LLaMA: Open and Efficient Foundation Language Models
by Meta AI
TL;DR
이 연구를 시작하게 된 배경과 동기는 무엇입니까?
대규모 언어 모델(LLMs)은 텍스트 기반 과제에서 놀라운 성능을 보여주고 있지만, 대부분의 최신 모델들이 비공개 데이터셋에 의존하고 있어 연구 커뮤니티의 접근과 검증이 제한되는 문제가 있었습니다. 또한 기존 모델들은 대부분 매우 큰 규모의 파라미터를 필요로 하여 실제 응용에 제약이 있었습니다. Meta AI 연구진은 이러한 한계를 극복하고자, 공개 데이터만을 사용하면서도 최고 수준의 성능을 달성할 수 있는 효율적인 언어 모델 개발을 목표로 연구를 시작했습니다.
이 연구에서 제시하는 새로운 해결 방법은 무엇입니까?
LLaMA는 세 가지 주요 혁신을 제시합니다. 첫째, 완전히 공개된 데이터셋만을 사용하여 학습함으로써 모델의 투명성과 재현성을 보장했습니다. 둘째, Chinchilla 스케일링 법칙을 기반으로 하되, 추론 효율성에 초점을 맞춰 모델 크기와 학습 데이터의 균형을 최적화했습니다. 셋째, 사전 정규화, RMSNorm, SwiGLU 활성화 함수, 회전 위치 임베딩 등 최신 아키텍처 개선사항들을 효과적으로 통합했습니다.
제안된 방법은 어떻게 구현되었습니까?
LLaMA는 7B부터 65B 파라미터에 이르는 다양한 규모의 모델로 구현되었습니다. 학습 데이터는 CommonCrawl(67%), C4(15%), GitHub(4.5%), Wikipedia(4.5%), Books(4.5%), ArXiv(2.5%), Stack Exchange(2%) 등 다양한 공개 소스를 포함합니다. 모델 아키텍처는 트랜스포머를 기반으로 하되, 여러 최적화 기법을 적용하여 학습과 추론 효율성을 개선했습니다. 특히 xformers 라이브러리를 활용한 효율적인 어텐션 구현과 활성화값 재계산 최적화를 통해 학습 속도를 크게 향상시켰습니다.
이 연구의 결과가 가지는 의미는 무엇입니까?
이 연구는 세 가지 중요한 의미를 가집니다. 첫째, 13B 파라미터 모델이 175B의 GPT-3를 능가함으로써, 효율적인 모델 설계의 중요성을 입증했습니다. 둘째, 공개 데이터만으로도 최고 수준의 성능을 달성할 수 있다는 것을 보여줌으로써, 언어 모델 연구의 민주화 가능성을 제시했습니다. 셋째, 모델의 규모에 따른 편향성과 유해성 증가를 체계적으로 분석함으로써, 향후 안전하고 책임있는 AI 개발을 위한 중요한 통찰을 제공했습니다. 이러한 결과들은 대규모 언어 모델 분야의 발전 방향을 재정립하는 데 큰 영향을 미칠 것으로 예상됩니다.
LLaMA: 개방형 고효율 기초 언어 모델
Meta AI의 연구진은 7B부터 65B 파라미터에 이르는 기초 언어 모델 시리즈인 LLaMA를 소개했습니다. 이 연구의 가장 주목할 만한 특징은 공개적으로 접근 가능한 데이터셋만을 사용하여 최첨단 성능의 언어 모델을 학습할 수 있다는 것을 입증했다는 점입니다. 특히 13B 파라미터 규모의 LLaMA 모델이 175B 파라미터의 GPT-3를 대부분의 벤치마크에서 능가했으며, 65B 파라미터 모델은 Chinchilla-70B와 PaLM-540B와 같은 최고 수준의 모델들과 견줄 만한 성능을 보여주었습니다.
대규모 언어 모델(Large Language Models, LLMs)은 방대한 텍스트 데이터로 학습되어 텍스트 기반 지시사항이나 소수의 예시만으로도 새로운 과제를 수행할 수 있는 능력을 보여왔습니다. Kaplan과 연구진이 제시한 연구에 따르면, 이러한 퓨 샷 학습 능력은 모델이 충분한 규모에 도달했을 때 처음 나타나기 시작했습니다. 이는 더 큰 규모의 모델이 더 나은 성능을 보일 것이라는 가정 하에 모델의 크기를 계속해서 확장하는 연구 방향으로 이어졌습니다.
하지만 Hoffmann과 연구진의 최근 연구는 주어진 컴퓨팅 예산 내에서 최고의 성능은 가장 큰 모델이 아닌, 더 많은 데이터로 학습된 상대적으로 작은 모델에서 달성된다는 것을 보여주었습니다. Hoffmann과 연구진이 제시한 스케일링 법칙은 특정 학습 컴퓨팅 예산에 대해 데이터셋과 모델 크기를 어떻게 최적으로 조정할 것인지를 결정하는 데 중점을 두었습니다. 그러나 이러한 접근은 실제 서비스 환경에서 중요한 추론 비용을 고려하지 않았습니다.
LLaMA 연구진은 추론 시의 효율성에 초점을 맞추어, 목표 성능 수준에서 가장 빠른 추론 속도를 달성할 수 있는 모델을 개발하는 데 주력했습니다. 예를 들어, Hoffmann과 연구진이 10B 파라미터 모델을 200B 토큰으로 학습하는 것을 권장했지만, LLaMA 연구진은 7B 파라미터 모델이 1조 토큰 이상의 학습 데이터에서도 지속적인 성능 향상을 보인다는 것을 발견했습니다. 이러한 연구 배경을 바탕으로, LLaMA 연구진은 다양한 추론 예산 환경에서 최고의 성능을 달성할 수 있는 언어 모델 시리즈를 개발하는 데 집중했습니다. 특히 주목할 만한 점은 기존의 Chinchilla, PaLM, GPT-3와는 달리 LLaMA가 전적으로 공개적으로 이용 가능한 데이터만을 사용했다는 것입니다. 이는 모델의 오픈소스화를 가능하게 만드는 중요한 특징입니다. 반면 다른 모델들은 “Books – 2TB”나 “Social media conversations”와 같이 공개되지 않았거나 문서화되지 않은 데이터에 의존하고 있습니다.
