판다스 코드 속도 최적화를 위한 초보자 안내서
by Sofia Heisler
Sofia Heisler의 A Beginner’s Guide to Optimizing Pandas Code for Speed를 번역했습니다.
파이썬으로 데이터 분석을 했다면 Wes McKinney가 작성한 환상적인 분석 라이브러리 판다스를 아마 사용해봤을 거다. 판다스는 데이터 프레임 분석 기능을 파이썬에 부여함으로써 파이썬을 R이나 SAS 같은 기존 분석 도구와 어깨를 나란히 하게 만들었다.
불행히도 초기 판다스는 “느리다”는 불쾌한 평판을 얻었다. 물론 판다스 코드로 완전히 최적화시킨 C 코드 계산 속도에 도달하진 못할 것이다. 그러나 좋은 소식은 잘 작성한 판다스 코드는 응용 프로그램 대부분 에서 충분히 빠르다는 것이다. 그리고 판다스의 속도 면에서 부족한 점을 강력하고 사용하기 쉬운 기능으로 만회할 수 있다는 것이다.
이 게시물에서 판다스 데이터 프레임에 함수를 적용하는 몇 가지 방법론의 효율성을 가장 느린 속도부터 가장 빠른 속도까지 나열하며 검토하겠다.
1 . 색인을 사용하여 데이터 프레임 행을 반복하는 방법
2 . iterrows()를 사용한 반복
3 . apply()를 사용한 반복
4 . 판다스 시리즈를 사용한 벡터화
5 . 넘파이 배열을 사용한 벡터화
예제 함수로 Haversine(또는 Great Circle) 거리 수식을 사용했다. 이 함수는 두 점의 위도와 경도를 취하여 지구 곡률을 조정하고 그 사이의 직선거리를 계산한다. 함수는 다음과 같다.
import numpy as np
# Haversine 기본 거리 공식을 정의함
def haversine(lat1, lon1, lat2, lon2):
MILES = 3959
lat1, lon1, lat2, lon2 = map(np.deg2rad, [lat1, lon1, lat2, lon2])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = np.sin(dlat/2)**2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon/2)**2
c = 2 * np.arcsin(np.sqrt(a))
total_miles = MILES * c
return total_miles
실제 데이터 상에서 함수를 시험해보기 위해 익스피디아 개발자 사이트에서 제공한 뉴욕 주 내 모든 호텔 좌표가 들어있는 데이터셋을 사용했다. 각 호텔과 표본 좌표(NYC의 Brooklyn Superhero Supply Store라는 환상적인 소상점) 사이 거리를 계산했다.
이 블로그에서 사용한 함수를 포함해 데이터셋 및 주피터 노트북을 여기서 다운로드할 수 있다.
이 게시물은 여기서 볼 수 있는 파이콘 토크를 기반으로 한다.
판다스에서 단순 반복, 절대 하지 말아야 할 일
먼저 판다스 데이터 구조의 기본부터 빠르게 살펴보겠다. 기본적인 판다스 구조는 데이터 프레임과 시리즈라는 두 가지 형태로 제공된다. 데이터 프레임은 축 레이블이 있는 2차원 배열이다. 즉, 데이터 프레임은 열에는 열 이름이, 행에는 색인 레이블이 붙어있는 행렬이다. 판다스 데이터 프레임의 단일 열 또는 행은 판다스 시리즈 즉, 축 레이블이 있는 1차원 배열이다.
나와 함께 일했던 판다스 초보자 거의 대부분은 데이터 프레임 행을 하나씩 반복하며 사용자 지정 함수를 적용하려고 했다. 이 접근법의 장점은 다른 반복 가능한 파이썬 객체와 상호 작용하는 방식, 예컨대 리스트나 튜플에 대해 반복하는 방식과 동일하다는 점이다. 반대로 단점은 판다스의 단순 반복이 아무 짝에 쓸데없는 가장 느린 방법이라는 점이다. 아래에서 논의할 접근법과 달리 판다스의 단순 반복은 내장된 최적화를 이용하지 않기 때문에 극히 비효율적(그리고 종종 읽기도 쉽지 않다)이다.
