LightGBM 고효율 그래디언트 부스팅 결정 트리
by Microsoft Research, Peking University, Microsoft Redmond
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu의 LightGBM: A Highly Efficient Gradient Boosting Decision Tree을 번역했습니다.
초록
그래디언트 부스팅 결정 트리(GBDT)는 널리 사용하는 기계 학습 알고리즘이며 XGBoost와 pGBRT 같이 효율적으로 구현해놓은 것들이 몇 가지 있다. 해당 구현은 엔지니어링의 많은 요소를 최적화시켰지만 고차원 변수에 데이터 크기가 큰 경우 효율성과 확장성은 여전히 불만족스럽다. 주된 이유로 각 변수마다 가능한 모든 분할점에 대해 정보 획득을 평가하려면 데이터 개체 모두 훑어야 하는데 이에 많은 시간이 소요된다는 점이다. 이 문제를 해결하기 위해 기울기 기반 단측 표본추출(GOSS)과 배타적 변수 묶음(EFB)이라는 두 가지 새로운 기술을 제안한다. GOSS를 통해 데이터 개체 중 기울기가 작은 상당 부분을 제외시키고 나머지만 사용하여 정보를 얻을 수 있다. 기울기가 큰 데이터 개체가 정보 획득 계산에 더 중요한 역할을 하기 때문에 GOSS는 훨씬 작은 크기의 데이터로 정보 획득을 매우 정확하게 추정해낼 수 있다. EFB를 통해 변수 개수를 줄이기 위해 상호 배타적 변수들(예컨대, 0이 아닌 값을 동시에 갖는 일이 거의 없는 변수들)을 묶는다. 배타적 변수의 최적 묶음을 찾는 일은 NP-hard지만 탐욕 알고리즘을 통해 매우 괜찮은 근사 비율을 얻을 수 있다. 따라서 분할점 결정 정확도를 크게 훼손시키지 않으면서 변수 개수를 효과적으로 줄일 수 있다. GOSS와 EFB 적용하여 GBDT를 새롭게 구현한 걸 LightGBM라고 부르겠다. 여러 공용 데이터셋에 대한 실험은 LightGBM이 기존 GBDT 훈련 과정을 최대 20배 이상 빠르게 하면서 정확도는 거의 동일하게 달성함을 보여준다.
1. 개론
그래디언트 부스팅 결정 트리(GBDT)는 효율성, 정확도, 해석 가능성이 높아 널리 사용되는 기계 학습 알고리즘이다. GBDT는 멀티 클래스 분류, 클릭 예측, 순위 학습 같이 다양한 기계 학습 작업에서 최고의 성능을 보여준다. 최근 빅데이터(변수 개수와 개체 수 모두) 등장으로 GBDT는 특히 정확도와 효율성 간의 트레이드 오프라는 새로운 숙제에 직면했다. GBDT 기존 구현은 각 변수마다 가능한 모든 분할점에 대해 정보 획득을 평가하기 위해 데이터 개체 모두 훑어야 한다. 따라서 계산 복잡도는 변수 개수와 개체 수에 비례한다. 따라서 빅데이터 처리 시 해당 구현은 매우 시간 소모적이게 된다.
데이터 개체 수와 변수 개수를 줄이는 게 문제 해결을 위한 즉각적 아이디어이다. 그러나 이 작업은 꽤나 단순하지 않다. 예를 들어 GBDT를 위해 데이터 표본 추출을 수행하는 방법이 불명확하다. 부스팅 훈련 과정의 속도가 향상하기 위해 가중치에 따라 데이터 표본 추출하는 작업물이 있지만 GBDT에는 표본 가중치가 전혀 없으므로 직접 적용할 수 없다. 본 논문은 목표를 위해 두 가지 새로운 기술을 제안한다.
기울기 기반 단측 표본추출(GOSS). GBDT의 경우 데이터 개체에 대한 기본 가중치는 없지만 서로 다른 기울기를 가진 데이터 개체가 정보 획득 계산 시 서로 다른 역할을 한다는 점은 알고 있다. 정보 획득의 정의로 보자면 기울기가 보다 큰1(즉, 과소 훈련시킨 개체) 개체가 정보 획득에 더 기여할 것이다. 따라서 데이터 개체를 다운 샘플링할 때 정보 획득 추정의 정확도를 유지하려면 기울기가 큰 개체(예컨대 미리 정의한 임계 값보다 크거나 백분위로 상위인)를 보다 많이 유지해야 하며 기울기가 작은 개체는 무작위로 떨궈야 한다. 이런 방식이 타깃 변수마다 동일한 표본 추출 비율로 균일하게 무작위 표본 추출하는 것보다 더 정확하게 정보 획득을 추정해낼 수 있음(정보 획득 값의 범위가 큰 경우 특히나)을 증명할 것이다.
배타적 변수 묶음(EFB). 실제 응용 프로그램은 일반적으로 많은 수의 변수를 갖지만 변수 공간은 매우 희소하여 변수 개수를 효과적으로 줄이기 위한 거의 손실 없는 방식을 만들어낼 수 있다. 특히 희소한 변수 공간에서 많은 변수들이 (거의) 배타적이다. 즉, 변수들은 0이 아닌 값을 동시에 갖는 일이 거의 없다. 예로 원-핫 변수(텍스트 마이닝의 원-핫 단어 표현 같은)가 있다. 이런 배타적 변수들은 안전하게 묶을 수 있다. 결국 최적 묶음 문제를 그래프 색칠 문제(변수를 각 꼭짓점에 두고 두 변수가 상호 배타적이지 않으면 두 변수를 잇는 변을 추가함으로써)로 바꾸는 효율적인 알고리즘을 설계했고 일정 근사 비율을 갖는 탐욕 알고리즘으로 문제를 해결했다.