물론 OPT, GPT-NeoX, BLOOM, GLM과 같은 개방형 언어 모델들이 이전에도 존재했지만, 이들은 PaLM-62B나 Chinchilla와 같은 최고 수준의 모델들과 경쟁할 만한 성능을 보여주지 못했습니다. LLaMA는 이러한 한계를 극복하고, 공개 데이터만으로도 최고 수준의 성능을 달성할 수 있다는 것을 입증했습니다.
LLaMA의 개발 과정에서 연구진은 Vaswani와 연구진이 제안한 트랜스포머 아키텍처에 여러 가지 수정을 가했습니다. 이러한 수정사항들은 모델의 학습 효율성과 추론 속도를 개선하는 데 초점을 맞추었습니다. 연구진은 이러한 아키텍처 수정사항들과 함께 학습 방법론에 대해서도 상세히 설명할 예정이며, 표준 벤치마크 테스트를 통해 다른 대규모 언어 모델들과의 성능을 비교 분석했습니다.
또한 연구진은 책임 있는 AI 커뮤니티에서 최근 개발한 벤치마크들을 활용하여 LLaMA 모델에 내재된 편향성과 유해성에 대해서도 면밀히 분석했습니다. 이는 대규모 언어 모델의 윤리적 측면과 사회적 영향을 고려하는 중요한 연구 방향을 제시합니다.
LLaMA 모델의 학습 방법론은 Brown과 연구진이 GPT-3에서 제시한 방법과 Chowdhery와 연구진이 PaLM에서 사용한 접근법을 기반으로 하고 있습니다. 특히 Hoffmann과 연구진이 제안한 Chinchilla 스케일링 법칙에서 큰 영감을 받아 설계되었습니다.
이 학습 방법의 핵심은 대규모 트랜스포머 모델을 방대한 양의 텍스트 데이터로 학습시키는 것입니다. 여기서 트랜스포머는 Vaswani와 연구진이 “Attention Is All You Need” 논문에서 제안한 아키텍처를 기반으로 합니다. 학습 과정에서는 표준적인 옵티마이저를 사용하여 모델의 파라미터를 최적화합니다.
이러한 접근 방식은 Chinchilla 스케일링 법칙의 핵심 발견을 반영합니다. Hoffmann과 연구진은 주어진 컴퓨팅 예산 내에서 최적의 성능을 달성하기 위해서는 모델 크기와 학습 데이터의 규모를 균형있게 조절해야 한다는 것을 보여주었습니다. 구체적으로, 모델 크기를 두 배로 늘릴 때마다 학습 데이터의 양도 두 배로 늘려야 한다는 것입니다.
이는 기존의 스케일링 법칙과는 다른 관점을 제시합니다. 예를 들어, Kaplan과 연구진이 제안한 이전의 스케일링 법칙에서는 모델 크기가 학습 데이터보다 더 빠르게 증가해야 한다고 주장했습니다. 그러나 Chinchilla 연구는 이러한 가정이 최적이 아님을 실험적으로 입증했습니다.
LLaMA의 학습 방법론은 이러한 발견을 실제 구현에 적용했습니다. 표준 옵티마이저를 사용하면서도, Chinchilla 스케일링 법칙이 제시하는 모델 크기와 데이터 규모의 최적 비율을 고려하여 학습을 진행했습니다. 이는 컴퓨팅 자원을 효율적으로 활용하면서도 모델의 성능을 최대한 끌어올리는 데 기여했습니다.
사전 학습 데이터
LLaMA 모델의 학습에는 다양한 도메인의 데이터가 사용되었습니다. 연구진은 공개적으로 접근 가능하고 오픈소스 라이선스와 호환되는 데이터만을 엄선하여 사용했는데, 이는 모델의 투명성과 재현성을 높이기 위한 중요한 선택이었습니다.
가장 큰 비중을 차지하는 것은 영어 CommonCrawl 데이터로, 전체 학습 데이터의 67%를 차지합니다. 이 데이터는 2017년부터 2020년까지의 5개 CommonCrawl 덤프에서 추출되었으며, Wenzek와 연구진이 개발한 CCNet 파이프라인을 통해 전처리되었습니다. CCNet 파이프라인은 라인 레벨에서 중복을 제거하고, fastText 선형 분류기를 사용하여 영어가 아닌 페이지를 필터링하며, n-gram 언어 모델을 통해 저품질 콘텐츠를 걸러냅니다. 특히 연구진은 위키피디아에서 참조로 사용된 페이지와 무작위로 샘플링된 페이지를 구분하는 선형 모델을 학습시켜, 참조로 분류되지 않은 페이지는 제외했습니다.
두 번째로 큰 비중을 차지하는 것은 C4 데이터셋으로, 전체의 15%를 차지합니다. Raffel과 연구진이 공개한 이 데이터셋은 CCNet과 마찬가지로 중복 제거와 언어 식별 단계를 포함하지만, 품질 필터링에서 차이를 보입니다. C4는 문장부호의 존재나 웹페이지의 단어 및 문장 수와 같은 휴리스틱에 주로 의존합니다.
GitHub 데이터는 전체의 4.5%를 차지하며, Google BigQuery에서 제공하는 공개 GitHub 데이터셋을 사용했습니다. Apache, BSD, MIT 라이선스로 배포된 프로젝트만을 선별했으며, 라인 길이나 영숫자 문자의 비율 등을 기반으로 한 휴리스틱을 통해 저품질 파일을 필터링했습니다. 또한 정규표현식을 사용하여 헤더와 같은 상용구를 제거하고, 파일 수준에서 정확히 일치하는 중복을 제거했습니다.
위키피디아 데이터도 4.5%를 차지하며, 2022년 6월부터 8월까지의 덤프를 사용했습니다. 라틴 문자나 키릴 문자를 사용하는 20개 언어(bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk)를 포함하며, 하이퍼링크, 주석, 기타 서식 상용구를 제거하는 전처리 과정을 거쳤습니다. 도서 관련 데이터는 전체 학습 데이터의 4.5%를 차지하며, 두 가지 주요 코퍼스를 포함합니다. 첫 번째는 공공 도메인의 책들을 포함하는 구텐베르크 프로젝트이고, 두 번째는 대규모 언어 모델 학습을 위해 공개된 ThePile의 Books3 섹션입니다. Gao와 연구진이 구축한 ThePile 데이터셋은 다양한 도메인의 고품질 텍스트를 포함하고 있습니다. 연구진은 책 수준에서 중복을 제거했는데, 특히 90% 이상의 내용이 중복되는 책들은 제외했습니다.
