 위해 사전 토크나이징을 적용했습니다. 또한 Touvron과 연구진의 방식을 따라 숫자를 개별 자릿수로 분할하는 방식을 채택했습니다.
토크나이저의 어휘 크기는 기존 경험을 바탕으로 100,000개의 일반 토큰으로 설정했으며, 약 24GB 규모의 다국어 코퍼스에서 학습을 진행했습니다. 여기에 15개의 특수 토큰을 추가하여 최종 어휘 크기는 100,015가 되었습니다. 학습 시의 계산 효율성을 고려하고 향후 추가될 수 있는 특수 토큰을 위한 여유 공간을 확보하기 위해, 모델의 어휘 크기는 102,400으로 설정했습니다.
DeepSeek LLM의 하이퍼파라미터 설정은 3장에서 도출된 연구 결과를 바탕으로 이루어졌습니다. 모델의 미시적 설계는 기본적으로 LLaMA 모델의 구조를 따르고 있는데, 이는 Touvron과 연구진이 제안한 효율적이고 검증된 아키텍처를 기반으로 하고 있습니다. 구체적으로, Pre-Norm 구조를 채택하여 각 트랜스포머 서브레이어의 입력에 Zhang과 연구진이 제안한 RMSNorm 정규화 함수를 적용합니다. 이는 기존의 LayerNorm과 비교하여 계산 효율성을 개선하면서도 모델의 안정성을 유지하는 장점이 있습니다.
피드포워드 네트워크(FFN)의 활성화 함수로는 Shazeer가 제안한 SwiGLU를 사용하며, 중간 레이어의 차원은 \(\frac{8}{3}d_{model}\)로 설정됩니다. 여기서 \(d_{model}\)은 모델의 기본 차원을 나타냅니다. 위치 인코딩을 위해서는 Su와 연구진이 제안한 Rotary Embedding을 도입했는데, 이는 상대적 위치 정보를 효과적으로 인코딩하면서도 시퀀스 길이에 대한 유연성을 제공합니다.
67B 모델의 경우, 추론 비용을 최적화하기 위해 Ainslie와 연구진이 제안한 Grouped-Query Attention(GQA)을 도입했습니다. 이는 전통적인 Multi-Head Attention(MHA)을 대체하는 방식으로, 키와 값 프로젝션을 여러 어텐션 헤드에서 공유함으로써 메모리 사용량을 줄이면서도 성능을 유지할 수 있습니다.
거시적 설계 측면에서 DeepSeek LLM은 기존 모델들과 약간의 차이를 보입니다. DeepSeek LLM 7B는 30개의 레이어로 구성되어 있으며, 67B 모델은 95개의 레이어를 가집니다. 이러한 레이어 구성은 다른 오픈소스 모델들과의 파라미터 일관성을 유지하면서도, 모델 파이프라인 분할을 통한 학습과 추론 최적화를 용이하게 합니다.
특히 주목할 만한 점은, GQA를 사용하는 대부분의 연구들이 FFN 레이어의 중간 너비를 확장하는 방식을 택한 것과 달리, DeepSeek LLM 67B 모델에서는 네트워크의 깊이를 확장하는 방식을 선택했다는 것입니다. 이는 더 나은 성능을 달성하기 위한 전략적 선택이었으며, 자세한 네트워크 사양은 표 2에서 확인할 수 있습니다.
DeepSeek LLM의 초기화와 학습 과정에서는 세심하게 조정된 하이퍼파라미터 설정이 적용되었습니다. 모델은 0.006의 표준편차로 초기화되었으며, Loshchilov와 연구진이 제안한 AdamW 옵티마이저를 사용하여 학습을 진행했습니다. AdamW의 주요 하이퍼파라미터로는 \(\beta_1=0.9\), \(\beta_2=0.95\), 그리고 \(\text{weight\_decay}=0.1\)이 설정되었습니다.
특히 주목할 만한 점은 사전학습 과정에서 일반적으로 사용되는 코사인 스케줄러 대신 다단계 학습률 스케줄러를 채택했다는 것입니다. 이 스케줄러는 세 단계로 구성되어 있습니다. 첫째, 2000 스텝의 웜업 기간 동안 학습률이 최대값까지 점진적으로 증가합니다. 둘째, 전체 학습 토큰의 80%를 처리한 시점에서 학습률이 최대값의 31.6%로 감소합니다. 마지막으로, 90%의 토큰을 처리한 후에는 학습률이 최대값의 10%로 더욱 감소합니다. 학습 과정에서의 그래디언트 클리핑은 1.0으로 설정되었습니다.
연구진의 실험 결과에 따르면, 손실 감소 패턴에는 차이가 있지만 다단계 학습률 스케줄러를 사용했을 때의 최종 성능은 코사인 스케줄러와 비교하여 대등한 수준을 보여주었습니다. 이는 첨부된 그래프에서 확인할 수 있습니다.
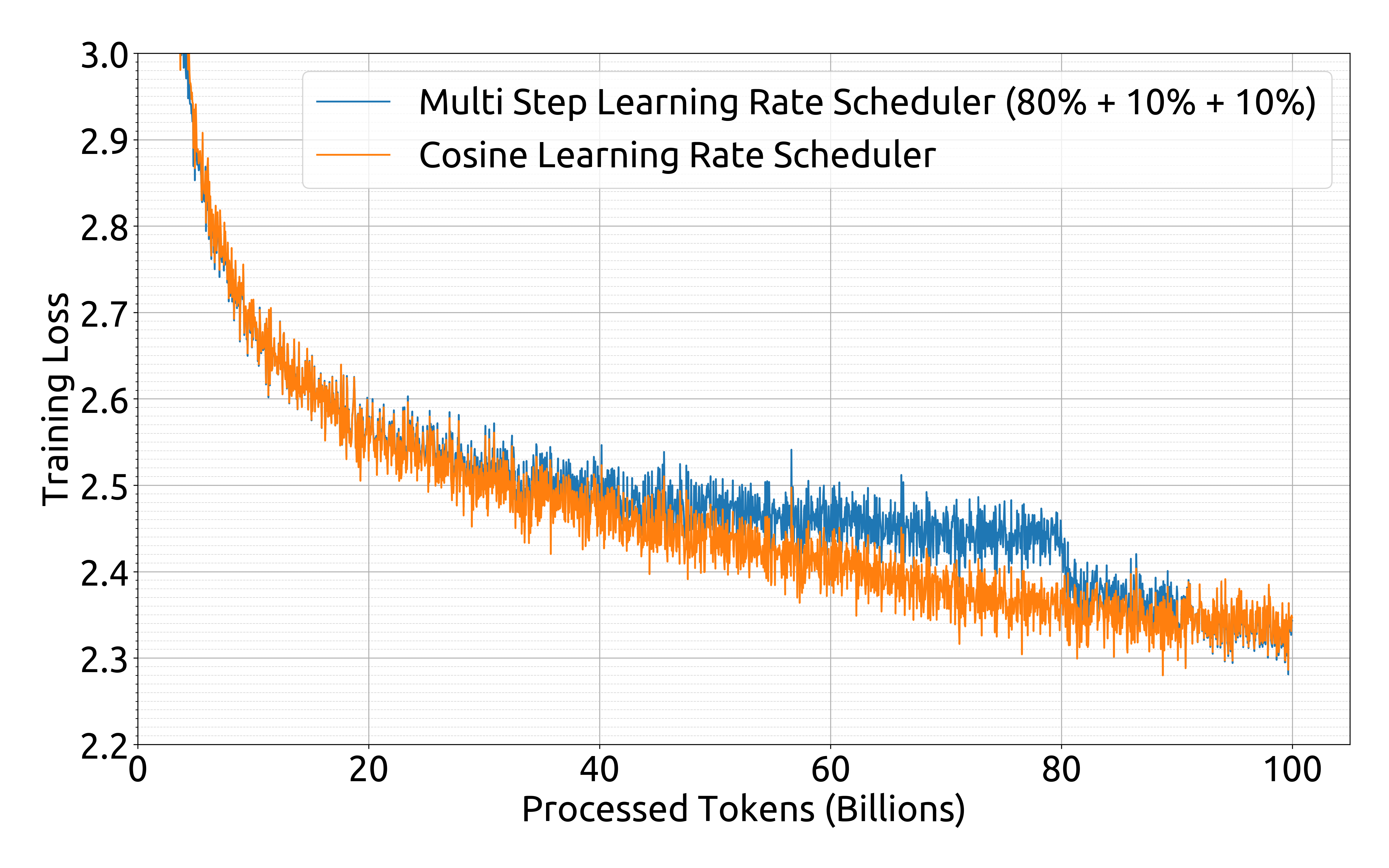
다단계 학습률 스케줄러의 주요 장점은 모델 크기를 고정한 상태에서 학습 규모를 조정할 때 첫 번째 단계의 학습 결과를 재사용할 수 있다는 점입니다. 이러한 실용적인 이점으로 인해 연구진은 다단계 학습률 스케줄러를 기본 설정으로 채택했습니다.