GOSS와 EFB 적용하여 GBDT를 새롭게 구현한 걸 LightGBM2라고 부르겠다. 여러 공용 데이터셋에 대한 실험은 LightGBM이 기존 GBDT 훈련 과정을 최대 20배 이상 빠르게 하면서 정확도는 거의 동일하게 달성함을 보여준다.
본 논문의 나머지 부분은 다음과 같이 구성된다. 먼저 2장에서 GBDT 알고리즘과 관련 작업을 검토한다. 3장에서는 GOSS 세부 사항을, 4장에서는 EFB를 소개한다. 공용 데이터셋에 대한 LightGBM 실험은 5장에서 설명한다. 마지막으로 6장에서 결론을 맺는다.
2. 서두
2.1 GBDT 및 복잡도 분석
GBDT는 결정 트리를 순차적으로 훈련시키는 앙상블 모형이다. 각 반복마다 GBDT는 음의 기울기(잔차 오차라고도 함)에 적합시켜 의사 결정 트리를 학습한다. GBDT 주요 비용은 의사 결정 트리 학습에서 발생하며 의사 결정 트리를 학습시키는 데 시간 소요가 가장 큰 부분이 최적 분할점 탐색이다. 분할점 탐색을 위해 가장 많이 사용되는 알고리즘 중 하나는 사전 정렬 알고리즘으로 사전 정렬한 변수 값에 대해 가능한 모든 분할점을 나열한다. 이 알고리즘은 간단하며 최적 분할점을 찾아낼 수 있지만 훈련 속도와 메모리 소비 모든 면에서 비효율적이다. 인기 있는 다른 알고리즘으로 알고리즘 13에 적힌 히스토그램 기반 알고리즘이 있다. 정렬한 변수 값에서 분할점을 찾는 대신 히스토그램 기반 알고리즘은 연속적인 변수 값을 개별 구간으로 나누고 이 구간을 사용하여 훈련 시 변수 히스토그램을 만든다. 히스토그램 기반 알고리즘은 메모리 소비와 훈련 속도에서 보다 효율적이므로 이를 바탕으로 작업을 진행했다. 알고리즘 1에 적힌 대로 히스토그램 기반 알고리즘은 변수 히스토그램을 기반으로 최적 분할점을 찾는다. 히스토그램 만드는 일에 \(O(\# data \times \# feature)\), 분할점 찾는 일에 \(O(\# bin \times \# feature)\)가 필요하다. #bin은 대개 #data보다 훨씬 작기 때문에 히스토그램 만드는 일이 계산 복잡도를 좌우한다. #data 또는 #feature를 줄인다면 GBDT 훈련은 상당히 빨라질 것이다.
알고리즘 1: 히스토그램 기반 알고리즘
입력: \(I\): 훈련 데이터, \(d\): 최대 깊이, \(m\): 변수 차원
\(nodeSet \leftarrow \{0\} \triangleright\) 현재 깊이에서의 트리 노드들
\(rowSet \leftarrow \{\{0, 1, 2, \ldots \}\} \triangleright\) 트리 노드에서의 데이터 색인들
for i \(= 1\) to \(d\) do
\(\qquad\) for node in \(nodeSet\) do
\(\qquad\qquad\) usedRows \(\leftarrow rowSet\)[node]
\(\qquad\qquad\) for k \(= 1\) to \(m\) do
\(\qquad\qquad\qquad\) \(H \leftarrow\) new Histogram() \(\triangleright\) 히스토그램 생성
\(\qquad\qquad\qquad\) for j in usedRows do
\(\qquad\qquad\qquad\qquad\) bin \(\leftarrow I\).f[k][j].bin
\(\qquad\qquad\qquad\qquad\) \(H\)[bin].y \(\leftarrow H\)[bin].y \(+ I\).y[j]
\(\qquad\qquad\qquad\qquad\) \(H\)[bin].n \(\leftarrow H\)[bin].n \(+ 1\)
\(\qquad\qquad\qquad\) 히스토그램 \(H\)의 최적 분할점을 찾는다.
\(\qquad\qquad\qquad\) \(\ldots\)
\(\qquad\qquad\) 최적 분할점을 적용해 \(rowSet\)과 \(nodeSet\)을 업데이트한다.
\(\qquad\qquad\) \(\ldots\)
2.2 연관 작업
XGBoost, pGBRT, scikit-learn, R의 gbm4을 포함해 GBDT를 꽤 여러 종류로 구현해놨다. Scikit-learn과 R의 gbm은 사전 정렬 알고리즘을 구현했고 pGBRT는 히스토그램 기반 알고리즘을 구현했다. XGBoost는 사전 정렬 알고리즘과 히스토그램 기반 알고리즘 모두 지원한다. 논문5에서 볼 수 있듯이 XGBoost가 다른 것들을 능가한다. 그래서 본 논문 실험 시 XGBoost를 기준선으로 삼았다.
훈련 데이터 크기를 줄이기 위한 일반적인 방법은 데이터 개체를 다운 샘플링하는 것이다. 예를 들어 논문6은 데이터 개체 가중치가 고정 임계값보다 작을 경우 해당 데이터 개체를 거른다. SGB는 각 반복마다 약한 학습기를 훈련시키기 위해 임의의 부분 집합을 사용한다. 논문7은 표본 추출 비율을 훈련 과정마다 동적으로 조정한다. 단 SGB를 제외한 모든 작업은 AdaBoost를 기반으로 하는데 GBDT는 Adaboost와 달리 데이터 개체마다 기본 가중치가 없기 때문에 직접 적용하긴 어렵다. SGB는 GBDT에 적용할 수 있지만 일반적으로 정확도가 떨어지므로 바람직한 선택이 아니다.
