디스플레이 광고를 위한 단순하고 확장 가능한 응답 예측
by Criteo, Microsoft, LinkedIn
Olivier Chapelle, Eren Manavoglu, Romer Rosales의 Simple and Scalable Response Prediction for Display Advertising를 번역했습니다.
초록
클릭률과 전환율은 디스플레이 광고에서 예측해야 할, 두 개의 핵심 과제이다. 본 논문은 디스플레이 광고의 세부사항을 다루기 위해 특별히 설계한 로지스틱 회귀 기반의 기계학습 프레임워크를 제시한다. 구축한 시스템은 다음과 같은 특징을 갖는다. 구현과 배포가 쉽다. 확장성이 뛰어나다(테라바이트 단위의 데이터를 훈련시켰다). 현 시점 최고 수준의 정확도를 갖춘 모형을 제공한다.
1. 개론
디스플레이 광고는 웹 페이지에 그래픽 광고를 게재해주는 게시자에게 광고주가 비용을 지불하는 온라인 광고의 한 형태이다. 디스플레이 광고는 전통적으로 광고주와 게시자 간에 미리 협의한 장기 계약 형태로 거래되었다. 게시자의 유동성이 증대하리라는 전망이 대두되고 광고주를 위해 세분화한 잠재 고객 타겟팅 기능을 통해 도달 범위가 확대되면서 현물 시장은 지난 10년 동안 인기있는 대안이 되어왔다.
현물 시장은 광고주에게 다양한 지불 옵션을 제공한다. 광고 캠페인 목표가 타겟 잠재 고객에게 메시지를 전하는 것이라면(예: 브랜드 인지도 캠페인) 타겟팅 조건을 사용하여 노출 당 비용(CPM)을 지불하는 편이 광고주에게 적합한 선택일 것이다. 그러나 다수의 광고주는 노출을 통해 사용자가 광고주 웹 사이트로 직접 이어지지 않는 이상 광고 노출 비용을 지불하지 않기를 원한다. 이런 불만을 해결하기 위해 클릭 당 비용(CPC)과 전환 당 비용(CPA) 같은 실적 의존형 지불 모델이 도입되었다. 클릭 당 비용(CPC) 모델에서는 광고주가 광고를 클릭하는 경우에만 비용을 청구한다. 전환 당 비용(CPC) 옵션은 사용자가 웹 사이트에서 미리 정의한 동작(예: 제품 구매 또는 이메일 목록 가입)을 수행한 경우에만 비용을 지불함으로써 광고주의 위험을 더욱 줄인다. 이러한 조건부 지불 옵션을 지원하는 입찰의 경우 광고주 입찰을 기대 노출 당 비용(eCPM)으로 변환해야한다. CPM 광고의 경우 eCPM은 입찰가와 동일하다. 그러나 CPC 또는 CPA 광고의 eCPM은 노출로부터 클릭 또는 전환 이벤트가 발생할 확률에 따라 달라진다. 이 확률을 정확하게 예측해내는 것이 효율적 시장을 위해 중요하다.
검색 및 검색 광고 맥락에서 클릭 모델링에 관한 연구 작업이 상당히 있었다. 그러나 디스플레이 광고에 대한 클릭과 전환 예측은 다른 종류의 문제다. 디스플레이 광고에서 경매인은 광고 내용에 쉽게 접근할 수 없다. 경매인이 광고를 호스팅하지 않을 수도 있다. 또한 광고 내용이 사용자의 속성에 따라 동적으로 생성될 수 있다. 비슷하게 광고의 랜딩 페이지는 경매인이 알 수 없거나 동적으로 생성된 내용을 포함할 수 있다. 최근에 광고나 랜딩 페이지 내용을 캡처하려는 시도가 있지만 이 경우 적지않은 노력이 필요하며 항상 가능하지도 않다. 즉, 디스플레이 광고에 대해 내용 관련, 웹 그래프와 앵커 텍스트 정보를 갖고 있지 않으므로 경매인은 광고를 대개 고유한 식별자로 나타낸다. 하루치 데이터셋에 광고 노출이 약 100억 건 존재하지만 사용자 고유 ID 수십만 개, 고유한 페이지와 고유한 광고 각각 수백만 개가 쉽게 일반화시킬 수 없는 변수와 결합하여 희소성을 주요한 문제로 만든다.