과학 문헌 데이터로는 arXiv의 LaTeX 파일들이 사용되었으며, 이는 전체 데이터의 2.5%를 차지합니다. Lewkowycz와 연구진의 접근 방식을 따라, 첫 번째 섹션 이전의 모든 내용과 참고문헌을 제거했습니다. 또한 .tex 파일에서 주석을 제거하고, 논문 간의 일관성을 높이기 위해 사용자가 작성한 정의와 매크로를 인라인으로 확장했습니다.
Stack Exchange 데이터는 전체의 2%를 차지하며, 컴퓨터 과학부터 화학까지 다양한 분야를 다루는 고품질 질문과 답변 웹사이트의 덤프를 포함합니다. 연구진은 28개의 가장 큰 웹사이트의 데이터를 선택했으며, 텍스트에서 HTML 태그를 제거하고 답변을 점수(높은 것부터 낮은 순)에 따라 정렬했습니다.
토크나이저로는 SentencePiece 구현체를 사용하여 바이트 쌍 인코딩(BPE) 알고리즘을 적용했습니다. Kudo와 Richardson이 개발한 SentencePiece는 모든 숫자를 개별 자릿수로 분할하고, 알 수 없는 UTF-8 문자는 바이트로 분해하는 특징을 가지고 있습니다. 전체 학습 데이터는 토크나이즈 후 약 1.4조 토큰을 포함하며, 위키피디아와 도서 도메인을 제외한 대부분의 데이터는 학습 과정에서 한 번만 사용되었습니다. 위키피디아와 도서 데이터의 경우 약 2.4 에포크와 2.2 에포크를 각각 수행했습니다.
아키텍처
LLaMA 모델은 Vaswani와 연구진이 제안한 트랜스포머 아키텍처를 기반으로 하며, PaLM과 같은 최신 언어 모델들에서 사용된 다양한 개선사항들을 적용했습니다. 원래의 트랜스포머 아키텍처와 비교하여 주요한 변경사항들을 살펴보겠습니다.
첫 번째로, 학습 안정성을 향상시키기 위해 사전 정규화(Pre-normalization) 방식을 도입했습니다. GPT-3에서 영감을 받은 이 방식은 트랜스포머의 각 서브레이어의 출력이 아닌 입력을 정규화합니다. 정규화 함수로는 Zhang과 연구진이 제안한 RMSNorm을 사용했습니다. RMSNorm은 기존의 LayerNorm과 달리 평균을 계산하지 않고 제곱평균만을 사용하여 계산 효율성을 높이면서도 정규화의 효과를 유지합니다.
두 번째로, PaLM에서 영감을 받아 ReLU 비선형성을 SwiGLU 활성화 함수로 대체했습니다. Shazeer가 제안한 SwiGLU는 모델의 성능을 향상시키는 것으로 알려져 있습니다. 다만 PaLM에서 사용된 \(4d\) 대신 \(\frac{2}{3}4d\)의 차원을 사용했는데, 이는 계산 효율성과 모델 성능 사이의 균형을 위한 선택입니다.
세 번째로, GPTNeo의 영향을 받아 절대 위치 임베딩을 제거하고 대신 Su와 연구진이 제안한 회전 위치 임베딩(RoPE)을 네트워크의 각 레이어에 추가했습니다. RoPE는 상대적 위치 정보를 더 효과적으로 인코딩할 수 있으며, 특히 긴 시퀀스에서 더 나은 성능을 보입니다.
아래 그래프는 7B, 13B, 33B, 65B 파라미터를 가진 네 가지 LLaMA 모델의 학습 손실을 보여줍니다. 33B와 65B 모델은 1.4T 토큰으로 학습되었고, 더 작은 모델들은 1.0T 토큰으로 학습되었습니다. 모든 모델은 4M 토큰의 배치 크기로 학습되었습니다.
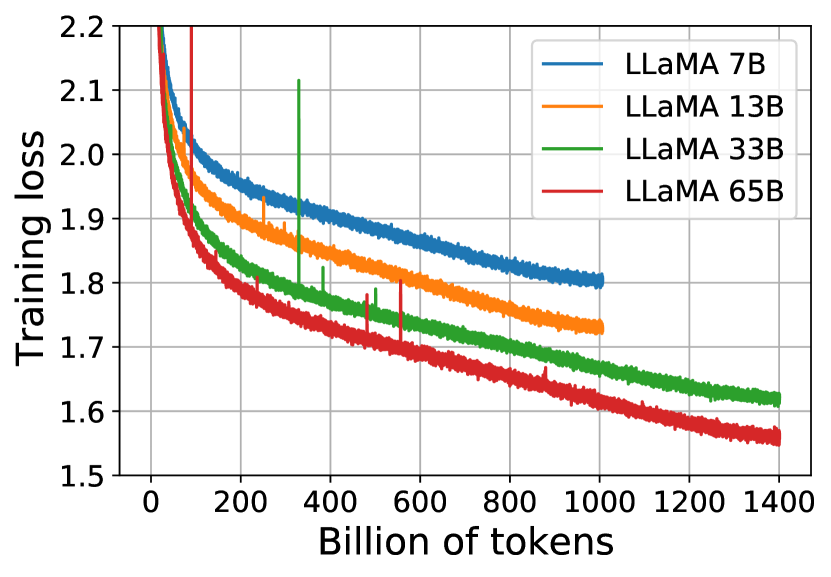
이 그래프에서 주목할 만한 점은 모델 크기가 증가할수록 학습 손실이 감소하는 경향을 보인다는 것입니다. 특히 33B와 65B 모델은 더 많은 학습 데이터(1.4T 토큰)를 사용했음에도 불구하고 안정적인 학습 곡선을 보여주며, 이는 모델의 규모가 커질수록 더 많은 데이터를 효과적으로 학습할 수 있다는 것을 시사합니다.