비슷하게 변수 개수를 줄이기 위해 설명력이 약한 변수부터 거르는 게 자연스럽다. 이를 위해 주성분 분석이나 사영 추적을 보통 사용한다. 그러나 이런 접근은 변수들이 중복 요소를 상당히 갖고 있다는, 실제로 그렇지 않을 수 있는 가정에 크게 의존한다(일반적으로 변수마다 고유한 기여도를 갖게끔 설계하며 그중 하나라도 제거하면 훈련 정확도에 어느 정도 영향을 미친다).
실제 응용 프로그램에서 사용하는 대규모 데이터셋은 보통 굉장히 희소하다. 사전 정렬 알고리즘을 사용하는 GBDT의 경우 변숫값이 0인 개체는 무시함으로써 학습 비용을 줄일 수 있다. 그러나 히스토그램 기반 알고리즘을 사용하는 GBDT의 경우 효율적인 희소 변수 최적화 해법은 없다. 히스토그램 기반 알고리즘은 변수 값 0 여부와 상관없이 각 데이터 개체마다 변수 구간 값(알고리즘 1 참조)을 검색해야 하기 때문이다. 히스토그램 기반 알고리즘 적용 GBDT가 희소 변수를 효과적으로 활용할 수 있는 방안이 매우 요구된다.
이전 작업의 한계점을 해결하기 위해 기울기 기반 단측 표본 추출(GOSS)과 배타적 변수 묶음(EFB)이라는 두 가지 새로운 기술을 제시한다. 자세한 내용은 이어지는 장에서 소개할 것이다.
3. 기울기 기반 단측 표본 추출
이번 장에서는 데이터 개체 수를 줄이는 것과 학습한 의사 결정 트리 정확도를 유지하는 것 사이에서 균형을 잘 잡을 수 있는 GBDT의 새로운 표본 추출 방법을 제안한다.
3.1 알고리즘 서술
AdaBoost에서의 표본 가중치는 각 데이터 개체의 중요도를 알려주는 좋은 지표이다. 그러나 GBDT의 경우 표본 기본 가중치가 없으므로 AdaBoost에 제안된 표본 추출 방법을 직접 적용할 순 없다. 다행히도 GBDT에서 각 데이터 개체에 대한 기울기는 데이터 표본 추출에 유용한 정보를 제공한다. 즉, 개체의 기울기가 작다면 해당 개체에 대한 훈련 오차가 작고 이미 잘 훈련된 것이다. 단순한 아이디어는 기울기가 작은 데이터 개체를 버리는 것이다. 그러나 그렇게 하면 데이터 분포가 바뀌므로 학습 모형의 정확도를 저하시킬 수 있다. 이 문제를 피하기 위해 기울기 기반 단측 표본 추출(GOSS)이라는 새로운 방법을 제안한다.
GOSS는 기울기가 큰 개체는 모두 유지하되 기울기가 작은 개체에 대해 무작위 표본 추출을 수행한다. 이때 데이터 분포에 미치는 영향을 보정하기 위해서 정보 획득 계산 시 기울기가 작은 데이터 개체에 승수 상수를 적용한다(알고리즘 2 참조). 구체적으로 우선 GOSS는 기울기 절댓값에 따라 데이터 개체를 정렬하고 상위 \(a \times 100 \%\) 개체를 선택한다. 그런 다음 나머지 데이터에서 \(b \times 100 \%\) 개체를 무작위 표본 추출한다. 그 후 GOSS는 정보 획득을 계산할 때 기울기가 작은 표본 데이터를 상수 \(1 - a \over b\)만큼 증폭시킨다. 이렇게 함으로써 원래의 데이터 분포를 많이 변경하지 않고도 훈련이 덜 된 개체에 초점을 보다 잘 맞출 수 있다.
알고리즘 2: 기울기 기반 단측 표본 추출
입력: \(I\): 훈련 데이터, \(d\): 최대 깊이, \(a\): 기울기 큰 데이터의 표본 추출 비율
입력: \(b\): 기울기 작은 데이터의 표본 추출 비율, \(loss\): 손실 함수, \(L\): 약한 학습기
models \(\leftarrow \{ \} \), fact \(\leftarrow {1 - a \over b}\), topN \(\leftarrow a \times\) len(\(I\)), randN \(\leftarrow b \times\) len(\(I\))
for i \(= 1\) to \(d\) do
\(\qquad\) preds \(\leftarrow\) models.predict(\(I\))
\(\qquad\) g \(\leftarrow loss\)(\(I\), preds), w \(\leftarrow \{1, 1, \ldots \} \)
\(\qquad\) sorted \(\leftarrow\) GetSortedIndices(abs(g))
\(\qquad\) topSet \(\leftarrow\) sorted[1:topN]
\(\qquad\) randSet \(\leftarrow\) RandomPick(sorted[topN:len(\(I\))], randN)
\(\qquad\) usedSet \(\leftarrow\) topSet \(+\) randSet
\(\qquad\) w[randSet] \(\times =\) fact \(\triangleright\) 기울기 작은 데이터에 가중치 fact를 부여함
\(\qquad\) newModel \(\leftarrow\) \(L\)(\(I\)[usedSet], \(-\) g[usedSet], w[usedSet])
\(\qquad\) models.append(newModel)
3.2 이론적 분석
GBDT는 결정 트리를 사용하여 입력 공간 \(\mathcal{X}^s\)에서 기울기 공간 \(\mathcal{G}\)까지의 함수를 학습한다. \(n\)개의 i.i.d 개체 \(\{x_1, \ldots, x_n\}\)의 훈련 셋을 가지고 있다고 가정하자. 각 \(x_i\)는 공간 \(\mathcal{X}^s\)내 차원이 \(s\)인 벡터다. 그래디언트 부스팅 매 회 반복마다 발생하는, 모형 출력 값에 대한 손실 함수의 음의 기울기를 \(\{g_1, \ldots, g_n\}\)로 정의하자. 의사 결정 트리 모형은 가장 정보력 있는 변수(정보 획득이 가장 큰)로 각 노드를 분할한다. GBDT의 경우 정보 획득은 분할 후 분산으로 보통 측정하며 다음과 같이 정의된다.