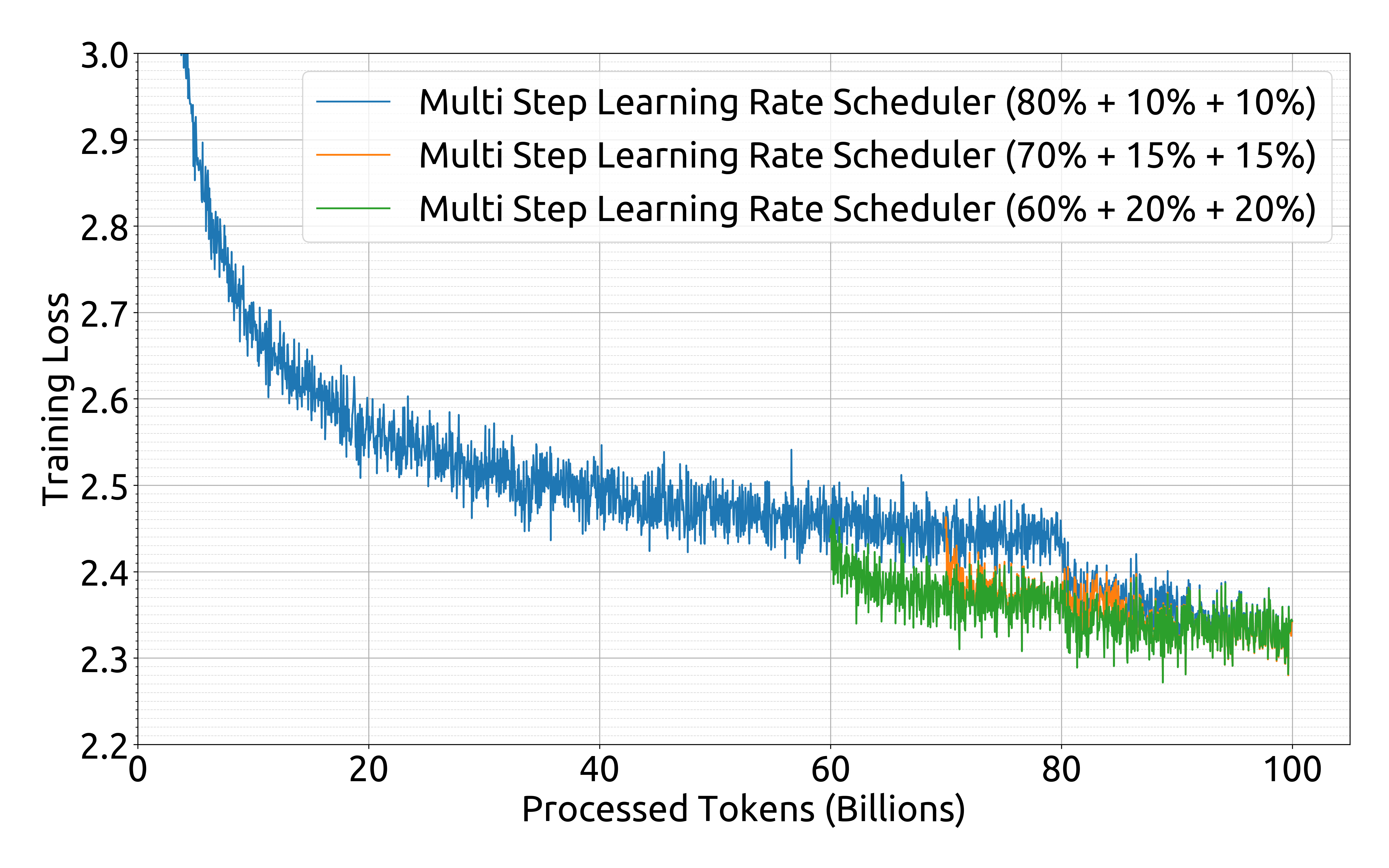
추가적인 실험을 통해 다단계 스케줄러의 각 단계 비율을 조정함으로써 약간의 성능 향상을 얻을 수 있다는 것이 확인되었습니다. 그러나 연구진은 지속적 학습에서의 재사용 비율과 모델 성능 사이의 균형을 고려하여, 앞서 언급한 80%, 10%, 10%의 단계별 비율을 최종적으로 채택했습니다. 이러한 선택은 McCandlish와 연구진이 제시한 대규모 배치 학습에 대한 실증적 모델의 통찰과도 일치하는 것으로, 학습 과정의 효율성과 안정성을 동시에 확보할 수 있게 해줍니다.
DeepSeek LLM의 학습과 평가를 위해 연구진은 HAI-LLM이라는 효율적이고 경량화된 학습 프레임워크를 활용했습니다. 이 프레임워크는 Shoeybi와 연구진이 Megatron에서 제안한 여러 병렬화 기법들을 통합적으로 구현하고 있습니다. 구체적으로, 데이터 병렬화(Data Parallelism), 텐서 병렬화(Tensor Parallelism), 시퀀스 병렬화(Sequence Parallelism), 그리고 1F1B(One-Forward-One-Backward) 파이프라인 병렬화를 포함하고 있습니다.
하드웨어 활용도를 높이기 위해 Dao와 연구진이 제안한 플래시 어텐션(Flash Attention) 기법을 도입했습니다. 이 기술은 어텐션 연산 과정에서 메모리 접근을 최적화하여 계산 효율성을 크게 향상시킵니다. 또한 Rajbhandari와 연구진이 개발한 ZeRO-1(Zero Redundancy Optimizer) 기법을 적용하여 데이터 병렬 랭크 간에 옵티마이저 상태를 분할함으로써 메모리 사용량을 효율적으로 관리합니다.
연산과 통신의 오버랩을 최대화하기 위해 여러 최적화 기법들이 적용되었습니다. 마지막 마이크로배치의 역전파 과정과 ZeRO-1의 reduce-scatter 연산을 오버랩하고, 시퀀스 병렬화에서 GEMM 연산과 all-gather/reduce-scatter 통신을 오버랩하여 대기 시간을 최소화했습니다.
학습 속도를 향상시키기 위해 여러 레이어와 연산자들을 융합했습니다. LayerNorm, 가능한 경우의 GEMM(General Matrix Multiplication), 그리고 Adam 업데이트 연산들이 이에 포함됩니다. 모델 학습의 안정성을 높이기 위해 bf16 정밀도로 학습을 진행하되, 그래디언트는 fp32 정밀도로 누적하는 방식을 채택했습니다.
메모리 사용량을 줄이기 위해 in-place 교차 엔트로피(cross-entropy) 연산을 구현했습니다. 이는 bf16 로짓(logits)을 HBM(High Bandwidth Memory)에서 미리 변환하는 대신, 교차 엔트로피 CUDA 커널 내에서 즉시 fp32로 변환하고 bf16 그래디언트를 계산한 후 로짓을 그래디언트로 덮어쓰는 방식으로 작동합니다.
모델 가중치와 옵티마이저 상태는 5분마다 비동기적으로 저장됩니다. 이는 하드웨어나 네트워크 장애가 발생하더라도 최대 5분의 학습 결과만을 손실하게 됨을 의미합니다. 이러한 임시 체크포인트들은 저장 공간을 과도하게 차지하지 않도록 정기적으로 정리됩니다. 또한 컴퓨팅 클러스터의 부하 변동에 대응하기 위해 서로 다른 3D 병렬 구성에서도 학습을 재개할 수 있도록 설계되었습니다.
평가 단계에서는 Kwon과 연구진이 개발한 vLLM을 생성형 태스크에 활용하고, 비생성형 태스크에서는 연속 배치(continuous batching) 기법을 적용하여 수동적인 배치 크기 조정을 피하고 토큰 패딩을 줄였습니다.
스케일링 법칙 연구
대규모 언어 모델(Large Language Models, LLMs)의 등장 이전부터 스케일링 법칙에 대한 연구는 진행되어 왔습니다. Hestness와 연구진이 초기에 제시한 스케일링 법칙은 컴퓨팅 예산 $C$, 모델 규모 $N$, 그리고 데이터 규모 $D$를 증가시킴에 따라 모델의 성능이 예측 가능한 방식으로 향상될 수 있다는 것을 보여주었습니다. 이때 모델 규모 $N$이 모델 파라미터를 나타내고 데이터 규모 $D$가 토큰의 수를 나타낼 때, 컴퓨팅 예산 $C$는 $C = 6ND$로 근사될 수 있습니다.
따라서 컴퓨팅 예산을 증가시킬 때 모델과 데이터 규모 사이의 최적 할당을 찾는 것이 스케일링 법칙 연구의 중요한 목표가 되었습니다. LLM의 발전과 함께, Dai와 연구진, Radford와 연구진의 연구에서 보여진 것처럼 더 큰 모델이 예상치 못한 현저한 성능 향상을 달성하면서 스케일링 법칙 연구는 새로운 정점을 맞이했습니다.
스케일링 법칙의 연구 결과들은 컴퓨팅 예산을 확장하는 것이 지속적으로 상당한 이점을 가져온다는 것을 보여주었고, 이는 Brown과 연구진, Smith와 연구진의 연구에서 볼 수 있듯이 모델 규모의 증가를 더욱 촉진했습니다. 그러나 최적의 모델/데이터 스케일링 할당 전략에 대한 초기 연구들은 서로 다른 결론을 보여주었고, 이는 스케일링 법칙의 일반적 적용 가능성에 대한 의문을 제기했습니다.
더욱이 이러한 연구들은 종종 하이퍼파라미터 설정에 대한 완전한 설명이 부족했으며, 이로 인해 서로 다른 컴퓨팅 예산에서 모델들이 최적의 성능에 도달했는지 확실하지 않았습니다. 따라서 연구진은 이러한 불확실성을 해결하고 컴퓨팅의 효율적인 스케일업 방법을 확인하기 위해 스케일링 법칙을 재검토했습니다. 이는 장기적 관점을 반영하며 지속적으로 개선되는 모델을 개발하는 데 핵심이 됩니다.
서로 다른 컴퓨팅 예산에서 모델들이 최적의 성능을 달성할 수 있도록 하기 위해, 연구진은 먼저 하이퍼파라미터의 스케일링 법칙을 연구했습니다. 경험적으로, 학습 과정에서 대부분의 파라미터의 최적값은 컴퓨팅 예산이 변할 때도 변하지 않는다는 것이 관찰되었습니다. 따라서 이러한 파라미터들은 앞서 설명한 섹션에서 설명된 것과 동일하게 유지되었습니다. 하지만 성능에 가장 큰 영향을 미치는 하이퍼파라미터인 배치 크기와 학습률에 대해서는 재검토가 필요했습니다. McCandlish와 연구진, Shallue와 연구진, Smith와 연구진, Goyal과 연구진, Zhang과 연구진의 초기 연구들은 배치 크기와 학습률 설정에 대한 경험적 관찰을 제공했지만, 연구진의 예비 실험에서 이러한 관찰들의 적용 가능성이 제한적이라는 것을 발견했습니다.