옵티마이저
LLaMA 모델의 학습에는 AdamW 옵티마이저가 사용되었습니다. Loshchilov와 연구진이 제안한 AdamW는 기존 Adam 옵티마이저의 개선된 버전으로, 가중치 감쇠(weight decay)를 적응적 학습률 업데이트와 분리하여 더 효과적인 정규화를 가능하게 합니다.
AdamW의 주요 하이퍼파라미터는 다음과 같이 설정되었습니다. \(\beta_1 = 0.9, \beta_2 = 0.95\)
여기서 \(\beta_1\)은 그래디언트의 지수 이동 평균을 계산하는 데 사용되는 계수이고, \(\beta_2\)는 그래디언트의 제곱값에 대한 지수 이동 평균을 계산하는 데 사용되는 계수입니다. 이러한 값들은 모델이 학습 과정에서 그래디언트의 변화를 얼마나 빠르게 반영할지를 결정합니다.
학습률은 코사인 스케줄링을 통해 조정되었는데, 이는 학습 과정에서 학습률이 코사인 함수의 형태로 점진적으로 감소하여 최종적으로는 최대 학습률의 10%가 되도록 설정되었습니다. 이러한 학습률 스케줄링은 학습 초기에는 빠른 학습을 가능하게 하고, 후반부에는 안정적인 수렴을 돕습니다.
가중치 감쇠는 0.1로 설정되었으며, 이는 모델의 복잡도를 제어하고 과적합을 방지하는 역할을 합니다. 그래디언트 클리핑은 1.0으로 설정되어 그래디언트 폭주 문제를 방지하고 학습의 안정성을 높입니다.
웜업 단계에서는 2,000 스텝이 사용되었습니다. 웜업은 학습 초기에 학습률을 점진적으로 증가시키는 과정으로, 모델이 안정적으로 학습을 시작할 수 있도록 돕습니다. 학습률과 배치 크기는 모델의 크기에 따라 다르게 설정되었으며, 이에 대한 자세한 내용은 논문의 표 2에서 확인할 수 있습니다.
효율적인 구현
LLaMA 연구진은 모델의 학습 속도를 향상시키기 위해 여러 가지 최적화 기법을 적용했습니다. 가장 먼저, xformers 라이브러리를 활용하여 인과적 멀티헤드 어텐션(causal multi-head attention)의 메모리 사용량과 실행 시간을 크게 줄였습니다. 이 구현은 Rabe와 연구진이 제안한 방식에 기반을 두고 있으며, Dao와 연구진이 제시한 역전파 방식을 채택했습니다. 주목할 만한 점은 어텐션 가중치를 저장하지 않고, 언어 모델링 작업의 인과적 특성으로 인해 마스킹되는 키/쿼리 점수를 계산하지 않는다는 것입니다.
학습 효율성을 더욱 높이기 위해 역전파 과정에서 재계산되는 활성화값의 양을 줄였습니다. 구체적으로, 선형 레이어의 출력과 같이 계산 비용이 높은 활성화값들을 저장하는 방식을 채택했습니다. 이는 PyTorch의 자동 미분(autograd) 기능에 의존하지 않고 트랜스포머 레이어의 역전파 함수를 직접 구현함으로써 달성되었습니다.
이러한 최적화의 이점을 최대한 활용하기 위해 Korthikanti와 연구진이 제안한 모델 병렬화와 시퀀스 병렬화 기법을 적용하여 모델의 메모리 사용량을 줄였습니다. 또한, GPU 간의 네트워크 통신(all_reduce 연산으로 인한)과 활성화값 계산을 최대한 중첩시켜 처리했습니다.
이러한 최적화 기법들의 효과는 상당했습니다. 65B 파라미터 모델을 학습할 때, 80GB RAM을 탑재한 2048개의 A100 GPU에서 GPU당 초당 약 380개의 토큰을 처리할 수 있었습니다. 이는 1.4T 토큰으로 구성된 데이터셋을 약 21일 만에 학습할 수 있다는 것을 의미합니다.
아래 표는 LLaMA 모델의 상식 추론 작업에 대한 제로샷 성능을 다른 대형 언어 모델들과 비교한 결과를 보여줍니다.
| 모델 | BoolQ | PIQA | SIQA | HellaSwag | WinoGrande | ARC-e | ARC-c | OBQA |
|---|---|---|---|---|---|---|---|---|
| GPT-3 175B | 60.5 | 81.0 | - | 78.9 | 70.2 | 68.8 | 51.4 | 57.6 |
| Gopher 280B | 79.3 | 81.8 | 50.6 | 79.2 | 70.1 | - | - | - |
| Chinchilla 70B | 83.7 | 81.8 | 51.3 | 80.8 | 74.9 | - | - | - |
| PaLM 62B | 84.8 | 80.5 | - | 79.7 | 77.0 | 75.2 | 52.5 | 50.4 |
| PaLM-cont 62B | 83.9 | 81.4 | - | 80.6 | 77.0 | - | - | - |
| PaLM 540B | 88.0 | 82.3 | - | 83.4 | 81.1 | 76.6 | 53.0 | 53.4 |
| LLaMA 7B | 76.5 | 79.8 | 48.9 | 76.1 | 70.1 | 72.8 | 47.6 | 57.2 |
| LLaMA 13B | 78.1 | 80.1 | 50.4 | 79.2 | 73.0 | 74.8 | 52.7 | 56.4 |
| LLaMA 33B | 83.1 | 82.3 | 50.4 | 82.8 | 76.0 | 80.0 | 57.8 | 58.6 |
| LLaMA 65B | 85.3 | 82.8 | 52.3 | 84.2 | 77.0 | 78.9 | 56.0 | 60.2 |
이 결과는 LLaMA 모델이 효율적인 구현을 통해 더 적은 계산 자원으로도 경쟁력 있는 성능을 달성할 수 있다는 것을 보여줍니다.
주요 실험 결과
LLaMA 모델의 성능을 평가하기 위해 연구진은 제로샷(zero-shot)과 퓨샷(few-shot) 학습 방식을 적용했습니다. 제로샷 방식에서는 모델에게 과제에 대한 텍스트 설명과 테스트 예시만을 제공하고, 모델은 자유로운 생성이나 제안된 답변들 중에서 순위를 매기는 방식으로 응답합니다. 퓨샷 방식에서는 1개에서 64개 사이의 과제 예시를 함께 제공하여 모델이 이를 참고할 수 있도록 합니다.