예를 들어 다음과 같이 작성할 수 있다.
# 모든 행을 수동으로 반복하며 일련의 거리를 반환하는 함수를 정의함
def haversine_looping(df):
distance_list = []
for i in range(0, len(df)):
d = haversine(40.671, -73.985, df.iloc[i]['latitude'], df.iloc[i]['longitude'])
distance_list.append(d)
return distance_list
위 함수를 실행하는 데 걸리는 시간을 알기 위해 %timeit 명령을 사용했다. %timeit은 주피터 노트북 용으로 특별히 제작한 “매직” 명령이다. (모든 매직 명령은 명령을 한 줄에 적용할 경우 % 기호로 시작하고 전체 주피터 셀에 적용하려면 %%로 시작한다.) %timeit은 함수를 여러 번 실행하고 얻은 실행 시간 평균과 표준 편차를 인쇄한다. 물론 %timeit으로 얻은 실행 시간은 함수를 실행시키는 시스템마다 모두 똑같진 않다. 그럼에도 동일한 시스템, 동일한 데이터셋에 대해 여러 다른 함수의 실행 시간을 비교하는데 유용할 벤치마크 도구로 제공된다.
%%timeit
# Haversine 반복 함수 실행하기
df['distance'] = haversine_looping(df)
그러면 다음 결과를 보여준다.
645 ms ± 31 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
이 단순 반복 함수는 약 645ms가 걸리고 표준 편차는 31ms이다. 이게 빠른 것처럼 보일 수도 있지만 약 1,600개 행을 처리하는데 필요한 함수임을 고려할 때 실제로 느린 것이다. 이 불행한 상태를 어떻게 개선시킬 수 있을지 살펴보겠다.
iterrows()를 사용한 반복
반복문을 돌려야 할 때 iterrows() 메서드를 사용하는 건 행을 반복하기 위한 더 좋은 방법이다. iterrows()는 데이터 프레임의 행을 반복하며 행 자체를 포함하는 객체에 덧붙여 각 행의 색인을 반환하는 제너레이터다. iterrows()는 판다스 데이터 프레임과 함께 작동하게끔 최적화되어 있으며 표준 함수 대부분을 실행하는 데 가장 효율적인 방법은 아니지만(나중에 자세히 설명) 단순 반복보다는 상당히 개선되었다. 예제의 경우 iterrows()는 행을 수동으로 반복하는 것보다 거의 똑같은 문제를 약 4배 빠르게 해결한다.
%%timeit
# 반복을 통해 행에 적용되는 Haversine 함수
haversine_series = []
for index, row in df.iterrows():
haversine_series.append(haversine(40.671, -73.985, row['latitude'], row['longitude']))
df['distance'] = haversine_series
166 ms ± 2.42 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
apply 메서드를 사용한 더 나은 반복
iterrows()보다 더 좋은 옵션은 데이터 프레임의 특정 축(행 또는 열을 의미)을 따라 함수를 적용하는 apply() 메서드를 사용하는 것이다. apply()는 본질적으로 행을 반복하지만 Cython에서 이터레이터를 사용하는 것 같이 내부 최적화를 다양하게 활용하므로 iterrows()보다 훨씬 효율적이다.
익명의 람다 함수를 사용하여 Haversine 함수를 각 행에 적용하며 각 행의 특정 셀을 함수 입력값으로 지정할 수 있다. 람다 함수는 판다스가 행(축 = 1)과 열(축 = 0) 중 어디에 함수를 적용할지 정할 수 있게 축 매개 변수를 마지막에 포함한다.
%%timeit
# Haversine 함수를 시간 재며 어플라이함
df['distance'] = df.apply(lambda row: haversine(40.671, -73.985, row['latitude'], row['longitude']), axis=1)
90.6 ms ± 7.55 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
iterrows()를 apply()로 바꾸면 함수 실행 시간이 반으로 줄어든다!
실제로 함수 내 어느 부분이 얼마만큼 실행 시간 걸리는지 알기 위해 라인 프로파일러 도구(주피터에서 %lprun magic 명령)를 실행할 수 있다.