정의 3.1 \(O\)를 의사 결정 트리의 미리 정한 노드 안에 있는 훈련 데이터셋이라고 하자. 이 노드에 대해 점 \(d\)에서 분할하는 변수 \(j\)의 분산 획득은 다음과 같이 정의된다.
\[V_{j|O}(d) = {1 \over n_O} \left( {(\sum_{x_i \in O: x_{ij} \le d} g_i )^2 \over n^j_{l|O}(d)} + {(\sum_{x_i \in O: x_{ij} > d} g_i )^2 \over n^j_{r|O}(d)} \right),\]여기서 \(n_O = \sum I[ x_i \in O ],\) \(n^j_{l|O}(d) = \sum I [ x_i \in O: x_{ij} \le d ],\) \(n^j_{r|O}(d) = \sum I [x_i \in O: x_{ij} > d ]\)이다.
변수 \(j\)에 대해 결정 트리 알고리즘은 \(d^*_j = argmax_d V_j(d)\)를 선택하고 최대 획득 \(V_j(d^*_j)\)를 계산한다.8 그런 다음 데이터를 변수 \(j^*\)의 점 \(d_{j^*}\)에 따라 왼쪽과 오른쪽 하위 노드로 분할한다.
제안된 GOSS 방법론은 우선 기울기 절댓값에 따라 훈련 개체 순위를 내림차순으로 매긴다. 그런 다음 기울기가 큰 상위 \(\alpha \times 100\%\) 개체를 가지고 개체 부분 집합 \(A\)를 만든다. \((1 - \alpha) \times 100\%\)의 기울기가 작은 개체가 속하는 여집합 \(A^c\)에 대해 \(b \times | A^c |\) 크기의 부분 집합 \(B\)를 무작위 표본 추출하여 만든다. 마지막으로 부분 집합 \(A \cup B\)에 대해 추정 분산 획득 \(\tilde{V}_j(d)\)을 적용하여 개체를 분할한다. 추정 분산 획득은
\[\tilde{V}_j(d) = {1 \over n} \left( {( \sum_{x_i \in A_l} g_i + {1 - a \over b} \sum_{x_i \in B_l} g_i )^2 \over n^j_l(d)} + {( \sum_{x_i \in A_r} g_i + {1 - a \over b} \sum_{x_i \in B_r} g_i )^2 \over n^j_r(d)} \right),\]이다. 여기서 \(A_l = \{x_i \in A: x_{ij} \le d \},\) \(A_r = \{x_i \in A: x_{ij} > d \},\) \(B_l = \{x_i \in B: x_{ij} \le d \},\) \(B_r = \{x_i \in B: x_{ij} > d \}\)이고 계수 \({1 - a \over b}\)는 \(B\)의 기울기 합을 \(A^c\) 크기에 맞게 정규화하는 데 사용한다.
따라서 GOSS는 분할점 결정 시 모든 개체를 사용한 정확한 \(V_j(d)\) 대신 더 적은 수의 개체 부분 집합을 통해 추정한 \(\tilde{V}_j(d)\)를 이용하므로 계산 비용을 크게 줄일 수 있다. 보다 중요하게, 다음 정리는 GOSS가 훈련 정확도를 많이 저하시키지 않고 무작위 표본 추출보다 우수함을 보여준다. 지면의 제약으로 보충 자료에 정리의 증명을 남긴다.
정리 3.2 GOSS의 근사 오차를 \(\mathcal{E}(d) = | \tilde{V}_j(d) - V_j(d) |\)로 정의하고 \(\bar{g}^j_l(d) = { \sum_{x_i \in ( A \cup A^c )_l} | g_i | \over n^j_l(d)},\) \(\bar{g}^j_r(d) = { \sum_{x_i \in ( A \cup A^c )_r} | g_i | \over n^j_r(d)}\)라고 하자. 적어도 \(1 - \delta\)의 확률로
\[\mathcal{E}(d) \le C^2_{a, b} \ln 1/\delta \cdot max \left\{ {1 \over n^j_l(d)}, {1 \over n^j_r(d)} \right\} + 2DC_{a, b}\sqrt{\ln 1 / \delta \over n},\]이다. 여기서 \(C_{a, b} = {1 - a \over \sqrt{b}} max_{x_i \in A^c} |g_i|\)이고 \(D = max(\bar{g}^j_l(d), \bar{g}^j_r(d))\)이다.
정리에 의거해 다음과 같이 논의해볼 수 있다. (1) GOSS의 점근적 근사 비율은 \(\mathcal{O} \left( {1 \over n^j_l(d)} + {1 \over n^j_r(d)} + {1 \over \sqrt{n}} \right)\)이다. 한쪽으로 치우쳐 분할되지 않았다면(즉, \(n^j_l(d) \ge \mathcal{O}(\sqrt{n})\)이거나 \(n^j_r(d) \ge \mathcal{O}(\sqrt{n})\)), \(n \rightarrow \infty\)일 때 \(\mathcal{O}(\sqrt{n})\) 속도로 0으로 감소하는 부등식 두 번째 항이 근사 오차를 좌우한다. 즉, 데이터 수가 많다면 근삿값은 상당히 정확하다. (2) 무작위 표본 추출은 \(a = 0\)인 GOSS의 특수한 경우다. 대다수의 경우 \(C_{0, \beta} > C_{a, \beta - a}\)와 동치인 \({\alpha_a \over \sqrt{\beta}} > {1 - a \over \sqrt{\beta - a}}\) (여기서 \(\alpha_a = max_{x_i \in A \cup A^c} |g_i| / max_{x_i \in A^c} |g_i|\)) 조건을 만족하며 이때 GOSS는 무작위 표본 추출보다 우수하다.