광범위한 실험을 통해 연구진은 컴퓨팅 예산 $C$와 최적 배치 크기 및 학습률 사이의 멱법칙 관계를 모델링했습니다. 이 관계는 하이퍼파라미터의 스케일링 법칙이라고 불리며, 최적의 하이퍼파라미터를 결정하기 위한 경험적 프레임워크를 제공합니다. 이러한 방법론은 서로 다른 컴퓨팅 예산에서 모델들이 최적에 가까운 성능에 도달할 수 있도록 보장합니다.
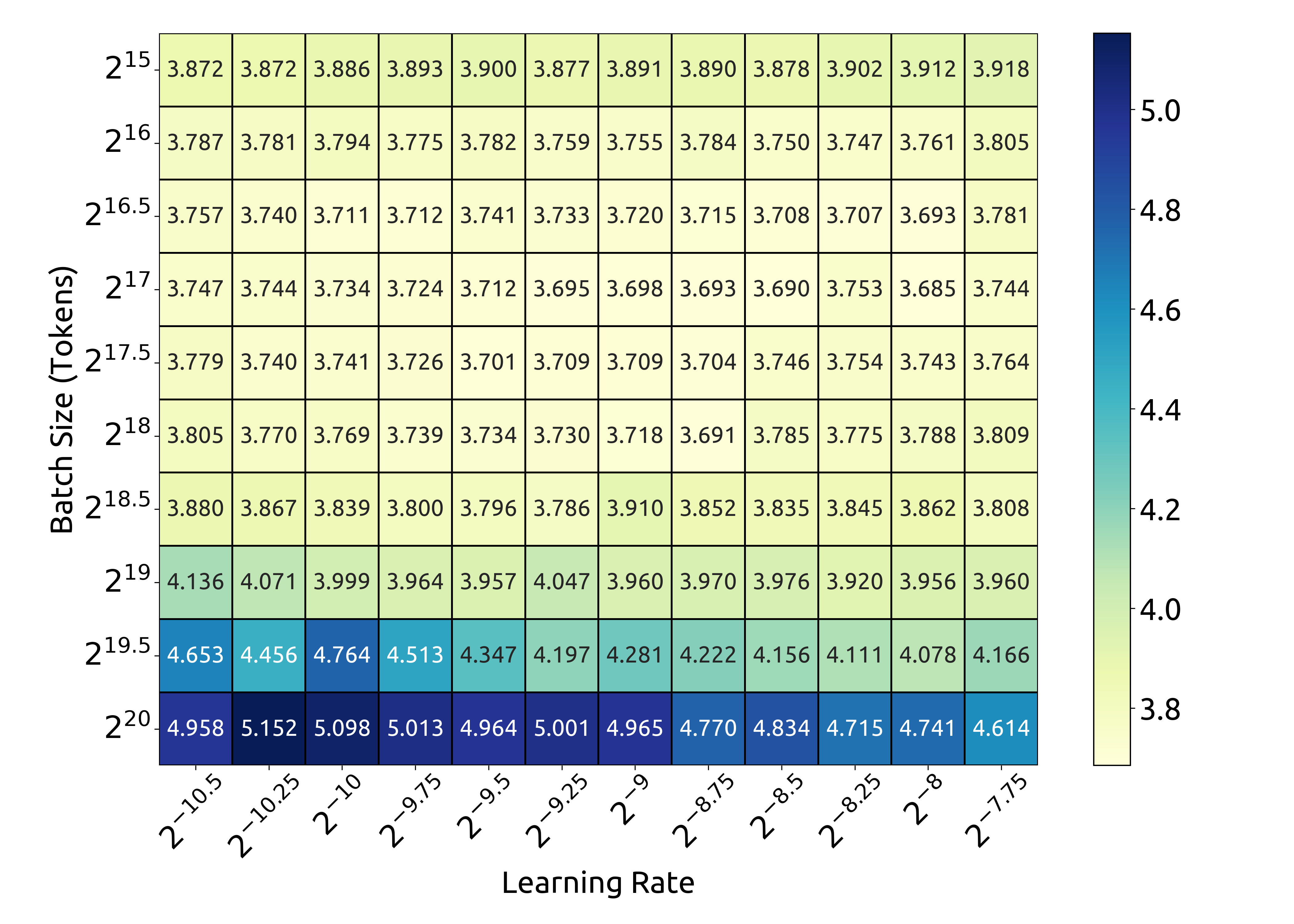
위 그래프는 1e17 FLOPs(177M FLOPs/token)에서의 배치 크기와 학습률에 따른 손실을 보여줍니다. 결과는 배치 크기와 학습률의 선택이 넓은 범위에서 일반화 오차가 안정적으로 유지된다는 것을 보여줍니다. 이는 비교적 넓은 파라미터 공간에서 최적에 가까운 성능을 달성할 수 있다는 것을 의미합니다.
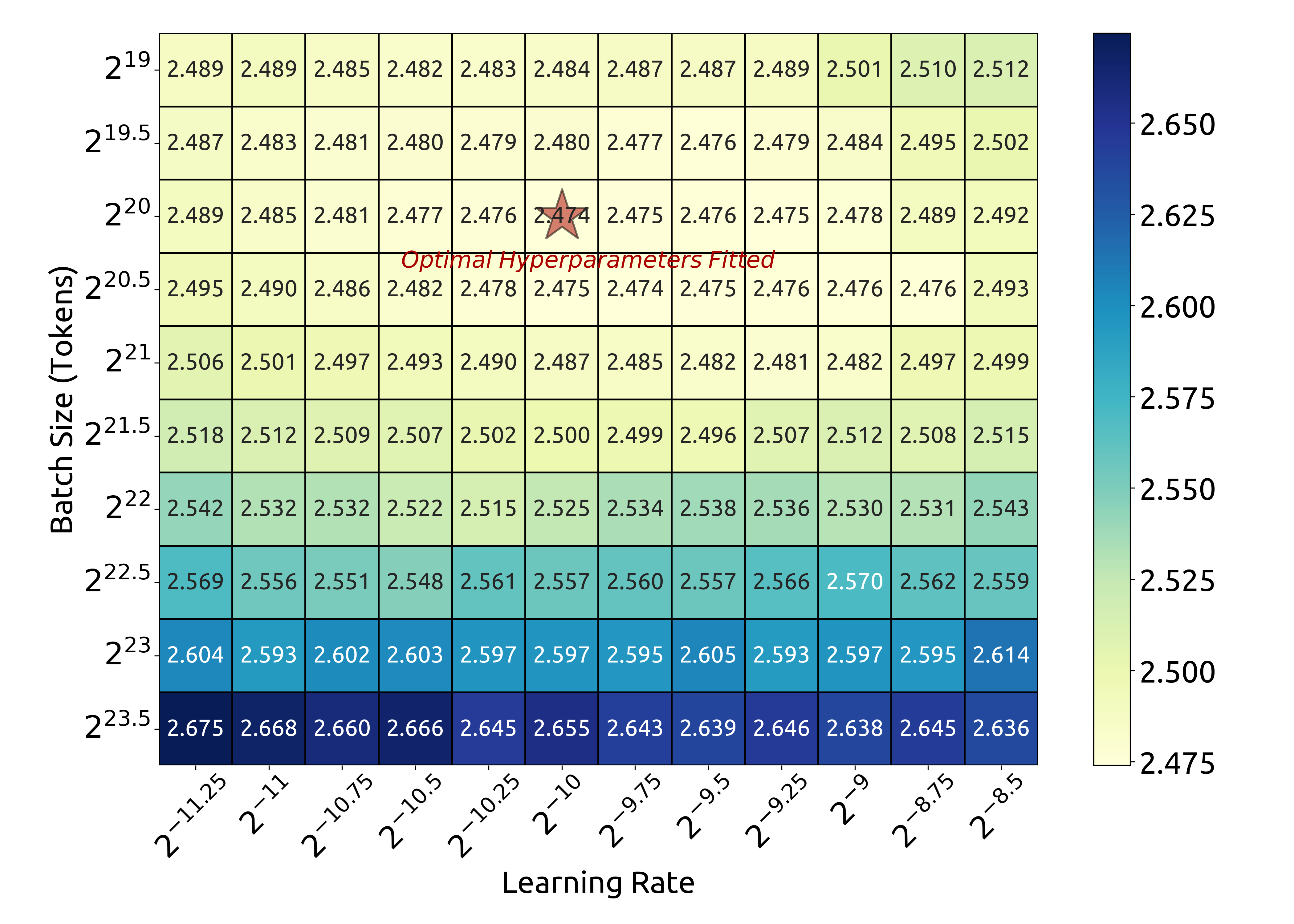
1e20 FLOPs(2.94B FLOPs/token)에서의 실험 결과도 유사한 패턴을 보여줍니다. 이러한 결과들을 바탕으로 연구진은 배치 크기 $B$와 학습률 $\eta$에 대한 다음과 같은 스케일링 법칙을 도출했습니다.