# 라인 프로파일러와 함께 Haversine을 행에 대해 어플라이함
%lprun -f haversine df.apply(lambda row: haversine(40.671, -73.985, row['latitude'], row['longitude']), axis=1)
다음 결과를 보여준다.

이 정보로부터 여러 유용한 통찰을 얻을 수 있다. 예를 들어 삼각 함수 계산을 수행하는 함수 부분이 전체 실행 시간의 거의 절반을 차지한다. 따라서 함수 개별 구성 요소를 최적화하려는 경우 해당 함수부터 시작하는 것이 좋다. 지금 당장은 각 행이 1,631번 이상 실행된다는 사실을 아는 게 중요하다. 각 행마다 apply()를 반복 적용한 결과다. 반복되는 작업량을 줄일 수 있다면 전반적인 실행 시간을 줄일 수 있다. 벡터화가 훨씬 더 효율적인 대안으로 등장하는 지점이다.
판다스 시리즈를 사용한 벡터화
함수 수행의 반복량 줄이는 방법을 이해하기 위해 판다스의 기본 단위, 데이터 프레임과 시리즈가 모두 배열 기반임을 알아두자. 기본 단위의 내부 구조는 개별 값(스칼라라고 함)마다 순차적으로 작동하는 대신 전체 배열 위로 작동하도록 설계된 내장 판다스 함수를 위해 변환된다. 벡터화는 전체 배열 위로 작업을 실행하는 프로세스다.
판다스는 수학 연산에서 집계 및 문자열 함수(사용 가능한 함수의 광범위한 목록은 판다스 문서에서 확인해라)에 이르기까지 다양한 벡터화 함수를 포함하고 있다. 내장 함수는 판다스 시리즈와 데이터 프레임에서 작동하게끔 최적화되어있다. 결과적으로 벡터화 판다스 함수를 사용하는 건 비슷한 목적을 위해 손수 반복시키는 방법보다 거의 항상 바람직하다.
지금까지는 Haversine 함수에 스칼라를 전달했다. 그러나 Haversine 함수 내에서 사용하는 모든 함수를 배열 위로 작동시킬 수 있다. 이렇게 하면 거리 함수를 매우 간단하게 벡터화할 수 있다. 스칼라 값으로 각 위도, 경도를 전달하는 대신 전체 시리즈(열)를 전달한다. 이를 통해 판다스는 벡터화 함수에 적용 가능한 모든 최적화 옵션을 활용할 수 있고 특히 전체 배열에 대한 모든 계산을 동시에 수행하게 된다.
%%timeit
# 판다스 시리즈에 적용하는 Haversine 벡터화 구현
df['distance'] = haversine(40.671, -73.985, df['latitude'], df['longitude'])
1.62 ms ± 41.5 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
함수 벡터화를 통해 apply() 메서드 대비 50배 이상 개선시켰고 iterrows() 대비 100배 이상 개선시켰다. 입력 유형 변경하는 것 외에 아무것도 하지 않아도 됐다!
과정 내부를 엿보며 함수가 무얼 했는지 파악해보자.

apply()가 함수를 1,631번 이용하는 동안 벡터화 버전은 함수를 딱 한 번 적용했다는 점에 주목해라. 함수를 전체 배열에 대해 동시 적용하기 때문이다. 그게 시간을 크게 단축시킨 요인이다.
넘파이 배열을 사용한 벡터화
이 지점에서 그만두어도 괜찮다. 판다스 시리즈를 사용해 벡터화하면 상시 계산을 위한 최적화 요구 사항의 거의 대부분을 만족시킬 수 있다. 그러나 속도가 최우선이라면 넘파이 파이썬 라이브러리 형식에 도움을 요청해볼 수 있다.
넘파이 라이브러리는 “과학 계산을 위한 파이썬 기본 패키지”를 표방하며 내부가 최적화된, 사전 컴파일된 C 코드로 작업을 수행한다. 판다스와 마찬가지로 넘파이는 배열 객체(ndarrays라고 함) 상에서 작동한다. 그러나 색인, 데이터 유형 확인 등과 같이 판다스 시리즈 작업으로 인한 오버헤드가 많이 발생하지 않는다. 결과적으로 넘파이 배열에 대한 작업은 판다스 시리즈에 대한 작업보다 훨씬 빠르다.