이 논문은 샘플 수십억 개와 매개변수 수억 개로 확장할 수 있는 단순 형태의 기계학습 프레임워크를 제안하고 소량의 메모리 풋 프린트를 이용해 위에서 논의한 문제를 효과적으로 해결한다. 제안한 프레임워크는 최대 엔트로피(로지스틱 회귀라고도 함)를 이용하는데 회귀 모형 구현이 쉽기 때문에 곧 보겠지만 변수 개수에 따라 적절히 확장할 수 있고 효율적으로 병렬 처리 할 수 있다. 또한 최대 엔트로피 모형은 모형 증분 업데이트가 간단하고 쉽게 통합시킬 수 있는 탐색 전략이 있어서 편리하다. 자동화를 강화하고 도메인 전문성에 대한 의존을 줄이기 위해 2단계 변수 선택 알고리즘을 제공한다. 일반화 상호 의존 정보 방법을 사용하여 모형에 포함시킬 변수군을 선택하고 변수 해싱으로 모형 크기를 조절한다.
실제 트래픽 데이터에 대해 대규모 실험을 한 결과, 우리 프레임워크는 디스플레이 광고에 사용 중인 최첨단 모형보다 뛰어나다. 이 결과와 제안한 프레임워크의 단순함으로 말미암아 디스플레이 광고 반응 예측의 표준으로 삼을 수 있을 것이다.
논문의 나머지 부분은 다음과 같이 구성되어있다. 2장은 관련된 연구에 대해 논의한다. 3장에서는 클릭률과 전환율의 변수 차이를 살펴보고 클릭과 전환 사이의 지연을 분석한다. 4장은 프레임워크에서 사용한 최대 엔트로피 모형, 변수와 해싱 트릭을 설명한다. 이 장에서 평활화와 정규화가 점근적으로 유사함을 보인다. 5장은 제안한 모델링 기법의 결과를 제시한다. 6장에서는 변수군을 선택하고 실험 결과를 제공하기 위해 사용한 상호 의존 정보의 수정 버전을 소개한다. 분석을 통해 동기 부여된 7장에서는 탐색 알고리즘을 제안한다. 8장은 제안한 모형에 대해 효과적인 맵-리듀스 구현을 설명한다. 마지막으로 결과를 요약하여 9장에서 결론을 맺는다.
2. 관련 연구
전산 광고에서 응답 예측을 위해 개발한 학습 방법은 변수 또는 공변량으로 사용자 응답에 영향을 줄 수 있는 모든 요인을 명시적으로 포함한 회귀 또는 분류 모형을 사용한다.
이러한 모형에 사용한 변수는 다음과 같이 분류할 수 있다.
스폰서 검색에서의 질의 또는 내용 일치 시의 게시자 페이지 같은 맥락 변수
텍스트 광고의 경우 논문1에서, 디스플레이 광고의 경우 논문2에서 논의한 내용 변수
논문3에서 소개한 사용자 변수
이력 데이터를 집계하여 생성했고 논문4이 서술한 피드백 변수 .
디스플레이 광고 맥락에서 이런 변수를 모두 사용할 수 있는 건 아니다. 일반적으로 광고주와 게시자 정보는 고유 식별자로 표시된다. 각 고유 식별자가 변수로 간주되는 공간에서 차원의 크기는 주요 관심사가 된다. 이 영역에선 상호 의존 정보와 이와 유사한 필터 기법이 래퍼 기반 방법 상에서 자주 사용된다. 차원 축소를 다루기 위한 최신 접근법은 논문5에 나와있다. 해시의 기본 개념은 하위 차원 공간으로 투영하여 변수가 취할 수 있는 값의 개수를 줄이는 것이다. 이 접근법은 단순함과 경험 상의 효용으로 인하여 대규모 기계 학습 맥락에서 인기를 얻고 있다.
로지스틱 회귀와 의사 결정 트리는 전산 광고 쪽 문헌에서 널리 이용하는 모형이다. 그러나 디스플레이 광고에 의사 결정 트리를 적용하면 범주형 변수의 차원 크기가 매우 커지고 데이터가 희소한 성질을 갖게 되기에 추가로 발생하는 문제점이 있다. Kota와 Agarwal은 이득 비율을 분할 기준으로, 양성 응답에 대한 임계값을 추가 정지 기준으로 함께 이용해서 노드가 너무 많아 양성 응답 개수가 0이 되지 않도록 한다. 그런 다음 자기회귀 Gamma-Poisson 평활화를 위에서 아래로 수행하며 부모 노드의 응답률을 대체한다. 의사 결정 트리는 높은 계산 비용으로 인해 다층 접근법에서 간혹 사용한다.