\(\eta_{\mathrm{opt}} = 0.3118\cdot C^{\,-0.1250}\) \(B_{\mathrm{opt}} = 0.2920\cdot C^{\,0.3271}\)
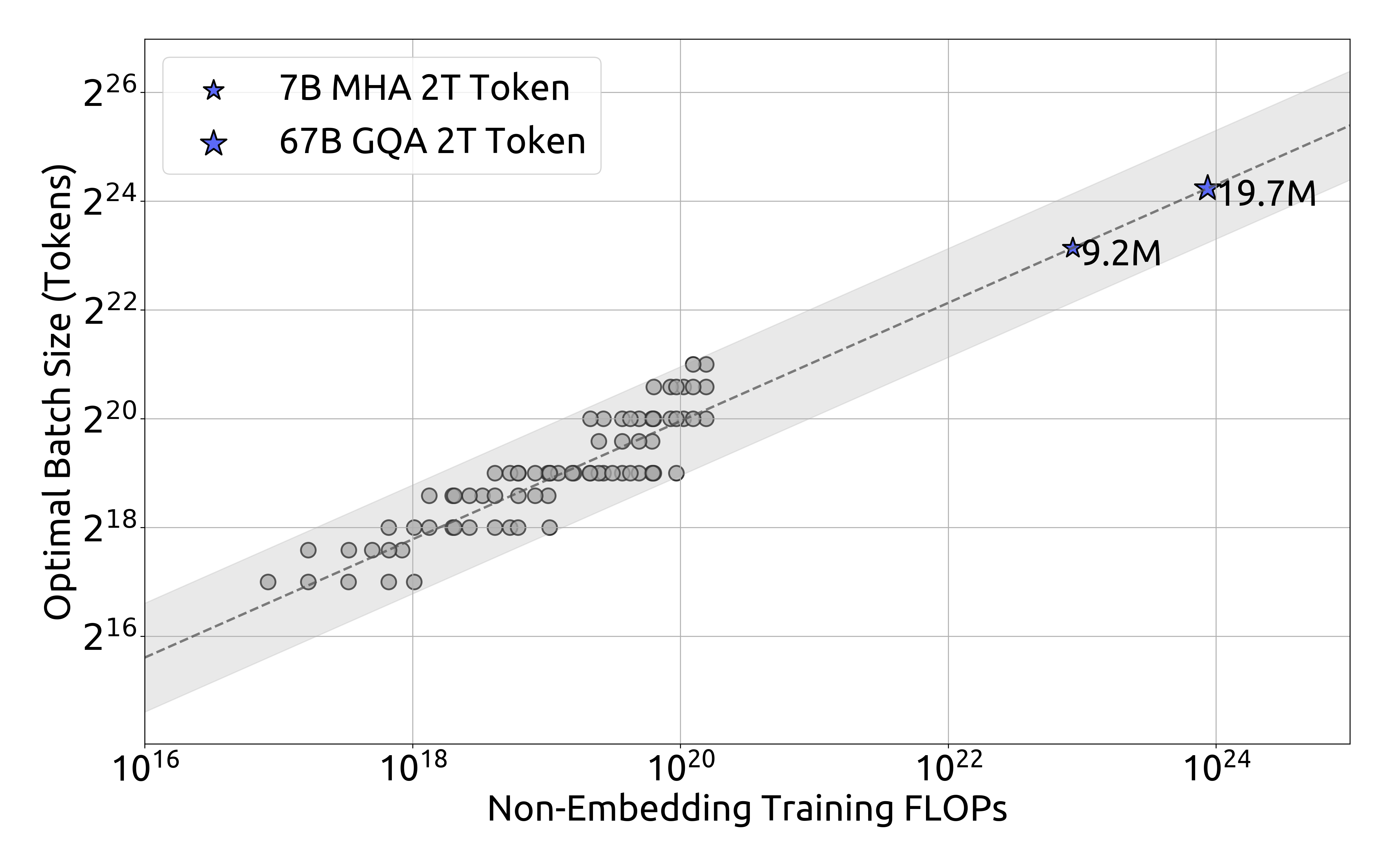
배치 크기 스케일링 곡선은 컴퓨팅 예산이 증가함에 따라 최적 배치 크기가 점진적으로 증가하는 것을 보여줍니다.
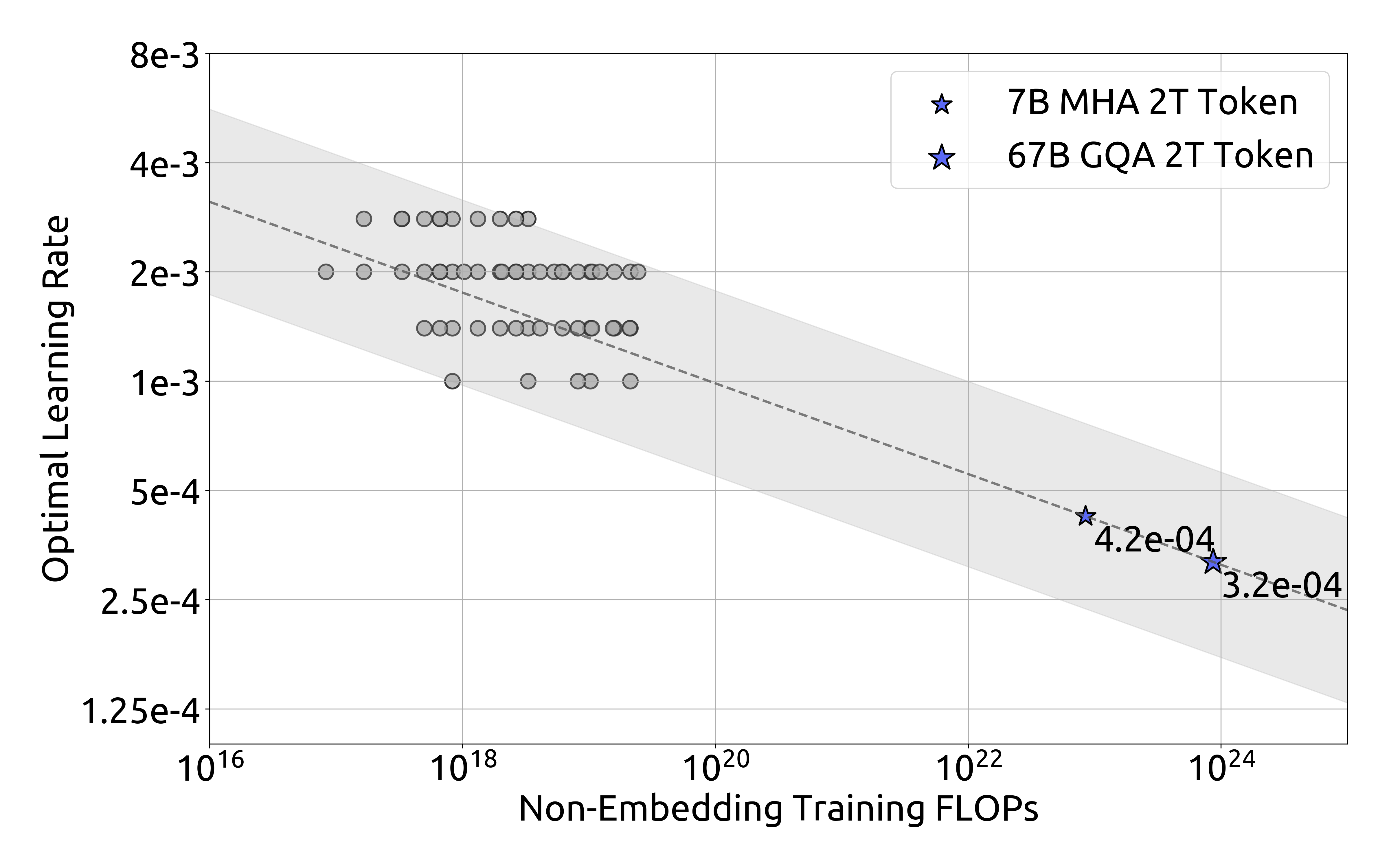
반면 학습률 스케일링 곡선은 컴퓨팅 예산이 증가할수록 최적 학습률이 점진적으로 감소하는 것을 보여줍니다. 이는 더 큰 모델을 학습할 때 배치 크기를 늘리고 학습률을 낮추는 일반적인 경험적 설정과 일치합니다. 더욱이, 모든 최적에 가까운 하이퍼파라미터들이 넓은 밴드 범위 내에 위치한다는 것이 관찰되었습니다. 이는 이 구간 내에서 최적에 가까운 파라미터를 선택하는 것이 비교적 용이하다는 것을 시사합니다. 연구진이 도출한 스케일링 법칙은 DeepSeek LLM 7B와 67B 모델에서도 좋은 성능을 달성했습니다.
그러나 연구진은 아직 컴퓨팅 예산 $C$ 이외의 요소들이 최적 하이퍼파라미터에 미치는 영향을 완전히 고려하지 못했다는 점을 지적합니다. 이는 최적 배치 크기가 일반화 오차 $L$에만 관련되어 있다고 제안한 McCandlish와 연구진, Kaplan과 연구진의 이전 연구들과는 일치하지 않는 부분입니다.
특히 주목할 만한 점은, 동일한 컴퓨팅 예산을 가진 모델들 사이에서도 모델/데이터 할당이 다른 경우 최적 파라미터 공간이 약간씩 달라진다는 것을 발견했다는 것입니다. 이는 하이퍼파라미터 선택과 학습 동역학에 대한 더 깊은 이해가 필요하다는 것을 시사합니다.
연구진은 하이퍼파라미터에 대한 스케일링 법칙을 도출한 후, 모델과 데이터 스케일링의 최적화에 대한 연구를 진행했습니다. 이는 모델 스케일링 지수 $a$와 데이터 스케일링 지수 $b$를 찾는 것을 포함하며, 이들은 각각 $N_{\mathrm{opt}}\propto C^{a}$와 $D_{\mathrm{opt}}\propto C^{b}$를 만족합니다.