판다스 시리즈가 제공하는 추가 기능이 중요하지 않을 때 넘파이 배열을 판다스 시리즈 대신 사용할 수 있다. 예를 들어 Haversine 함수의 벡터화 구현은 실제로 위도 또는 경도 시리즈의 색인을 사용하지 않으므로 사용할 수 있는 색인이 없어도 함수가 중단되지 않는다. 이에 비해 색인으로 값을 참조해야 하는 데이터 프레임의 조인 같은 작업을 수행한다면 판다스 개체를 계속 사용하는 편이 낫다.
위도와 경도 배열을 시리즈의 values 메서드를 단순 사용해서 판다스 시리즈에서 넘파이 배열로 변환한다. 시리즈의 벡터화와 마찬가지로 넘파이 배열을 함수에 직접 전달하면 판다스가 전체 벡터에 함수를 적용시킨다.
%%timeit
# 넘파이 배열에 적용하는 Haversine 벡터화 구현
df['distance'] = haversine(40.671, -73.985, df['latitude'].values, df['longitude'].values)
370 µs ± 18 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
넘파이 배열에 연산을 실행해서 또 다른 4배 개선을 이뤄냈다. 결론적으로 넘파이 벡터화를 통해 반복을 통한 30분의 1초에서 3분의 1 밀리 초로 실행 시간을 개선시켰다!
요약
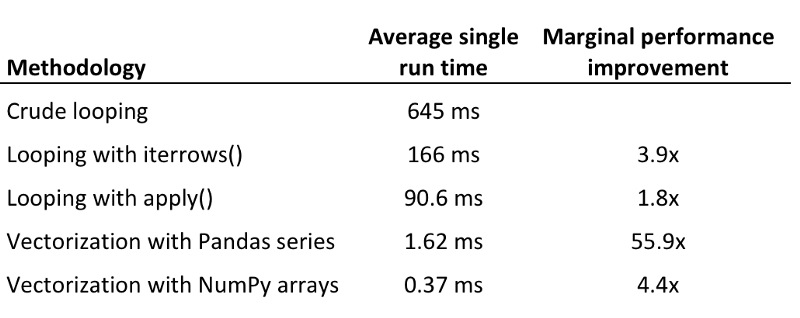
아래 점수판이 결과 요약이다. 넘파이 배열을 사용해 벡터화했을 때 실행 시간이 가장 빨랐다. 그러나 가장 빠른 버전의 반복 방법 대비 무려 56배 향상한, 판다스 시리즈를 사용한 벡터화가 가장 큰 한계 개선폭을 보였다.
판다스 코드 최적화에 관해 몇 가지 기본적인 결론을 내릴 수 있다.
1 . 반복을 피해라. 사용 사례 대부분의 경우 반복은 느리고 불필요하다.
2 . 반복해야 하는 경우 반복 함수가 아닌 apply()를 사용해라.
3 . 보통은 벡터화가 스칼라 연산보다 낫다. 대부분의 판다스 작업은 벡터화시킬 수 있다.
4 . 넘파이 배열에서의 벡터 연산은 판다스 시리즈에서 수행하는 것보다 효율적이다.
물론 상기한 목록이 판다스 최적화에 대해 가능한 모든 내용을 담고 있지는 않다. 예를 들어 Cython에서 함수를 재작성하거나 함수 개별 구성 요소마다 최적화시키려고 시도하는 등 보다 모험을 좋아하는 사용자가 있을 수 있다. 그러나 해당 주제는 본 게시물 범위를 벗어난다.
최적화의 모험, 그 대단원의 막을 올리기 전에 최적화시키려는 함수가 실제 장기적으로 사용하는 함수인지 확인하는 게 중요하다. xkcd의 명언을 인용하자면 “너무 이른 최적화는 모든 악의 근원이다.”
편집: 인용했던 “너무 이른 최적화”의 원저자가 xkcd가 아니라 Donald Knuth임을 지적받았다. 의도치 않게 누락시킨 점 사과드리며 독자분들의 너른 양해 부탁드린다. :)
Subscribe via RSS