로지스틱 회귀는 대용량 문제 해결을 위해 쉽게 병렬화될 수 있기에 자주 선호된다. Agarwal 등은 선형 모형을 병렬화하여 훈련 시간을 한 단계 줄인 새로운 프레임워크를 제시했다. Graepel 등은 온라인 베이지안 프로빗 회귀 모형 사용을 제안했다. 이 접근법은 점 추정 대신 모형 파리미터에 대한 사후 분포를 계산한다. 이 사후 분포는 다음 업데이트 주기 때 사전 분포로 사용된다. 저자는 탐색 수단으로써 사후 분포에서의 표본 추출을 제안했지만(Thompson 샘플링이라는 방법) 이 방법을 사용한 분석이나 실증적인 결과를 제시하지는 않았다. 우리 프레임워크는 로지스틱 회귀 프레임워크 내 유사한 기법을 이용하고 시뮬레이션 결과뿐만 아니라 Thompson 샘플링 방법에 대한 분석을 제시할 것이다.
희소한 데이터로 사용자 응답을 예측하는 일이 여러 연구의 주안점이었다. 그러나 작업의 대부분은 검색 광고에서 이뤄졌으므로 광고주 또는 광고주가 입찰한 검색어나 키워드를 사용했다. 최근에 Agarwal 등 그리고 Kota와 Agarwal은 문제를 명시적으로 해결하기 위해 데이터에 존재하는 계층 구조 이용을 제안했다. 이 방법은 표준적인 변수군으로 훈련시킨 기본 모형을 사용하여 기본 확률을 추정한 다음 게시자와 광고주 관련 변수의 계층적 성질을 활용하여 수정 계수를 학습한다. 이 모형은 쌍의 상태 매개변수를 Poisson 분포로 모델링한, 노드 쌍의 로그 선형 함수를 사용하여 전체 광고주와 게시자 경로에 대한 수정 계수를 추정해낼 수 있다는 가정을 이용한다. 그 다음 이 상태 매개변수를 추정할 때 계층적 상관 관계를 활용하기 위해 비중심화 매개변수화를 적용한다. 이건 많은 상태에서 관측치가 얼마 없고 양성 샘플이 없기 때문에 필요하다. 논문6의 접근법은 이 계층적 평활화 기법을 협업 필터링에 사용하는 행렬 분해 방법과 합친 것으로 추가적인 이득을 기록했다. 우리의 접근법은 그 대신 계층적 또는 그렇지 않은 변수 간의 관계를 연결 변수로 추가하여 동일 모형 안에서 직접 인코딩하는 것이다. 4.8절은 Tikhonov 정규화를 로지스틱 회귀와 함께 사용하면 계층적 평활화의 효과를 암시적으로 달성함을 보여준다. 따라서 본 논문의 프레임워크는 변수 간 관계를 활용하는 연결 변수와 정규화를 이용하고 모형 크기를 다루기 쉽도록 해싱하는 법을 제안한다. 이 방법론은 도메인 지식은 덜 필요로 할 것이다.(예를 들어 관계를 인코딩하기 위해 광고 캠페인이나 게시자 페이지 구조를 알 필요 없다.) 더 나은 스케일링 속성을 가지며 구현이 더 간단하다.
3. 데이터와 변수
이 장은 본 논문에서 사용한 디스플레이 광고 데이터에 관한 배경 지식을 제공한다. 자세한 내용은 논문7에서 찾을 수 있다.
3.1 데이터와 Yahoo! Real Media Exchange
세계에서 가장 큰 광고 거래소 중 하나이며 매일 광고 노출 약 10억 건을 처리하는 Yahoo! Right Media Exchange(RMX)의 실제 트래픽 기록을 연구 목적으로 수집했다. RMX는 광고주와 게시자 사이를 네트워크라고 하는 중개자가 편리하게 연결해주는 네트워크 속 네트워크 모델을 따른다. 네트워크는 게시자와 광고주 중 한쪽 또는 양쪽 모두를 가질 수 있다. 교환의 모든 주체(네트워크, 게시자와 광고주)는 고유 식별자(ID)를 갖는다.
게시자는 웹 페이지에 사이트 ID를 부여한다. 또한 동일 페이지 속 다른 부분마다 다른 섹션 ID를 태그로 지정할 수 있다. 거래소는 섹션 ID에 의미론적 규칙을 강제하진 않지만 게시자는 종종 동일 페이지의 다른 광고 슬롯마다 다른 섹션 ID를 사용한다. 네트워크와 광고주 또는 게시자 간의 관계는 가격 유형, 예산과 타겟팅 프로필 같은 일련의 특징들에 의해 정해진다.