데이터 규모 $D$는 일관되게 데이터셋의 토큰 수로 표현될 수 있습니다. 그러나 이전 연구들에서는 모델 규모를 주로 모델 파라미터로 표현했으며, 이는 비임베딩 파라미터 $N_1$(Kaplan과 연구진)과 전체 파라미터 $N_2$(Hoffmann과 연구진)의 두 가지 방식으로 나뉩니다. 컴퓨팅 예산 $C$와 모델/데이터 규모의 관계는 $C=6ND$로 근사될 수 있었고, 이는 $6N_1$ 또는 $6N_2$를 모델 규모의 근사치로 사용할 수 있음을 의미했습니다.
그러나 $6N_1$과 $6N_2$ 모두 어텐션 연산의 계산 오버헤드를 고려하지 않으며, $6N_2$는 모델의 용량에 상대적으로 적은 기여를 하는 어휘 계산도 포함한다는 문제가 있습니다. 이로 인해 특정 설정에서 상당한 근사 오차가 발생할 수 있습니다. 이러한 근사 오차를 줄이기 위해 연구진은 비임베딩 FLOPs/토큰 $M$이라는 새로운 모델 규모 표현 방식을 도입했습니다. $M$은 어텐션 연산의 계산 오버헤드를 포함하면서도 어휘 계산은 제외합니다. $M$을 사용하여 모델 규모를 표현할 경우, 컴퓨팅 예산 $C$는 간단히 $C=MD$로 표현될 수 있습니다.
$6N_1$, $6N_2$, 그리고 $M$ 사이의 구체적인 차이는 다음과 같은 수식으로 표현됩니다.
\(6N_{1} = 72\,n_{\mathrm{layer}}\,d_{\mathrm{model}}^{2}\) \(6N_{2} = 72\,n_{\mathrm{layer}}\,d_{\mathrm{model}}^{2}+6\,n_{\mathrm{vocab}}\,d_{\mathrm{model}}\) \(M = 72\,n_{\mathrm{layer}}\,d_{\mathrm{model}}^{2}+12\,n_{\mathrm{layer}}\,d_{\mathrm{model}}\,l_{\mathrm{seq}}\)
여기서 $n_{\mathrm{layer}}$는 레이어 수, $d_{\mathrm{model}}$은 모델 너비, $n_{\mathrm{vocab}}$은 어휘 크기, 그리고 $l_{\mathrm{seq}}$는 시퀀스 길이를 나타냅니다.
연구진은 다양한 규모의 모델들에 대해 이 세 가지 표현 방식의 차이를 평가했습니다. 결과는 $6N_1$과 $6N_2$ 모두 서로 다른 규모의 모델에서 계산 비용을 과대 또는 과소 추정한다는 것을 보여주었습니다. 이러한 불일치는 특히 소규모 모델에서 두드러졌으며, 차이가 최대 50%까지 달했습니다. 이러한 큰 차이는 스케일링 곡선을 피팅할 때 상당한 통계적 오차를 초래할 수 있습니다.
$M$을 모델 규모의 표현으로 채택한 후, 연구진의 목표는 더욱 명확해졌습니다. 주어진 컴퓨팅 예산 $C=MD$에 대해, 모델의 일반화 오차를 최소화하는 최적의 모델 규모 $M_{\mathrm{opt}}$와 데이터 규모 $D_{\mathrm{opt}}$를 찾는 것입니다. 이는 다음과 같은 수식으로 형식화될 수 있습니다.
\[M_{\mathrm{opt}}(C),D_{\mathrm{opt}}(C)=\underset{M,D\,\mathrm{s.t.}\,C=MD}{\mathrm{argmin}}L(N,D)\]실험 비용과 피팅의 어려움을 줄이기 위해, 연구진은 Chinchilla에서 사용된 IsoFLOP 프로파일 접근 방식을 채택했습니다. 1e17에서 3e20까지 8개의 서로 다른 컴퓨팅 예산을 선택하고, 각 예산에 대해 약 10개의 서로 다른 모델/데이터 규모 할당을 설계했습니다. 각 예산에 대한 하이퍼파라미터는 앞서 도출된 수식(1)을 통해 결정되었으며, 일반화 오차는 학습 세트와 유사한 분포를 가진 100M 토큰의 독립적인 검증 세트에서 계산되었습니다. 연구진은 IsoFLOP 곡선과 모델/데이터 스케일링 곡선을 피팅했으며, 이는 각 컴퓨팅 예산에 대한 최적의 모델/데이터 할당을 사용하여 도출되었습니다.
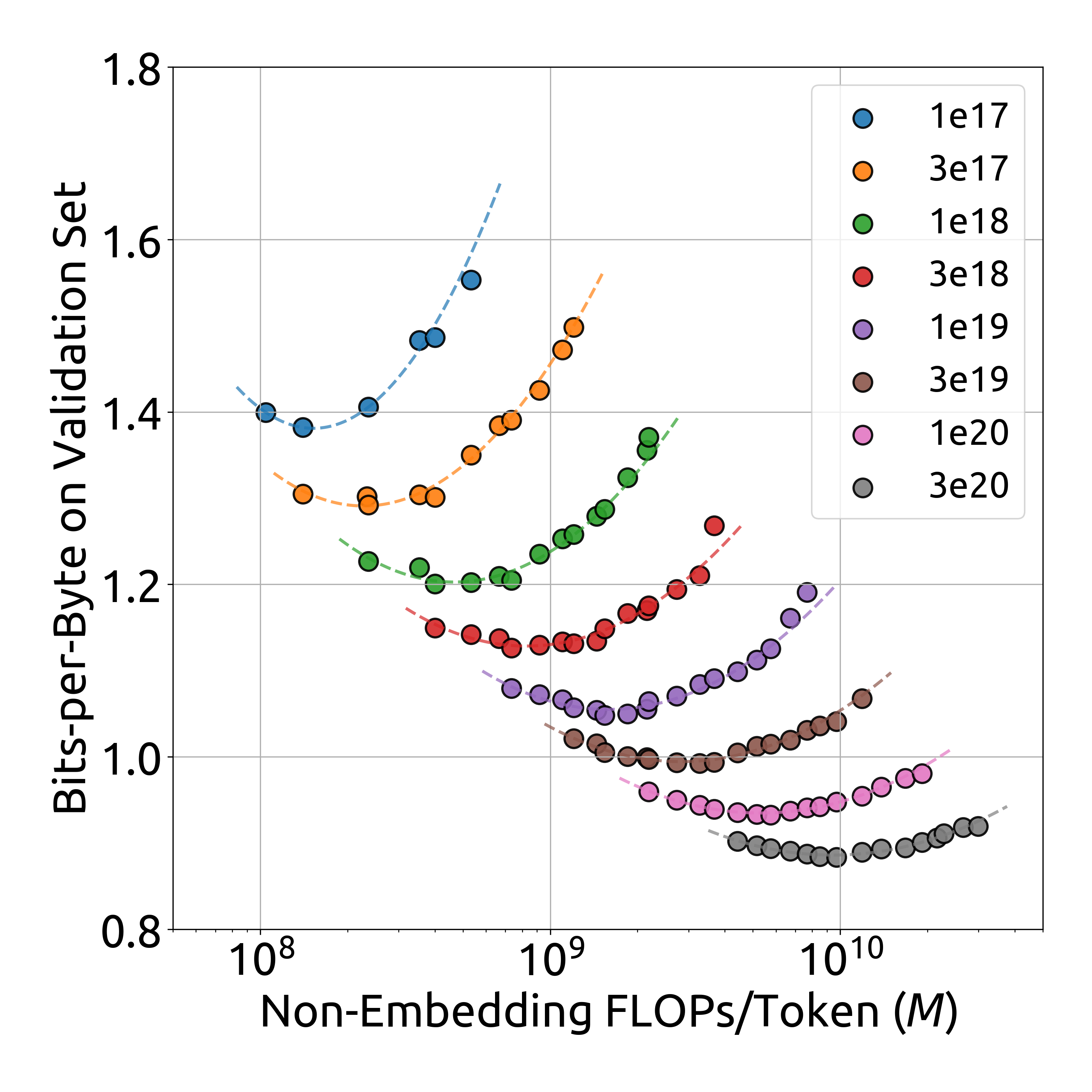
IsoFLOP 곡선은 모델 크기(비임베딩 FLOPs/토큰)와 검증 세트에서의 성능(Bits-per-Byte) 간의 관계를 보여줍니다. 이 곡선을 통해 모델 크기 증가에 따른 성능 향상을 명확하게 확인할 수 있습니다.