다음으로 GOSS의 일반화 성능을 분석했다. GOSS가 표본 추출한 훈련 개체로 계산한 분산 획득과 기본 분포로 계산한 실제 분산 획득 사이의 차이인 GOSS의 일반화 오차 \(\mathcal{E}^{GOSS}_{gen}(d) = | \tilde{V}_j(d) - V_*(d) |\)를 고려하자. \(\mathcal{E}^{GOSS}_{gen}(d) \le | \tilde{V}_j(d) - V_j(d) | + | V_j(d) - V_*(d) | \triangleq \mathcal{E}_{GOSS}(d) + \mathcal{E}_{gen}(d)\)이다. 따라서 GOSS 근사가 정확하다면 GOSS의 일반화 오차는 데이터 전체 개체를 사용하여 계산한 오차와 비슷할 것이다. 반면에 표본 추출은 기본 학습기의 다양성을 증가시켜 잠재적으로 일반화 성능이 향상하는데 도움을 준다.
4. 배타적 변수 묶음
이 장에서는 변수 개수를 효과적으로 줄이는 새로운 방법을 제안한다.
고차원 데이터는 일반적으로 매우 희소하다. 변수 공간의 희소성은 변수 개수를 줄일 때 손실이 거의 없는 방법 설계에 관한 단초를 제공한다. 특히 희소 변수 공간에선 변수 다수가 상호 배타적이다. 즉, 0이 아닌 값을 동시에 갖지 않는다. 배타적 변수를 단일 변수(이를 배타적 변수 묶음이라고 함)로 안전하게 묶을 수 있다. 신중하게 설계한 변수 탐색 알고리즘을 통해 개별 변수들의 히스토그램과 동일한 것을 변수 묶음을 통해 만들어낼 수 있다. 이 경우 히스토그램 생성 복잡도는 \(O(\# data \times \# feature)\)에서 \(O(\# data \times \# bundle)\)로 바뀐다. #bundle « #feature라고 할 때 정확도를 저하시키지 않으면서 GBDT 훈련 속도가 크게 향상할 수 있다. 이제 이게 어떻게 달성 가능한지 상세히 설명할 것이다.
해결해야 할 두 가지 문제가 있다. 첫째, 어떤 변수를 함께 묶을지 결정하는 것이다. 둘째, 어떻게 묶을까 방법에 관한 것이다.
정리 4.1 가장 적은 수의 배타적 묶음으로 변수를 나누는 문제는 NP-hard이다.
증명: 우리 문제를 그래프 색칠 문제로 한정 지을 수 있다. 그래프 색칠 문제는 NP-hard이기 때문에 결론은 추론 가능하다.
그래프 색칠 문제에서 임의의 그래프를 \(G = (V, E)\)라고 하자. 우리 문제에 해당하는 그래프는 다음과 같이 만들 수 있다. \(G\)의 발생 행렬 각 행이 각 변수에 해당하게끔 \(|V|\)개 변수를 이용하여 우리 문제에 해당하는 그래프를 얻는다. 우리 문제에서 배타적 변수 묶음이 같은 색깔을 갖는 꼭짓점 집합에 해당함을 쉽게 알 수 있으며 반대 경우도 마찬가지다.
첫 번째 문제에 대해 다항 시간 안에 정확한 해를 찾는 것이 불가능함을, 즉 최적 묶음 전략을 찾는 게 NP-hard임을 정리 4.1을 통해 증명했다. 좋은 근사 알고리즘을 찾기 위해 변수를 꼭짓점으로 취하고 두 변수가 상호 배타적이지 않다면 변수 사이에 변을 추가하면서 최적 묶음 문제를 그래프 색칠 문제로 먼저 바꾸고 그래프 색칠에서 묶음을 만드는, 상당히 괜찮은 결과(일정 근사 비율과 함께)를 만들어내는 탐욕 알고리즘을 사용했다. 더구나 100% 상호 배타적인 건 아니지만 0이 아닌 값을 거의 동시에 갖지 않는 변수들이 꽤 많이 있음을 알고 있다. 사용하는 알고리즘이 작은 비율의 충돌을 허용한다면 더 적게 변수를 묶을 수 있고 계산 효율성을 더욱 증대시킬 수 있다. 간단히 계산해보면 변수 값을 작은 비율로 무작위 오염시킬 때 기껏해야 \(\mathcal{O}([(1 - \gamma)n]^{-2/3})\)정도 훈련 정확도에 영향을 미친다(보충 자료의 명제 2.1 참조). 여기서 \(\gamma\)는 각 묶음에서의 최대 충돌 비율이다. 따라서 상대적으로 작은 \(\gamma\)를 선택하면 정확도와 효율성 사이 균형을 잘 잡을 수 있다.
위 논의를 바탕으로 배타적 변수 묶음을 위한 알고리즘(알고리즘 3에 나온)을 설계했다. 먼저 변마다 가중치가 있는 그래프를 구성한다. 이 가중치는 변수 간 총 충돌 횟수에 해당한다. 그다음 그래프 내 꼭짓점 차수에 따라 내림차순으로 변수를 정렬한다. 마지막으로 정렬시킨 목록의 각 변수를 확인하면서 작은 충돌(\(\gamma\)로 제어함)이 있는 기존 묶음에 할당하거나 새로운 묶음을 만든다. 알고리즘 3의 시간 복잡도는 \(O(\# feature^2)\)이며 훈련 전 딱 한 번만 처리한다. 이 정도 복잡도는 변수 개수가 너무 많지 않다면 받아들일 만하다. 그러나 변수가 수백만 개라면 여전히 수행하기 어려울 수 있다. 효율성을 더욱 높이기 위해 그래프를 만들지 않는, 보다 효율적인 정렬 전략을 제안한다. 즉, 0이 아닌 값이 많을수록 충돌 확률이 높아지므로 0이 아닌 값 개수로 정렬한다. 알고리즘 3의 정렬 전략만 바꾼 관계로 새 알고리즘의 세부 사항은 중복을 피하기 위해 생략했다.