연구진은 LLaMA를 GPT-3, Gopher, Chinchilla, PaLM과 같은 비공개 대규모 언어 모델들과 비교했습니다. 또한 OPT, GPT-J, GPT-Neo와 같은 오픈소스 모델들과도 성능을 비교했습니다. 추가로 OPT-IML이나 Flan-PaLM과 같은 지시어 튜닝(instruction-tuned) 모델들과도 간단한 비교를 수행했습니다.
평가는 자유 형식 생성 과제와 객관식 과제로 나누어 진행되었습니다. 객관식 과제에서는 주어진 맥락에 대해 가장 적절한 답변을 여러 선택지 중에서 고르는 방식으로 진행되었습니다. 선택 방식에는 두 가지 접근법이 사용되었습니다.
첫 번째는 Gao와 연구진이 제안한 방식으로, 답변의 문자 수로 정규화된 확률값을 사용합니다. 두 번째는 Brown과 연구진이 제안한 방식으로, OpenBookQA와 BoolQ 데이터셋에 적용되었는데, 다음과 같은 수식을 사용합니다.
\[P(\mathtt{completion}|\mathtt{context})/P(\mathtt{completion}|``Answer:")\]이 수식에서는 주어진 맥락에서의 답변 확률을 단순히 “Answer:”라는 프롬프트 다음에 나올 확률로 나누어 정규화합니다.
자연어 질의응답 과제인 Natural Questions에서의 성능을 살펴보면, LLaMA-65B는 제로샷과 퓨샷 설정 모두에서 최고 수준의 성능을 보여주었습니다. 특히 주목할 만한 점은 LLaMA-13B가 GPT-3와 Chinchilla에 비해 5-10배 적은 파라미터를 가졌음에도 경쟁력 있는 성능을 보여주었다는 것입니다. 이는 단일 V100 GPU에서도 추론이 가능한 수준의 효율성을 의미합니다.
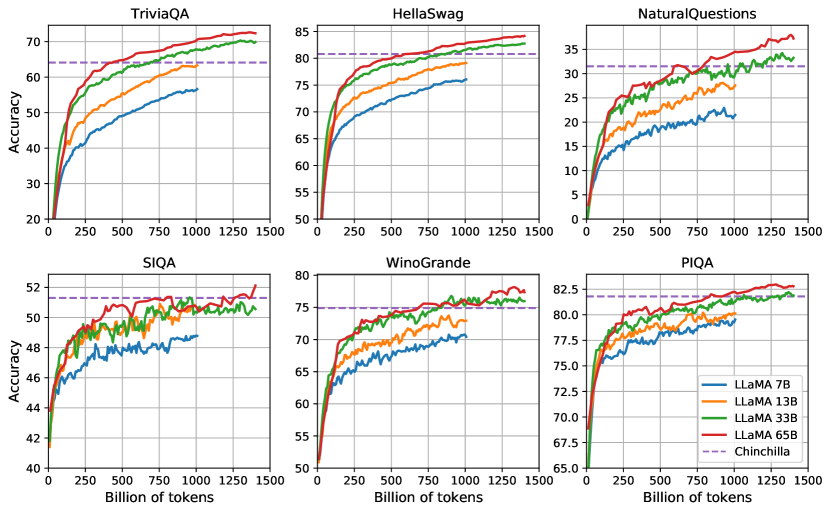
위 그래프는 LLaMA의 다양한 버전(7B, 13B, 33B, 65B)과 Chinchilla 모델의 학습 과정에서 질의응답과 상식 추론 과제에서의 성능 변화를 보여줍니다. 대부분의 벤치마크에서 성능이 꾸준히 향상되며, 이는 모델의 학습 퍼플렉시티와 상관관계를 보입니다. 다만 SIQA와 WinoGrande에서는 예외적인 패턴이 관찰되었습니다. 특히 SIQA에서는 성능의 변동성이 크게 나타났는데, 이는 해당 벤치마크의 신뢰성에 의문을 제기하게 만드는 결과입니다. WinoGrande의 경우에는 학습 퍼플렉시티와의 상관관계가 상대적으로 약했으며, LLaMA-33B와 LLaMA-65B가 학습 과정에서 유사한 수준의 성능을 보여주었습니다. LLaMA 모델의 성능 평가는 여러 가지 핵심적인 자연어 처리 과제를 통해 이루어졌습니다. 먼저 상식 추론 능력을 평가하기 위해 8개의 표준 벤치마크가 사용되었습니다. BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy, ARC challenge, 그리고 OpenBookQA입니다. 이러한 데이터셋들은 Cloze 스타일 과제와 Winograd 스타일 과제, 그리고 객관식 질의응답을 포함하고 있습니다.
상식 추론 평가에서 LLaMA-65B는 BoolQ를 제외한 모든 벤치마크에서 Chinchilla-70B의 성능을 뛰어넘었습니다. 또한 BoolQ와 WinoGrande를 제외한 모든 영역에서 PaLM-540B보다 우수한 성능을 보여주었습니다. 특히 주목할 만한 점은 LLaMA-13B가 GPT-3보다 10배 적은 파라미터를 가졌음에도 대부분의 벤치마크에서 더 나은 성능을 달성했다는 것입니다.
폐쇄형 질의응답 평가에서는 Natural Questions와 TriviaQA 두 가지 벤치마크가 사용되었습니다. 이러한 평가에서는 모델이 질문에 대한 답변을 찾을 수 있는 문서에 접근하지 못하는 ‘closed book’ 설정에서 정확한 답변을 생성하는 능력을 측정합니다. TriviaQA에서 LLaMA-65B는 제로샷 설정에서 68.2%, 1-샷 설정에서 71.6%, 5-샷 설정에서 72.6%, 그리고 64-샷 설정에서 73.0%의 정확도를 달성했습니다.
독해력 평가를 위해서는 RACE 벤치마크가 사용되었습니다. 이 데이터셋은 중국 중고등학생들을 위한 영어 독해 시험에서 수집된 것으로, Brown과 연구진이 제시한 평가 방식을 따랐습니다. RACE-middle에서 LLaMA-65B는 67.9%의 정확도를, RACE-high에서는 51.6%의 정확도를 기록했으며, 이는 PaLM-540B와 비슷한 수준의 성능입니다. 여기서도 LLaMA-13B는 GPT-3보다 몇 퍼센트 포인트 높은 성능을 보여주었습니다.