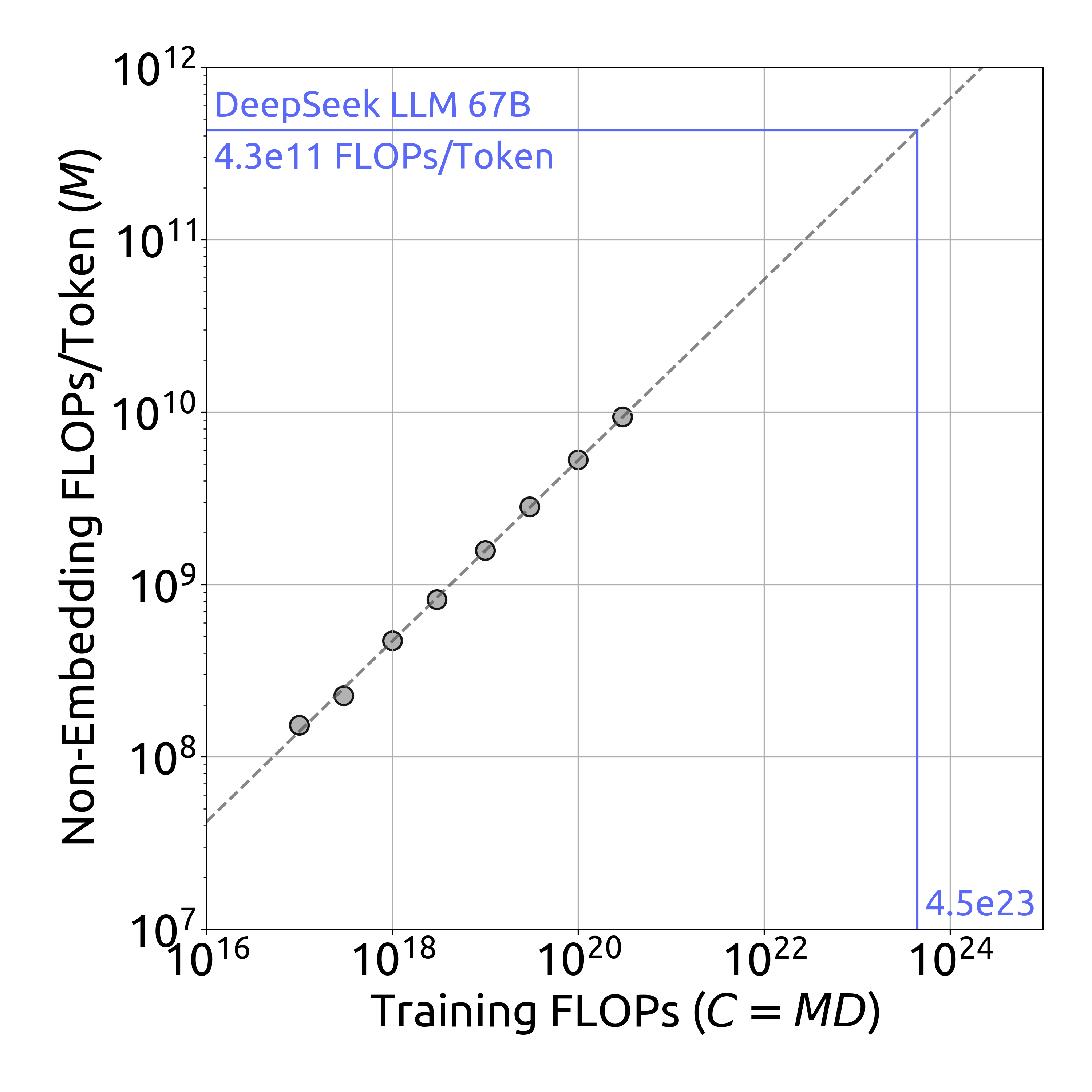
최적 모델 스케일링 곡선은 학습 FLOPs가 증가함에 따라 비임베딩 FLOPs/토큰이 어떻게 증가하는지를 보여줍니다. DeepSeek LLM 67B 모델의 경우 4.3e11 FLOPs/토큰에 도달하는 것을 확인할 수 있습니다.
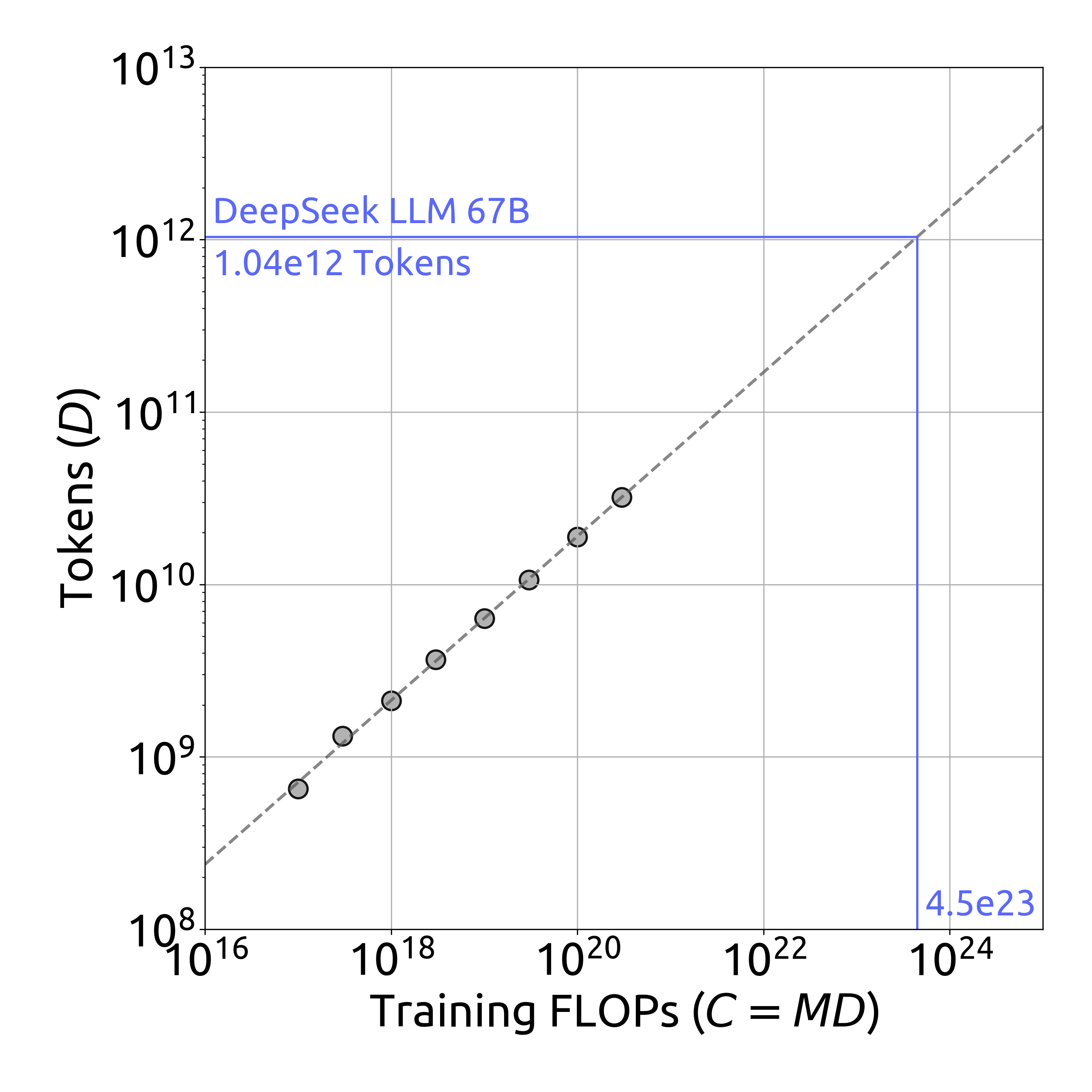
최적 데이터 스케일링 곡선은 학습 FLOPs 증가에 따른 토큰 수의 변화를 보여줍니다. DeepSeek LLM 67B 모델은 약 1.04e12 토큰까지 확장되었습니다.
최적의 비임베딩 FLOPs/토큰 $M_{\mathrm{opt}}$와 최적의 토큰 수 $D_{\mathrm{opt}}$에 대한 구체적인 수식은 다음과 같습니다.
\(M_{\mathrm{opt}} = M_{\mathrm{base}}\cdot C^{a}, \;M_{\mathrm{base}}=0.1715, \;a=0.5243\) \(D_{\mathrm{opt}} = D_{\mathrm{base}}\cdot C^{b}, \;D_{\mathrm{base}}=5.8316, \;b=0.4757\)
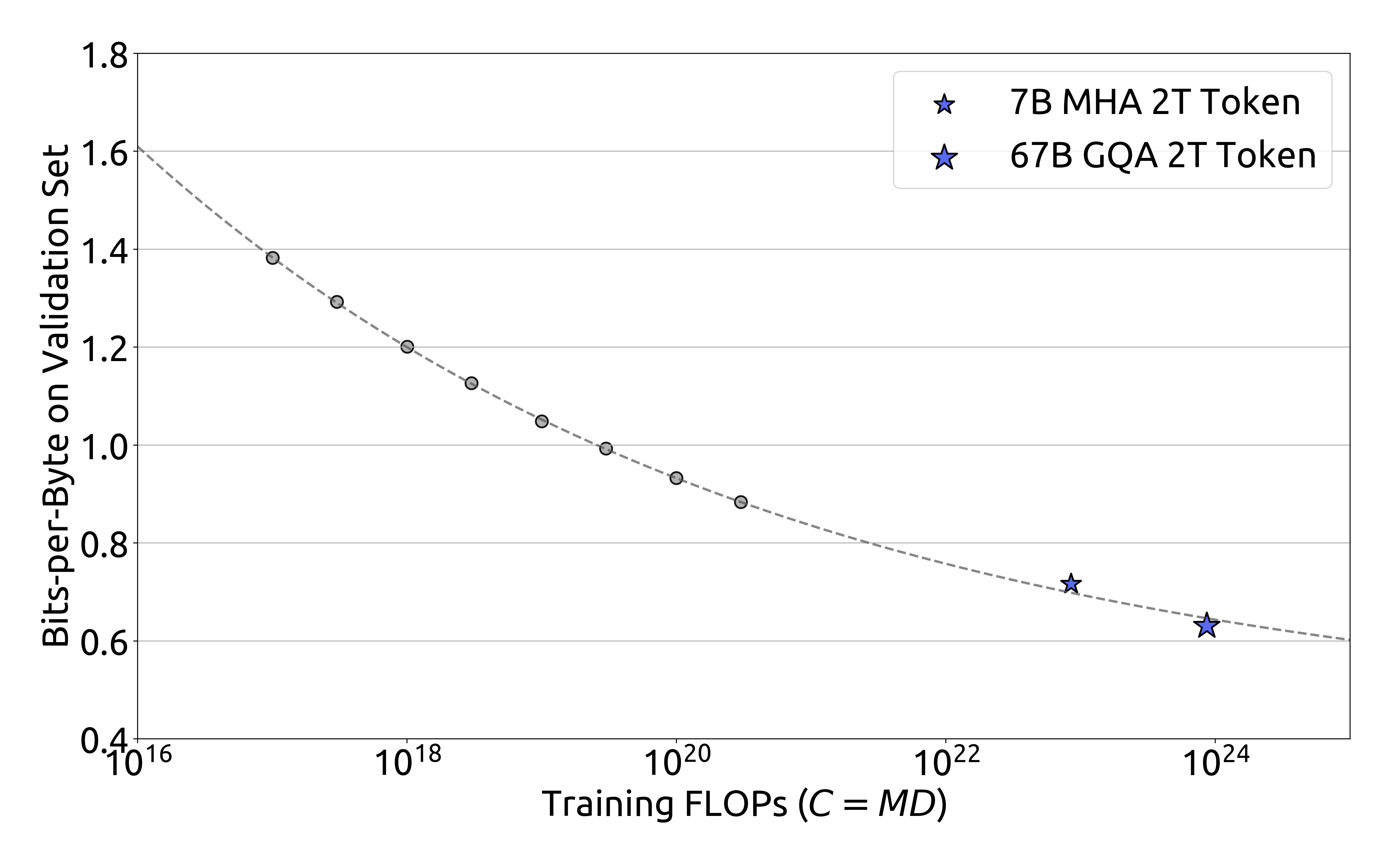
추가적으로 연구진은 컴퓨팅 예산 $C$와 최적 일반화 오차에 따른 손실 스케일링 곡선을 피팅하고, DeepSeek LLM 7B와 67B의 일반화 오차를 예측했습니다. 결과는 작은 규모의 실험을 통해 1000배 더 큰 컴퓨팅 예산을 가진 모델의 성능을 정확하게 예측할 수 있다는 것을 보여줍니다. 이는 더 큰 규모의 모델을 학습하는 데 있어 중요한 지침과 확신을 제공합니다. DeepSeek LLM의 개발 과정에서 데이터셋은 여러 차례 반복적으로 개선되었으며, 이 과정에서 서로 다른 데이터 소스의 비율을 조정하고 전반적인 품질을 향상시켰습니다. 이를 통해 연구진은 서로 다른 데이터셋이 스케일링 법칙에 미치는 영향을 더욱 심도 있게 분석할 수 있었습니다.