3.2 클릭률과 전환율
우리는 클릭과 클릭 후 전환(PCC) 이벤트의 기본적인 속성을 파악하는데 관심이 있다. 본 논문의 맥락에서 클릭은 사용자가 마우스 클릭(또는 이와 동등한 방법)을 통해 광고와 상호 작용할 때 발생하는 이벤트를 말한다. 반면 클릭 후 전환은 사용자가 광고주 랜딩 페이지를 방문한 후 취하는 행동이며 해당 광고주가 가치 있다고 간주하는 것이다. 전환 행동의 전형적인 예로 이메일 목록 가입, 예약 또는 제품 구매를 포함한다. 이 두 가지 유형의 이벤트 속성을 측정하기위한 기본 수치가 클릭률(CTR)과 전환율(CVR)이다.
3.3 디스플레이 광고의 변수/공변량
이 절은 클릭률 및 전환율 모델링에 사용하는 정보 원천을 요약한다.
대부분의 온라인 광고 시스템에서 사용할 수 있는 4 가지 변수군, 즉 광고주, 게시자, 사용자와 시간 변수를 고려한다. 사용자 변수의 이용 가능 여부는 게시자마다 다르다. 각 군에 대한 대표적인 변수 목록은 표 1에서 확인할 수 있다. 위의 변수 중 일부는 범주형이 아닌 연속형이므로(예: 사용자 연령) 적절하게 구간화하였다.
표 I. 변수군으로 분류된 변수 표본.
| 변수군 | 변수 멤버 |
|---|---|
| 광고주 | 광고주(ID), 광고주 네트워크, 캠페인, 광고 소재, 전환 ID, 광고군, 광고 크기, 광고 소재 유형, 제공 유형 ID(광고 범주) |
| 게시자 | 게시자(ID), 게시자 네트워크, 사이트, 섹션, URL, 페이지 리퍼러 |
| 사용자(이용 가능한 경우) | 성별, 연령, 지역, 네트워크 속도, 쿠키 허용, 지리 |
| 시간 | 제공 시각, 클릭 시각 |
이 변수들은 이벤트 수준에서 수집된다. 즉 광고가 페이지에 표시될 때마다, 사용자가 광고를 클릭하거나 전환할 때마다 이벤트로 기록된다.
3.4 클릭 → 전환 지연 분석
이 논문에서 전환 추정 작업은 사용자가 광고를 클릭한 후 전환할 확률(클릭 후 전환, PCC)로 정의한다. PCC 모델링의 중요한 측면은 전자 메일 목록에 가입하거나 예약하거나 제품을 구입하는 식의 전환 동작으로 이어지는 클릭 이벤트를 식별하는 것이다.
전환 모형을 구축하려면 전환 이벤트가 올바른 클릭 이벤트로 분류되어야합니다. 이는 전환 이벤트가없는 클릭 이벤트에 비해 긍정적 인 PCC 사례를 나타 내기 때문입니다. 전환 이벤트는 클릭 이벤트 후 몇 분, 몇 시간 또는 며칠 후에 발생할 수 있습니다. 클릭 이벤트와 전환 이벤트 속성을 올바르게 일치시킴으로써 수행 할 수있는 마우스 오른쪽 버튼 이벤트에 대한 전환 이벤트의 적절한 속성은 PCC 예측뿐만 아니라 지불 처리에도 필수적입니다.
속성은 PCC 예측뿐만 아니라 지불 처리에도 필수적입니다. 일반적으로 광고주는 관련 광고를 클릭 한 후 사용자에게 일련의 전환 생성 페이지를 보여줄 수 있으므로 여러 전환 이벤트가 동일한 클릭과 연결될 수 있습니다. 이러한 연관 프로세스는 클릭과 전환 사이에 경과 된 시간이 길어지고 유지되고 일치되어야하는 더 많은 기록 된 이벤트가 길어질수록 실질적인 한계에 직면하게됩니다. 클릭 변환 프로세스에 대한 더 나은 그림을 얻고 해당 클릭 이벤트와 일치하는 전환에 필요한 데이터의 양에 대한 질문에 대답하기 위해 Google은 전환 이벤트의 시간 지연 속성을 분석했습니다.