수학적 추론 능력 평가에서는 MATH와 GSM8k 두 가지 벤치마크가 사용되었습니다. MATH는 중고등학교 수준의 수학 문제 12,000개로 구성된 데이터셋이며, GSM8k는 중학교 수준의 수학 문제들을 포함하고 있습니다. 특히 주목할 만한 점은 LLaMA-65B가 수학 데이터로 특별히 파인튜닝되지 않았음에도 불구하고, 수학 데이터로 파인튜닝된 Minerva-62B의 성능을 뛰어넘었다는 것입니다. 코드 생성 능력을 평가하기 위해 연구진은 HumanEval과 MBPP라는 두 가지 벤치마크를 사용했습니다. 두 벤치마크 모두에서 모델은 프로그램에 대한 자연어 설명과 몇 가지 입출력 예시를 받습니다. HumanEval의 경우에는 함수 시그니처도 함께 제공되며, 프롬프트는 독스트링 내의 텍스트 설명과 테스트를 포함하는 자연스러운 코드 형태로 구성됩니다.
연구진은 LLaMA의 성능을 코드에 특화되지 않은 일반 목적 언어 모델인 PaLM 및 LaMDA와 비교했습니다. PaLM과 LLaMA는 학습 데이터에서 비슷한 양의 코드 토큰을 포함하고 있습니다. 평가 결과를 보면, LLaMA는 비슷한 크기의 다른 일반 모델들보다 우수한 성능을 보여주었습니다. 13B 이상의 파라미터를 가진 LLaMA 모델들은 137B 파라미터의 LaMDA를 HumanEval과 MBPP 모두에서 앞섰습니다. 특히 LLaMA-65B는 더 오래 학습된 모델을 포함해도 PaLM-62B보다 나은 성능을 보여주었습니다.
코드 생성 평가에서 pass@1 점수는 0.1의 온도(temperature) 설정으로 샘플링하여 얻었으며, pass@100과 pass@80 메트릭은 0.8의 온도로 측정되었습니다. Chen과 연구진이 제안한 방법을 사용하여 편향되지 않은 pass@k 추정치를 계산했습니다. 연구진은 코드 특화 토큰으로 파인튜닝하면 성능을 더욱 향상시킬 수 있다고 언급했습니다. 예를 들어, PaLM-Coder는 HumanEval에서 PaLM의 pass@1 점수를 26.2%에서 36%로 끌어올렸습니다.
대규모 다중 과제 언어 이해력(MMLU) 평가에서는 인문학, STEM, 사회과학 등 다양한 영역의 지식을 평가하는 객관식 문제들이 사용되었습니다. 5-샷 설정에서 평가한 결과, LLaMA-65B는 평균적으로 Chinchilla-70B와 PaLM-540B보다 몇 퍼센트 낮은 성능을 보였습니다. 연구진은 이러한 차이가 학습 데이터의 구성과 관련이 있을 것으로 분석했습니다. LLaMA는 ArXiv, Gutenberg, Books3에서 가져온 도서와 학술 논문 데이터가 총 177GB에 불과한 반면, 다른 모델들은 최대 2TB의 도서 데이터를 사용했습니다. 이러한 대량의 도서 데이터는 Gopher가 GPT-3보다 MMLU에서 더 나은 성능을 보이는 이유이기도 합니다.
마지막으로, 연구진은 지시어 파인튜닝의 효과를 검증하기 위해 간단한 실험을 진행했습니다. Chung과 연구진이 제시한 프로토콜을 따라 LLaMA-I라는 지시어 모델을 학습시켰습니다. 그 결과 MMLU에서 68.9%의 성능을 달성했는데, 이는 기존의 중간 규모 지시어 파인튜닝 모델들보다 우수한 결과입니다. 하지만 여전히 GPT code-davinci-002의 77.4%에는 미치지 못하는 수준입니다.
편향성, 유해성 및 허위정보
대규모 언어 모델의 발전과 함께 이러한 모델들이 가진 잠재적 위험성에 대한 평가도 중요해지고 있습니다. Sheng과 연구진, 그리고 Kurita와 연구진의 연구에 따르면, 대규모 언어 모델은 학습 데이터에 존재하는 편향성을 재생산하고 증폭시키는 경향이 있으며, Gehman과 연구진은 이러한 모델들이 유해하거나 공격적인 내용을 생성할 수 있다는 점을 지적했습니다.
LLaMA 모델의 잠재적 위험성을 평가하기 위해 연구진은 여러 벤치마크를 활용했습니다. 먼저 RealToxicityPrompts 벤치마크를 통해 모델의 유해 콘텐츠 생성 가능성을 평가했습니다. 이 벤치마크는 약 10만 개의 프롬프트로 구성되어 있으며, 각 프롬프트에 대한 모델의 응답을 PerspectiveAPI를 통해 자동으로 평가합니다. 평가 결과, 모델의 크기가 커질수록 유해성 점수가 증가하는 경향을 보였으며, 특히 “공손하고 존중하며 편향되지 않은 방식으로 문장을 완성하시오”라는 지시가 포함된 “respectful” 프롬프트에서 이러한 경향이 더욱 두드러졌습니다.
편향성 평가를 위해 CrowS-Pairs 벤치마크를 사용했습니다. 이 벤치마크는 성별, 종교, 인종/피부색, 성적 지향, 연령, 국적, 장애, 외모, 사회경제적 지위 등 9가지 범주의 편향성을 측정합니다. 각 예시는 고정관념을 반영하는 문장과 반고정관념적 문장으로 구성되어 있으며, 모델이 고정관념적 문장을 선호하는 정도를 퍼플렉시티를 통해 측정합니다. LLaMA-65B는 GPT-3와 OPT-175B와 비교했을 때 평균적으로 약간 더 나은 성능을 보였지만, 종교 범주에서는 OPT-175B보다 10% 더 높은 편향성을 보였고, 연령과 성별 범주에서도 상당한 편향성을 나타냈습니다.