연구진은 세 가지 서로 다른 데이터셋에 대해 스케일링 법칙을 연구했습니다. 초기 자체 데이터, 현재 자체 데이터, 그리고 이전 스케일링 법칙 연구에서 사용된 OpenWebText2입니다. 내부 데이터 평가 결과, 현재 자체 데이터는 초기 자체 데이터보다 더 높은 데이터 품질을 보여주었습니다. 더욱이 OpenWebText2는 더 작은 규모로 인해 더욱 세밀한 처리가 가능했기 때문에, 현재 자체 데이터보다도 더 높은 품질을 보여주었습니다.
분석 결과에서 가장 흥미로운 발견은 이 세 가지 데이터셋에서의 최적 모델/데이터 스케일링 할당 전략이 데이터 품질과 일관된 관계를 보여주었다는 점입니다. 데이터 품질이 향상됨에 따라 모델 스케일링 지수 $a$는 점진적으로 증가하고 데이터 스케일링 지수 $b$는 감소하는 것으로 나타났습니다. 이는 증가된 컴퓨팅 예산을 데이터보다는 모델 스케일링에 더 많이 할당해야 한다는 것을 의미합니다.
이러한 현상에 대한 직관적인 설명은 고품질 데이터가 일반적으로 논리적 명확성을 가지고 있으며, 충분한 학습 후에는 예측의 어려움이 줄어든다는 것입니다. 따라서 컴퓨팅 예산이 증가할 때 모델 크기를 확장하는 것이 더 유리합니다. 이러한 발견은 또한 스케일링 법칙에 대한 초기 연구들에서 관찰된 최적 모델/데이터 스케일링 할당의 큰 차이를 설명할 수 있는 단서를 제공합니다.
연구진은 데이터 품질의 변화와 이것이 스케일링 법칙에 미치는 영향에 대해 지속적으로 주목할 예정이며, 향후 연구에서 더 많은 분석을 제공할 계획입니다. 이러한 연구는 대규모 언어 모델의 효율적인 학습을 위한 중요한 지침을 제공할 것으로 기대됩니다.
모델 정렬 및 미세조정
DeepSeek LLM의 모델 정렬 과정에서는 영어와 중국어로 약 150만 개의 지시 데이터를 수집했습니다. 이 데이터는 유용성과 안전성이라는 두 가지 주요 측면을 포괄적으로 다루고 있습니다. 유용성 관련 데이터는 총 120만 개의 인스턴스로 구성되어 있으며, 일반 언어 과제(31.2%), 수학 문제(46.6%), 코딩 연습(22.2%)의 세 가지 주요 카테고리로 분류됩니다. 안전성 관련 데이터는 30만 개의 인스턴스를 포함하며, 다양한 민감한 주제들을 다루고 있습니다.
DeepSeek LLM의 정렬 파이프라인은 지도 학습 미세조정(Supervised Fine-Tuning, SFT)과 직접 선호도 최적화(Direct Preference Optimization, DPO)의 두 단계로 구성됩니다. SFT 단계에서는 모델 크기에 따라 서로 다른 학습 전략을 적용했습니다. 7B 모델의 경우 4번의 에포크 동안 학습을 진행했으나, 67B 모델은 과적합 문제가 심각하게 나타나 2번의 에포크만 진행했습니다. 학습률 또한 모델 크기에 따라 차별화되어, 7B 모델은 1e-5, 67B 모델은 5e-6으로 설정되었습니다.
연구진은 GSM8K와 HumanEval 벤치마크를 통해 모델의 성능을 지속적으로 모니터링했습니다. 7B 모델의 경우 이러한 벤치마크에서 꾸준한 성능 향상을 보였으나, 67B 모델은 빠르게 상한선에 도달하는 것이 관찰되었습니다. 이는 Cobbe와 연구진, Chen과 연구진이 각각 개발한 수학적 추론과 코드 생성 능력 평가 벤치마크에서 확인된 결과입니다.
특히 주목할 만한 점은 채팅 모델의 반복 비율(repetition ratio) 모니터링입니다. 연구진은 3,868개의 중국어와 영어 프롬프트를 수집하여, 생성된 응답이 종료되지 않고 텍스트 시퀀스를 무한히 반복하는 비율을 측정했습니다. 수학 관련 SFT 데이터의 양이 증가함에 따라 반복 비율이 증가하는 경향이 관찰되었는데, 이는 수학 SFT 데이터에 유사한 추론 패턴이 포함되어 있기 때문입니다. 상대적으로 성능이 낮은 모델들은 이러한 추론 패턴을 제대로 이해하지 못해 반복적인 응답을 생성하는 것으로 분석되었습니다.
이러한 반복 문제를 해결하기 위해 연구진은 두 가지 접근 방식을 시도했습니다. 첫째는 2단계 미세조정 방식이고, 둘째는 Rafailov와 연구진이 제안한 DPO 방식입니다. 두 방법 모두 벤치마크 점수를 거의 유지하면서도 반복 비율을 크게 감소시킬 수 있었습니다.
DPO 단계에서는 유용성과 안전성 측면에서의 선호도 데이터를 구축했습니다. 유용성 데이터의 경우, 창의적 글쓰기, 질의응답, 지시 따르기 등 다양한 카테고리를 포함하는 다국어 프롬프트를 수집했습니다. 이러한 프롬프트에 대해 DeepSeek Chat 모델을 사용하여 응답 후보들을 생성했으며, 안전성 선호도 데이터 구축에도 유사한 방식이 적용되었습니다.
DPO 학습은 1 에포크 동안 진행되었으며, 5e-6의 학습률과 512의 배치 크기를 사용했습니다. 또한 학습률 웜업과 코사인 학습률 스케줄러를 적용했습니다. 연구 결과, DPO는 표준 벤치마크에서의 성능에는 큰 영향을 미치지 않으면서도 모델의 개방형 생성 능력을 강화할 수 있다는 것이 확인되었습니다.
모델 평가 결과
DeepSeek LLM의 성능을 평가하기 위해 연구진은 영어와 중국어 모두에서 다양한 공개 벤치마크를 활용했습니다. 평가는 크게 다음과 같은 주요 카테고리로 구성되었습니다.
먼저 다중 주제 객관식 데이터셋으로, Hendrycks와 연구진이 개발한 MMLU, Huang과 연구진의 C-Eval, 그리고 Li와 연구진의 CMMLU가 포함됩니다. 이러한 데이터셋들은 모델의 광범위한 지식과 이해도를 평가하는데 중점을 둡니다.
언어 이해와 추론 능력 평가를 위해서는 HellaSwag, PIQA, ARC, OpenBookQA, 그리고 BBH와 같은 데이터셋이 활용되었습니다. 특히 BBH는 Suzgun과 연구진이 제안한 것으로, 모델의 고난도 추론 능력을 평가하는데 초점을 맞추고 있습니다.
폐쇄형 질의응답 능력 평가를 위해서는 TriviaQA와 NaturalQuestions가 사용되었으며, 독해력 평가를 위해서는 RACE, DROP, C3와 같은 데이터셋이 활용되었습니다. 또한 참조 모호성 해결 능력을 평가하기 위해 WinoGrande와 CLUEWSC가, 언어 모델링 능력 평가를 위해 Pile이 사용되었습니다.
중국어 이해력과 문화적 지식을 평가하기 위해서는 CHID와 CCPM이 활용되었으며, 수학적 능력 평가를 위해서는 GSM8K, MATH, CMath가 사용되었습니다. 코딩 능력은 HumanEval과 MBPP를 통해 평가되었고, 표준화된 시험 성능은 AGIEval을 통해 측정되었습니다.