알고리즘 3: 탐욕적 묶음
입력: \(F\): 변수, \(K\): 최대 충돌 횟수
그래프 \(G\) 생성
searchOrder \(\leftarrow G\).sortByDegree()
\(bundles \leftarrow \{ \} \), bundlesConflict \(\leftarrow \{ \} \)
for i in searchOrder do
\(\qquad\) needNew \(\leftarrow\) True
\(\qquad\) for j \(= 1\) to len(\(bundles\)) do
\(\qquad\qquad\) cnt \(\leftarrow\) ConflictCnt(\(bundles\)[j], \(F\)[i])
\(\qquad\qquad\) if cnt \(+\) bundlesConflict[i] \(\le K\) then
\(\qquad\qquad\qquad\) bundles[j].add(\(F\)[i]), needNew \(\leftarrow\) False
\(\qquad\qquad\qquad\) break
\(\qquad\qquad\) if needNew then
\(\qquad\qquad\qquad\) 새 묶음으로써 \(F\)[i]를 \(bundles\)에 추가함
출력: \(bundles\)
두 번째 문제로 해당 묶음의 훈련 복잡도를 줄이기 위해 같이 묶인 변수를 병합하는 적당한 방법이 필요하다. 원래의 변수 값이 변수 묶음에서 식별 가능한지 확인하는 게 관건이다. 히스토그램 기반 알고리즘은 변수의 연속적인 값 대신 개별 구간을 저장하기 때문에 배타적 변수를 각기 다른 구간에 두어 변수 묶음을 구성할 수 있다. 이는 변수의 원래 값에 오프셋을 더하여 수행할 수 있다. 예를 들어 변수 묶음에 변수 두 개가 속한다고 가정하자. 원래의 변수 A는 [0, 10] 값을 취하고 변수 B는 [0, 20] 값을 취한다. 그렇다면 변수 B 값에 오프셋 10을 더하여 가공한 변수가 [10, 30]에서 값을 취하게 한다. 그다음, 변수 A와 B를 병합하고 [0, 30] 범위의 변수 묶음을 사용하여 원래의 변수 A와 B를 대체하는 것이 안전하다. 상세한 알고리즘은 알고리즘 4에 표시했다.
알고리즘 4: 배타적 변수 병합
입력: \(numData\): 데이터 개수, \(F\): 배타적 변수의 한 묶음
\(binRanges \leftarrow \{0 \} \), \(totalBin \leftarrow 0 \)
for f in \(F\) do
\(\qquad\) \(totalBin\) \(+=\) f.numBin
\(\qquad\) \(binRanges\).append(\(totalBin\))
\(newBin \leftarrow\) new Bin(\(numData\))
for i \(= 1\) to \(numData\) do
\(\qquad\) \(newBin\)[i] \(\leftarrow 0\)
\(\qquad\qquad\) for j \(= 1\) to len(\(F\)) do
\(\qquad\qquad\qquad\) if \(F\)[j].bin[i] \(\ne 0\) then
\(\qquad\qquad\qquad\qquad\) \(newBin\)[i] \(\leftarrow\) \(F\)[j].bin[i] \( + binRanges\)[j]
출력: \(newBin, binRanges\)
EFB 알고리즘은 많은 배타적 변수를 훨씬 적은 밀집 변수로 묶어 줄 수 있기 때문에 변수의 0 값에 대한 불필요한 계산을 효과적으로 피할 수 있다. 사실 각 변수에 대한 테이블을 사용하여 0이 아닌 값의 데이터를 기록함으로써 변수 0 값을 무시하게 기본 히스토그램 기반 알고리즘을 최적화시킬 수 있다. 해당 테이블의 데이터를 훑는 경우 변수 히스토그램 생성 비용은 \(O(\#data)\)에서 \(O(\#non\_zero\_data)\)로 바뀐다. 그러나 트리를 전반적으로 성장시키는 와중에 변수 별 테이블을 이런 식으로 유지, 관리하기 위해서는 메모리와 계산 비용이 추가로 필요하다. LightGBM은 해당 최적화 방법을 기본 기능으로 구현했다. 본 최적화는 묶음이 희소한 경우에도 사용할 수 있으므로 EFB와 충돌하지 않는다.
5. 실험
이 장에서는 제안한 LightGBM 알고리즘에 대해 실험한 결과를 보고하겠다. 공개되어 이용 가능한 데이터셋 5가지를 사용했다. 그중 Microsoft Learning to Rank(LETOR) 데이터셋은 웹 검색 질의 30,000개를 포함하고 있다. 이 데이터셋에 사용된 변수 대부분은 수치형 밀집 변수이다. Allstate Insurance Claim과 Flight Delay 데이터셋은 원-핫 코딩된 변수를 많이 포함하고 있다. 마지막 두 데이터셋은 KDD CUP 2010과 KDD CUP 2012에서 가져온 것이다. NTU가 우승 해법에서 사용한 변수(밀집 및 희소 변수 모두 포함한)를 직접 사용할 것이다. 이 두 데이터셋은 매우 크다. 이러한 데이터셋은 크기가 크고 밀집 및 희소 변수 모두 포함하므로 현실 속 분석 과제를 대신할 수 있다. 따라서 알고리즘을 철저히 시험해보기 위해 이것들을 이용하였다.