성별 편향성을 더 자세히 조사하기 위해 WinoGender 벤치마크를 활용했습니다. 이는 대명사 해결(co-reference resolution) 과제로, 모델의 성능이 대명사의 성별에 따라 어떻게 달라지는지를 평가합니다. 평가 결과, LLaMA는 “their/them/someone”과 같은 성중립적 대명사에서 더 나은 성능을 보였으며, “her/her/she”와 “his/him/he”와 같은 성별 특정적 대명사에서는 상대적으로 낮은 성능을 보였습니다. 특히 “gotcha” 케이스, 즉 대명사의 성별이 직업의 주류 성별과 일치하지 않는 경우에서 더 많은 오류를 보였는데, 이는 모델이 성별과 직업에 관한 사회적 편향을 학습했음을 시사합니다.
마지막으로, TruthfulQA 벤치마크를 통해 모델의 진실성을 평가했습니다. 이 벤치마크는 모델이 실제 세계에 대한 사실을 얼마나 정확하게 식별할 수 있는지를 측정합니다. LLaMA는 GPT-3보다 높은 점수를 기록했지만, 여전히 정답률이 낮아 잘못된 정보나 허위 주장을 생성할 가능성이 있음을 보여주었습니다. 이러한 평가 결과들은 대규모 언어 모델의 안전성과 윤리적 측면에서 중요한 시사점을 제공합니다. 특히 RealToxicityPrompts 평가에서 나타난 결과를 더 자세히 살펴보면, LLaMA-7B의 경우 기본 프롬프트에서 0.106, 공손한 프롬프트에서 0.081의 유해성 점수를 보였으며, LLaMA-65B는 각각 0.128과 0.141의 점수를 기록했습니다. 이는 모델의 규모가 커질수록 유해 콘텐츠 생성 가능성이 증가한다는 것을 보여주며, 특히 공손함을 명시적으로 요청했을 때도 이러한 경향이 유지된다는 점에서 주목할 만합니다.
CrowS-Pairs 평가에서 발견된 편향성의 구체적인 수치를 보면, LLaMA-65B는 종교 관련 편향성이 79.0%로 가장 높았고, 성적 지향성에서 81.0%, 외모 관련 편향성에서 77.8%를 기록했습니다. 이는 CommonCrawl 데이터에서 비롯된 것으로 추정되며, 여러 차례의 필터링 과정을 거쳤음에도 이러한 편향성이 남아있다는 점은 데이터 정제의 한계를 보여줍니다.
WinoGender 평가에서는 모델 크기에 따른 성능 변화도 관찰되었습니다. LLaMA-7B에서 LLaMA-65B로 갈수록 전반적인 정확도는 향상되었지만, 성별 편향성은 오히려 강화되는 경향을 보였습니다. 예를 들어, “gotcha” 케이스에서 LLaMA-7B는 “her/her/she” 프롬프트에서 64.2%, “his/him/he” 프롬프트에서 55.0%의 정확도를 보인 반면, LLaMA-65B는 각각 75.0%와 63.3%를 기록했습니다. 이는 모델이 더 큰 규모에서 기존의 사회적 편향을 더 강하게 학습한다는 것을 시사합니다.
TruthfulQA 평가에서는 모델 크기에 따른 진실성 향상이 관찰되었습니다. LLaMA-7B의 경우 진실성 점수가 0.33, 진실성과 정보성을 모두 고려한 점수가 0.29였던 반면, LLaMA-65B는 각각 0.57과 0.53을 기록했습니다. 이는 GPT-3의 최고 성능인 0.28과 0.25를 크게 상회하는 수치이지만, 여전히 절반 정도의 경우에서만 진실된 정보를 제공한다는 것을 의미합니다.
이러한 평가 결과들은 대규모 언어 모델의 개발과 배포에 있어 안전성과 윤리적 고려사항이 더욱 중요해지고 있음을 보여줍니다. 특히 모델의 규모가 커질수록 성능이 향상되는 동시에 잠재적 위험성도 증가한다는 점은, 향후 모델 개발에서 이러한 trade-off를 어떻게 다룰 것인지에 대한 중요한 과제를 제시합니다.
탄소 발자국
LLaMA 모델의 학습 과정에서 발생한 에너지 소비와 탄소 배출량을 체계적으로 분석하기 위해, 연구진은 Wu와 연구진이 제안한 표준화된 방법론을 적용했습니다. 에너지 소비량을 계산하기 위한 기본 공식은 다음과 같습니다.
\[\textrm{Wh}=\textrm{GPU-h}×(\textrm{GPU power consumption})×\textrm{PUE}\]여기서 GPU-h는 사용된 GPU 시간을, GPU power consumption은 GPU의 전력 소비량을 나타내며, PUE(Power Usage Effectiveness)는 데이터 센터의 전력 사용 효율성을 나타내는 지표로 1.1로 설정되었습니다.
탄소 배출량의 경우, 데이터 센터의 위치에 따라 크게 달라질 수 있습니다. 예를 들어, BLOOM 모델이 학습된 데이터 센터는 kWh당 0.057kg의 이산화탄소를 배출하여 총 27 tCO₂eq를 기록한 반면, OPT 모델의 경우 kWh당 0.231kg을 배출하여 82 tCO₂eq를 기록했습니다. 공정한 비교를 위해 연구진은 미국의 평균 탄소 강도 계수인 0.385 kg CO₂eq/KWh를 적용하여 다음과 같은 공식으로 탄소 배출량을 계산했습니다.
\[\textrm{tCO}_{2}\textrm{eq}=\textrm{MWh}×0.385\]이러한 방법론을 적용하여 LLaMA 모델 시리즈의 개발에 사용된 컴퓨팅 자원을 분석한 결과, 약 5개월 동안 2048개의 A100-80GB GPU를 사용했으며, 이는 약 2,638 MWh의 전력 소비와 1,015 tCO₂eq의 탄소 배출량으로 추정됩니다. 비교를 위해 OPT 모델의 경우, 공개된 학습 로그에 따르면 992개의 A100-80GB GPU를 34일 동안 사용했습니다.