평가 방식은 크게 세 가지로 나뉩니다. 첫째, 퍼플렉서티 기반 평가는 여러 선택지 중에서 가장 낮은 퍼플렉서티를 가진 옵션을 모델의 예측으로 선택하는 방식입니다. 이는 HellaSwag, PIQA 등의 객관식 문제에 적용되었습니다. 둘째, 생성 기반 평가는 모델이 자유롭게 텍스트를 생성하고 그 결과를 파싱하는 방식으로, TriviaQA, NaturalQuestions 등에 적용되었습니다. 마지막으로, 언어 모델링 기반 평가는 테스트 코퍼스에서의 바이트당 비트(bits-per-byte)를 계산하는 방식으로, Pile-test에 적용되었습니다.
평가 결과를 살펴보면, DeepSeek 모델들은 2조 개의 이중 언어 코퍼스로 학습되었음에도 불구하고, 영어에만 초점을 맞춘 LLaMA2 모델들과 비교했을 때 영어 언어 이해 벤치마크에서 대등한 성능을 보여주었습니다. 특히 주목할 만한 점은 DeepSeek 67B가 MATH, GSM8K, HumanEval, MBPP, BBH, 그리고 중국어 벤치마크에서 LLaMA2 70B보다 상당히 우수한 성능을 달성했다는 것입니다. 벤치마크 성능 곡선 분석 결과, GSM8K와 BBH와 같은 일부 과제에서는 모델 규모가 커짐에 따라 성능이 크게 향상되는 것이 관찰되었습니다. 7B와 67B 모델이 동일한 데이터셋으로 학습되었다는 점을 고려할 때, 이러한 성능 향상은 대규모 모델의 강력한 퓨샷 학습 능력에 기인한 것으로 분석됩니다. 그러나 수학적 데이터의 비중이 증가함에 따라 작은 모델과 큰 모델 간의 성능 격차가 감소하는 경향도 발견되었습니다.
특히 흥미로운 점은 DeepSeek 67B가 LLaMA2 70B에 비해 보이는 우위가 DeepSeek 7B와 LLaMA2 7B 사이의 차이보다 더 크다는 것입니다. 이는 작은 모델일수록 언어 충돌(language conflict)의 영향을 더 크게 받는다는 것을 시사합니다. 또한 중국어 데이터로 특별히 학습되지 않은 LLaMA2가 CMath와 같은 특정 중국어 과제에서 인상적인 성능을 보여주었다는 점도 주목할 만합니다. 이는 수학적 추론과 같은 기본적인 능력이 언어 간에 효과적으로 전이될 수 있다는 것을 보여줍니다. 그러나 CHID와 같이 중국어 관용구의 사용을 평가하는 과제에서는 LLaMA2의 성능이 크게 떨어졌는데, 이는 이러한 과제들이 사전학습 과정에서 상당한 양의 중국어 토큰을 필요로 한다는 것을 보여줍니다.
채팅 모델의 성능 평가 결과, 대부분의 과제에서 미세조정 후 전반적인 성능 향상이 관찰되었습니다. 지식 관련 과제(TriviaQA, MMLU, C-Eval 등)에서는 기본 모델과 채팅 모델 사이에 성능 변동이 관찰되었으나, 이는 지식의 획득이나 손실을 의미하지는 않습니다. SFT의 진정한 가치는 기본 모델의 퓨샷 설정과 비교할 만한 성능을 채팅 모델의 제로샷 설정에서 달성할 수 있다는 점에 있습니다.
추론 과제에서는 SFT 인스턴스의 상당 부분이 Chain-of-Thought 형식으로 구성되어 있어, 채팅 모델이 BBH와 NaturalQuestions와 같은 과제에서 약간의 성능 향상을 보였습니다. 그러나 연구진은 SFT 단계가 추론 능력 자체를 학습하는 것이 아니라 추론 경로의 올바른 형식을 학습하는 것이라고 분석합니다.
특히 HellaSwag와 같은 빈칸 채우기나 문장 완성 과제에서는 모델 크기나 사전학습된 체크포인트와 관계없이 미세조정 후 성능이 일관되게 하락하는 현상이 관찰되었습니다. 이는 순수한 언어 모델이 이러한 과제에 더 적합하다는 것을 시사합니다.
수학과 코드 분야에서는 미세조정 후 상당한 성능 향상이 관찰되었습니다. HumanEval과 GSM8K에서 20포인트 이상의 성능 향상이 있었는데, 이는 기본 모델이 이러한 과제에 대해 초기에 과소적합(underfitted) 상태였으며, SFT 단계에서 광범위한 SFT 데이터를 통해 추가적인 코딩과 수학 지식을 학습했기 때문으로 분석됩니다. AlignBench 리더보드 평가 결과에서는 DeepSeek 67B 채팅 모델이 ChatGPT와 다른 기준 모델들을 상당한 차이로 능가하는 것으로 나타났습니다. 이는 기본적인 중국어 언어 과제와 고급 중국어 추론 과제 모두에서 우수한 성능을 보여준다는 것을 의미합니다. 특히 DPO 과정을 거친 후에는 거의 모든 분야에서 성능이 향상되었음이 확인되었습니다.
개방형 평가에서는 채팅 모델의 실제 사용자 경험에 직접적인 영향을 미치는 개방형 질문에 대한 생성 능력을 별도로 테스트했습니다. 중국어 개방형 평가를 위해 AlignBench를 활용했는데, 이는 총 8개의 주요 카테고리와 36개의 하위 카테고리를 포함하는 683개의 질문으로 구성되어 있습니다. 각 질문에는 전문가의 참조 답변과 GPT-4가 응답의 품질을 판단하기 위한 평가 템플릿이 함께 제공됩니다.
영어 개방형 평가에서는 MT-Bench 벤치마크를 사용했으며, 이는 8가지 다른 카테고리의 다중 턴 질문들을 포함합니다. DeepSeek LLM 67B 채팅 모델은 LLaMA-2-Chat 70B, Xwin 70b v0.1, TÜLU 2+DPO 70B와 같은 다른 오픈소스 모델들을 능가하며, GPT-3.5-turbo와 비슷한 8.35점을 달성했습니다. DPO 단계를 거친 후에는 평균 점수가 8.76으로 더욱 향상되어 GPT-4에 이어 두 번째로 높은 성능을 보여주었습니다.
벤치마크 과적합과 데이터 오염 문제를 해결하기 위해 최근 공개된 테스트셋을 활용한 평가도 진행되었습니다. LeetCode 주간 콘테스트(2023년 7월부터 11월까지)의 126개 문제를 크롤링하여 코딩 능력을 평가했으며, 헝가리 국가 고등학교 시험의 33개 문제를 통해 수학적 능력을 평가했습니다. 또한 2023년 11월에 Google이 공개한 지시사항 준수 평가 데이터셋을 활용하여 모델의 지시 따르기 능력을 평가했습니다.
이러한 평가 결과들은 큰 모델과 작은 모델 사이에 상당한 성능 차이가 있음을 보여줍니다. 특히 일부 작은 모델들이 기존 벤치마크에서는 좋은 결과를 보여주더라도, 새로운 벤치마크에서는 DeepSeek 67B에 비해 현저히 낮은 성능을 보였습니다. 예를 들어, ChatGLM3는 코드 테스트셋 MBPP에서 52.4점으로 DeepSeek 67B와 비슷한 성능을 보였지만, 새로운 벤치마크에서는 큰 차이로 뒤처졌습니다. 이러한 경향은 수학 데이터셋에서도 유사하게 나타났습니다.
모델 안전성 평가
DeepSeek LLM의 안전성 평가를 위해 연구진은 20명의 전문가로 구성된 팀을 구성하고 인간의 가치와 부합하는 안전성 평가 분류 체계를 구축했습니다. 이 분류 체계는 차별과 편견, 타인의 법적 권리 침해, 영업 비밀과 지적 재산권, 불법 행위, 그리고 기타 안전성 문제 등 다양한 카테고리를 포함합니다.
전문가 팀은 각 안전성 하위 카테고리에 대해 수십 개의 고품질 테스트 케이스를 수작업으로 구성했습니다. 특히 안전성 평가에서는 내용의 다양성뿐만 아니라 형식의 다양성도 중요하게 고려되었습니다. 예를 들어, “할머니” 취약점으로 알려진 문제는 모델이 질문의 표면적 형식에 속아 안전하지 않은 응답을 제공할 수 있다는 것을 보여줍니다. 이에 전문가 팀은 유도, 역할극, 다중 턴 대화, 사전 설정된 입장 등 다양한 방식으로 안전성 문제를 구성했습니다.
최종적으로 구축된 안전성 테스트 세트는 2,400개의 질문으로 구성되었으며, 각 내용 유형과 형식 유형에 대한 기본적인 안전성 검토 지침도 함께 마련되었습니다. 모델의 출력 결과는 수동으로 검사되었으며, 검토 팀은 충분한 훈련을 받았고 주석 결과에 대한 교차 검증이 수행되었습니다. 각 질문에 대해 ‘안전’, ‘불안전’, ‘모델 거부’의 세 가지 카테고리로 주석이 달렸습니다.
DeepSeek 67B 채팅 모델의 안전성 테스트 결과, 다양한 안전성 테스트 카테고리에서 우수한 성능을 보여주었습니다. 특히 차별과 편견 관련 문제에서는 500개의 테스트 케이스 중 486개를, 타인의 법적 권리 침해 관련 문제에서는 500개 중 473개를 안전하게 처리했습니다.
추가적으로 Wang과 연구진이 개발한 “Do-Not-Answer” 데이터셋을 활용하여 DeepSeek 67B 채팅 모델의 안전성 메커니즘을 평가했습니다. 939개의 위험 분류된 프롬프트로 구성된 이 데이터셋에서 DeepSeek 모델은 97.8점을 달성했는데, 이는 ChatGPT와 GPT-4보다 높은 점수입니다. 이러한 결과는 DeepSeek 모델이 민감한 쿼리를 안전하게 처리할 수 있는 능력을 갖추고 있음을 보여줍니다.
References
Subscribe via RSS