E5-2670 v3 CPU 2개(총 24 코어)와 256GB 메모리의 리눅스 서버가 실험 환경이다. 모든 실험은 멀티스레딩으로 진행했고 스레드 수는 16개로 고정했다.

표 1: 실험에서 사용한 데이터셋들
5.1 전반적인 비교
이 절은 전반적인 비교를 제시한다. GOSS와 EFB를 적용 안 한 XGBoost 및 LightGBM(lgb_baselline)을 기준선으로 이용했다. XGBoost는 xgb_exa(사전 정렬 알고리즘)와 xgb_his(히스토그램 기반 알고리즘) 두 가지 버전 모두 사용했다. xgb_his, lgb_baseline과 LightGBM의 경우 리프 별 트리 성장 전략을 사용했다. xgb_exa의 경우 층별 성장 전략만 지원하므로 xgb_exa의 매개 변수를 조정하여 다른 방법과 유사하게 트리를 성장시켰다.
또한 모든 데이터셋의 매개 변수를 조정하여 속도와 정확도 간의 균형을 개선했다. Allstate, KDD10과 KDD12에 대해 \(a = 0.05, b = 0.05\)로 설정했고 Flight Delay와 LETOR는 \(a = 0.1, b = 0.1\)로 설정했다. EFB는 \(γ = 0\)으로 설정했다. 모든 알고리즘을 정해둔 반복 횟수만큼 실행했고 반복 상의 최고 점수를 정확도 결과로 삼았다.9
훈련 시간과 시험 정확도를 표 2와 표 3에 각각 요약해두었다. 결과를 통해 LightGBM이 기준선의 정확도를 거의 동일하게 가져가면서 속도는 가장 빠름을 알 수 있다. xgb_exa는 사전 정렬 알고리즘 기반이며 히스토그램 기반 알고리즘과 비교했을 때 매우 느리다. lgb_baseline와 비교했을 때 LightGBM은 Allstate, Flight Delay, LETOR, KDD10, KDD12 데이터셋에 대해 속도가 각각 21배, 6배, 1.6배, 14배, 13배 향상했다. xgb_his는 메모리를 많이 사용하기 때문에 KDD10와 KDD12 데이터셋의 경우 메모리 부족으로 실행이 실패했다. 나머지 데이터셋 모두 LightGBM이 가장 빠르며 Allstate 데이터셋에서는 속도가 최대 9배 향상했다. 모든 알고리즘이 비슷한 반복 횟수를 거친 후 수렴하므로 반복 당 훈련 시간 기준으로 속도 증가를 계산했다. 전반적인 훈련 과정을 설명하기 위해 Flight Delay와 LETOR의 실제 시간 기준 훈련 곡선을 그림 1과 그림 2에 각각 그려 넣었다. 나머지 데이터셋의 훈련 곡선은 지면을 절약하기 위해 보충 자료에 넣었다.
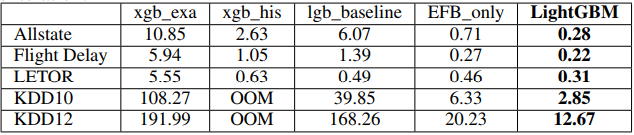
표 2: 전체 훈련 시간 비용 비교. LightGBM은 GOSS와 EFB을 적용한 lgb_baseline이다. EFB_only는 EFB만 적용한 lgb_baseline이다. 표의 값은 반복 학습 1회에 소요되는 평균 시간 비용(초)이다.

표 3: 시험 데이터셋에 대한 전반적인 정확도 비교. 분류 작업에는 AUC를 사용했고 순위 작업에는 NDCG@10을 사용했다. SGB는 확률적 그래디언트 부스팅을 적용한 lgb_baseline이며 표본 추출 비율은 LightGBM과 동일하다.
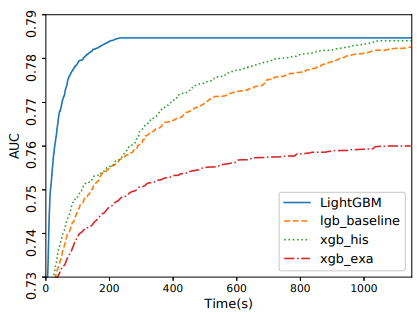
그림 1: Flight Delay에서의 시간-AUC 곡선
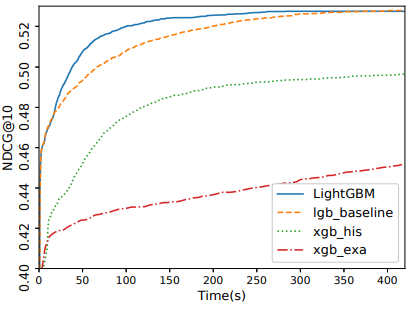
그림 2: LETOR에서의 시간-NDCG 곡선
모든 데이터셋에서 LightGBM은 기준선의 시험 정확도를 거의 동일하게 달성해냈다. 이는 GOSS와 EFB가 정확도를 저하시키지 않으면서 속도만 상당히 향상했음을 의미한다. 즉, 3.2절과 4장의 이론적 분석 내용과 일치한다.
LightGBM은 각 데이터셋마다 아주 다른 속도 향상 비율을 달성했다. 전반적인 속도 향상은 GOSS와 EFB 결합에서 비롯한다. 다음 절에서 GOSS와 EFB 효과를 개별 논의하고 각각의 기여도를 분석할 것이다.