연구진은 이러한 상당한 환경 영향에도 불구하고, LLaMA 모델을 공개함으로써 향후 발생할 수 있는 탄소 배출을 줄일 수 있을 것으로 기대합니다. 특히 일부 작은 규모의 모델들은 단일 GPU에서도 실행이 가능하므로, 새로운 모델을 처음부터 학습시키는 대신 이미 학습된 모델을 활용함으로써 전체적인 탄소 발자국을 줄일 수 있습니다.
관련 연구
언어 모델의 역사적 발전은 Shannon이 1948년과 1951년에 제시한 단어, 토큰, 또는 문자 시퀀스에 대한 확률 분포의 개념에서 시작됩니다. 다음 토큰 예측이라는 형태로 정의된 이 과제는 자연어 처리 분야의 핵심 문제로 자리잡았으며, Bahl과 연구진, Brown과 연구진의 연구를 통해 그 중요성이 더욱 부각되었습니다. 특히 Turing이 1950년에 제안한 “모방 게임”을 통한 기계 지능 측정 방법론은 Mahoney가 1999년에 언어 모델링을 인공지능 발전의 척도로 제시하는 데 영향을 미쳤습니다.
아키텍처 측면에서 보면, 초기 언어 모델은 Bahl과 연구진이 제안한 n-gram 통계에 기반을 두었습니다. 이후 Katz, 그리고 Kneser와 Ney는 희소 사건(rare events)의 추정을 개선하기 위한 다양한 스무딩 기법을 제안했습니다. 지난 20년 동안 신경망이 언어 모델링 과제에 성공적으로 적용되기 시작했는데, 이는 Bengio와 연구진이 제안한 피드포워드 모델을 시작으로, Elman과 Mikolov가 발전시킨 순환 신경망(RNN), 그리고 Hochreiter와 Schmidhuber가 제안하고 Graves가 발전시킨 LSTM으로 이어졌습니다. 최근에는 Vaswani와 연구진이 제안한 셀프 어텐션 기반의 트랜스포머 네트워크가 특히 장거리 의존성 포착에서 중요한 발전을 이끌어냈으며, 이는 Radford와 연구진, 그리고 Dai와 연구진의 연구를 통해 더욱 발전되었습니다.
모델과 데이터셋 크기의 확장 측면에서도 긴 역사가 있습니다. Brants와 연구진은 2조 토큰으로 학습된 언어 모델이 기계 번역의 품질 향상에 기여함을 보여주었습니다. 이 연구는 ‘Stupid Backoff’라는 간단한 스무딩 기법을 사용했지만, 이후 Heafield와 연구진은 Kneser-Ney 스무딩을 웹 규모 데이터에 적용하는 방법을 개발했습니다. 이를 통해 Buck과 연구진은 CommonCrawl의 9,750억 토큰으로 학습된 5-gram 모델을 만들 수 있었습니다.
Chelba와 연구진이 도입한 One Billion Word 벤치마크는 언어 모델의 발전을 측정하기 위한 대규모 학습 데이터셋을 제공했습니다. 신경망 언어 모델의 맥락에서, Jozefowicz와 연구진은 10억 개의 파라미터를 가진 LSTM을 확장하여 이 벤치마크에서 최고 성능을 달성했습니다. 이후 트랜스포머의 확장은 많은 자연어 처리 과제에서 성능 향상을 이끌어냈습니다. 주목할 만한 모델들로는 Devlin과 연구진의 BERT, Radford와 연구진의 GPT-2, Shoeybi와 연구진의 Megatron-LM, 그리고 Raffel과 연구진의 T5가 있습니다.
Brown과 연구진이 개발한 1,750억 파라미터의 GPT-3는 중요한 돌파구를 마련했습니다. 이는 Jurassic-1, Megatron-Turing NLG, Gopher, Chinchilla, PaLM, OPT, GLM과 같은 대규모 언어 모델의 시대를 열었습니다.
Kaplan과 연구진은 트랜스포머 기반 언어 모델에 대한 구체적인 스케일링 법칙을 도출했으며, 이는 후에 Hoffmann과 연구진에 의해 데이터셋 크기를 조정할 때 학습률 스케줄을 적응적으로 조정하는 방식으로 개선되었습니다. 마지막으로, Wei와 연구진은 대규모 언어 모델의 스케일링이 모델의 능력에 미치는 영향을 연구했습니다.
결론
본 논문에서는 최신 기초 언어 모델들과 경쟁력을 갖추면서도 공개적으로 배포 가능한 일련의 언어 모델을 소개했습니다. 가장 주목할 만한 점은 LLaMA-13B가 GPT-3보다 10배 이상 작은 크기로도 더 우수한 성능을 보여주었으며, LLaMA-65B는 Chinchilla-70B와 PaLM-540B와 견줄 만한 성능을 달성했다는 것입니다.
이전 연구들과는 달리, 연구진은 독점적인 데이터셋에 의존하지 않고 공개적으로 접근 가능한 데이터만으로도 최고 수준의 성능을 달성할 수 있다는 것을 입증했습니다. 이러한 접근 방식은 대규모 언어 모델의 개발과 연구를 가속화하는 데 크게 기여할 것으로 기대됩니다. 특히 연구 커뮤니티에 이러한 모델들을 공개함으로써, 모델의 견고성을 개선하고 유해성이나 편향성과 같은 알려진 문제들을 완화하기 위한 노력을 지원할 수 있을 것입니다.
Chung과 연구진이 관찰한 것처럼, 이러한 모델들을 지시어로 파인튜닝했을 때 매우 유망한 결과를 얻을 수 있었습니다. 연구진은 이러한 방향의 연구를 향후 더욱 심도 있게 진행할 계획입니다. 또한 모델의 규모를 확장할수록 지속적인 성능 향상이 관찰되었기 때문에, 연구진은 앞으로 더 큰 사전 학습 코퍼스로 더 큰 규모의 모델을 공개할 계획을 가지고 있습니다.
이러한 연구 결과는 대규모 언어 모델 분야에서 중요한 이정표를 제시합니다. 특히 공개 데이터만으로도 최고 수준의 성능을 달성할 수 있다는 점은, 언어 모델 연구의 민주화와 투명성 향상에 크게 기여할 것으로 기대됩니다. 더불어 모델의 규모와 성능 사이의 관계에 대한 새로운 통찰을 제공함으로써, 향후 언어 모델 개발의 방향성을 제시했다는 점에서도 의의가 있습니다.
References
Subscribe via RSS