그래프에서 볼 때 전환 이벤트의 대부분 (86.7 %)이 클릭 이벤트의 10 분 이내에 트리거됨을 알 수 있습니다. 이러한 전환 이벤트의 약 절반 (39.2 %)은 해당 클릭 이벤트가 발생한 후 1 분 이내에 발생합니다. 더 자세히 살펴보면 클릭 1 시간 이내에 전환 이벤트의 95.5 %가 일치 할 수 있음을 알 수 있습니다. 우리가 실질적인 경계 내에서 최대한의 리콜을 달성하는 데 관심이 있기 때문에, 우리는 여러 가지 일을 고려하기로 결정했습니다. 클릭 2 일 이내에 98.5 %의 전환을 복구 할 수 있습니다.
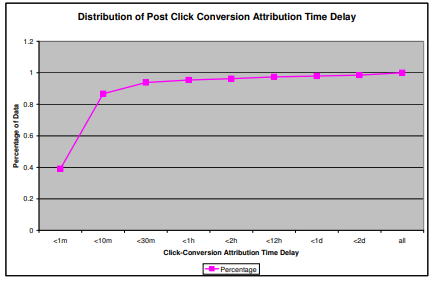
그림 1. 클릭 전환 기여 시간 지연 분포.
이러한 고려 사항은 모델링, 특히 적절한 교육 / 테스트 세트 구축에 중요합니다. 너무 짧은 시간 창을 사용하면 부정확 한 데이터 세트가 생성되는 반면, 너무 큰 시간 창을 사용하면 데이터 저장 및 일치 (클릭 변환)의 요구 사항으로 인해 실용적이지 않을 수 있습니다. 위의 실험 및 데이터를 고려할 때 전환 이벤트의 약 1.5 %는 무시할 것이므로 클릭 후 전환 기여도에 설정된 시간 프레임이 2 일로 제한되는 경우 클릭 이벤트를 음수 (전환 없음)로 잘못 표시해야합니다. 이는 시간을 더 보는데 드는 실용적인 비용을 감안할 때 충분하다고 여겨졌습니다. 따라서 우리는이 한계를 종이 전체에 걸쳐 활용합니다.
전환과 달리 클릭은 특정 광고 노출에 상대적으로 쉽게 기여할 수 있습니다. 광고가 게재되는 페이지의 클릭과 직접적인 연관성이 있기 때문입니다. 대부분의 광고 클릭 (97 %)은 광고 노출 1 분 이내에 발생합니다.
(번역 중)
-
Ciaramita, M., Murdock, V., and Plachouras, V. 2008. Online learning from click data for sponsored search. In Proceedings of the 17th international conference on World Wide Web. 227–236. Hillard, D., Sshroedl, S., Manavoglu, E., Raghavan, H., andD Leggetter, C. 2010. Improving ad relevance in sponsored search. In Proceedings of the third ACM international conference on Web search and data mining. 361–370. ↩
-
Cheng, H., Zwol, R. V., Azimi, J., Manavoglu, E., Zhang, R., Zhou, Y., and Navalpakkam, V. 2012. Multimedia features for click prediction of new ads in display advertising. In Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining. Liu, Y., Pandey, S., Agarwal, D., and Josifovski, V. 2012. Finding the right consumer: optimizing for conversion in display advertising campaigns. In Proceedings of the fifth ACM international conference on Web search and data mining. ↩
-
Cheng, H. and Cantu´-paz, E. 2010. Personalized click prediction in sponsored search. In Proceedings of the third ACM international conference on Web search and data mining. ↩
-
Chakrabarti, D., Agarwal, D., and Josifovski, V. 2008. Contextual advertising by combining relevance with click feedback. In Proceedings of the 17th international conference on World Wide Web. 417–426. Hillard, D., Schroedl, S., Manavoglu, E., Raghavan, H., and Leggetter, C. 2010. Improving ad relevance in sponsored search. In Proceedings of the third ACM international conference on Web search and data mining. 361–370. ↩
-
Weinberger, K., Dasgupta, A., Langford, J., Smola, A., and Attenberg, J. 2009. Feature hashing for large scale multitask learning. In Proceedings of the 26th Annual International Conference on Machine Learning. 1113–1120. ↩
-
Menon, A. K., Chitrapura, K.-P., Garg, S., Agarwal, D., and Kota, N. 2011. Response prediction using collaborative filtering with hierarchies and side-information. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. ↩
-
Agarwal, D., Agarwal, R., Khanna, R., and Kota, N. 2010. Estimating rates of rare events with multiple hierarchies through scalable log-linear models. In Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. 213–222. Rosales, R., Cheng, H., and Manavoglu, E. 2012. Post-click conversion modeling and analysis for nonguaranteed delivery display advertising. In Proceedings of the fifth ACM international conference on Web search and data mining. ACM, 293–302. ↩
Subscribe via RSS