5.2 GOSS에 대한 분석
첫째, GOSS가 얼마나 속도가 향상하는지 연구했다. 표 2의 LightGBM과 EFB_only(GOSS를 적용 안 한 LightGBM)를 비교하면 GOSS가 10% - 20% 데이터를 사용해 속도가 거의 2배 향상함을 알 수 있다. GOSS는 표본 추출한 데이터만 사용해서 트리를 학습한다. 그러나 예측을 수행하고 기울기 계산하는 것 같이 전체 데이터셋에 대한 일부 계산은 유지한다. 따라서 전반적인 속도 향상은 데이터 표본 추출 비율과 선형적 상관관계는 없다는 걸 알 수 있다. 그러나 GOSS로 인한 속도 향상은 여전히 매우 중요하며 해당 기술은 다른 데이터셋에 보편적으로 적용된다.
둘째, 확률적 그래디언트 부스팅(SGB)과 비교하여 GOSS의 정확도를 평가했다. 일반성을 잃지 않고 LETOR 데이터셋을 시험에 사용했다. GOSS는 서로 다른 \(a\)와 \(b\)를 선택하여 표본 추출 비율을 조정했고 SGB는 동일한 전체 표본 추출 비율을 사용했다. 조기 종료를 이용하여 수렴할 때까지 해당 설정을 돌렸다. 결과는 표 4에 나와있다. 동일한 표본 추출 비율을 사용하는 경우 GOSS 정확도가 SGB보다 항상 우수함을 알 수 있다. 이 결과는 3.2절 논의와 일치한다. 모든 실험이 확률적 표본 추출보다 GOSS가 더 효과적인 표본 추출 방법임을 입증한다.

표 4: 다양한 표본 추출 비율에서의 LETOR 데이터셋에 대한 GOSS와 SGB 정확도 비교. 조기 종료와 함께 다수의 반복을 통해 모든 실험이 수렴 지점에 도달하도록 했다. 다른 설정에 관한 표준 편차는 작은 편이다. GOSS의 \(a\)와 \(b\) 설정은 보충 자료에서 찾을 수 있다.
5.3 EFB에 대한 분석
lgb_baseline과 EFB_only를 비교하여 속도 향상에 대한 EFB 기여도를 확인했다. 결과는 표 2에 나와있다. 여기서 묶음 찾기 절차 중(예: \(\gamma = 0\)) 충돌을 허용하지 않았다.10 대규모 데이터셋에서 EFB가 속도 향상에 상당히 도움이 됨을 알 수 있다.
lgb_baseline가 희소 변수에 최적화되어 있음에도 EFB는 여전히 큰 요소로 작용하여 훈련 속도를 높일 수 있었다. 이는 EFB가 많은 희소 변수(원-핫 코딩 변수와 암시적으로 배타적인 변수 모두)를 훨씬 적은 변수로 병합하기 때문이다. 기본적인 희소 변수 최적화가 묶음 절차에 포함된다. 그러나 EFB의 경우 트리 학습 절차 중 변수 별 0이 아닌 데이터 테이블을 유지, 관리하는 데 추가 비용이 들지 않는다. 또한 이전에 격리시킨 많은 변수가 묶음으로 함께 제공되므로 공간적 지역성을 높이고 캐시 적중률이 크게 향상할 수 있다. 따라서 전반적인 효율성은 극적으로 향상한다. 위 분석을 통해 EFB는 히스토그램 기반 알고리즘에서 희소 변수를 활용하는 데 매우 효과적인 알고리즘이며 GBDT 훈련 절차 속도를 크게 높임을 알 수 있다.
6. 결론
본 논문에서는 LightGBM이라는 새로운 GBDT 알고리즘을 제안했다. 이 알고리즘은 데이터 개체 다수와 변수 다수를 처리하는 두 가지 새로운 기술, 즉 기울기 기반 단측 표본추출과 배타적 변수 묶음을 포함한다. 이 두 가지 기법에 대한 이론적 분석과 실험적 연구 모두 수행했다. 실험 결과는 이론과 일치하며 GOSS와 EFB 도움으로 LightGBM이 계산 속도와 메모리 소비면에서 XGBoost 및 SGB보다 훨씬 뛰어난 성능을 보여준다. 향후 진행할 작업은 기울기 기반 단측 표본 추출에서 \(a\)와 \(b\)의 최적 선택을 연구하고 희소 혹은 그렇지 않은 변수 다수를 처리하기 위해 배타적 변수 묶음 성능이 지속적으로 향상하는 일이다.
-
본 논문에서 기울기 크고 작음의 기준은 절댓값이다. ↩
-
코드는 Github에서 구할 수 있다. https://github.com/Microsoft/LightGBM ↩
-
지면의 제약으로 인해 높은 수준의 의사 코드를 사용했다. 자세한 내용은 오픈 소스 코드에서 찾을 수 있다. ↩
-
GPU 또는 병렬 훈련을 통해 GBDT 훈련을 가속화시키는 몇 가지 다른 작업물이 있다. 그러나 이 논문의 범위를 벗어난다. ↩
-
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22Nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 785–794. ACM, 2016. ↩
-
Jerome Friedman, Trevor Hastie, Robert Tibshirani, et al. Additive logistic regression: a statistical view of boosting (with discussion and a rejoinder by the authors). The annals of statistics, 28(2):337–407, 2000. ↩
-
Charles Dubout and François Fleuret. Boosting with maximum adaptive sampling. In Advances in Neural Information Processing Systems, pages 1332–1340, 2011. ↩
-
다음 분석은 임의의 노드에 적용된다. 단순화시키고 혼동을 피하기 위해 모든 표기법에서 하위 색인 \(O\)를 생략했다. ↩
-
지면의 제약으로 인해 매개 변수 설정 세부 사항을 보충 자료에 남겨두었다. ↩
-
보충 자료에 \(\gamma\) 조정에 관한 상세 연구가 있다. ↩
Subscribe via RSS