에어비앤비에서 기계학습 이용해서 숙소 가치를 예측하는 방법
by Robert Chang
Robert Chang의 Using Machine Learning to Predict Value of Homes on Airbnb을 번역했습니다.
서론
Airbnb 서비스에서 데이터 제품은 늘 중요한 부분을 차지한다. 그러나 데이터 제품을 만드는데 막대한 비용이 들어간다는 사실을 점차 깨닫게 되었다. 예를 들어 개인화 검색 순위로 게스트는 숙소를 더 쉽게 찾을 수 있고 스마트 가격 정책으로 호스트는 수요와 공급 여건에 따라 더 경쟁력 있게 가격을 책정할 수 있다. 그러나 이런 프로젝트를 위해 데이터 과학 및 엔지니어링 측면으로 수많은 시간과 노력이 투입됐다.
최근에 Airbnb 기계학습 인프라가 발전하면서 새로운 기계 학습 모형을 제품화하여 배포하는 비용이 크게 절감되었다. 예를 들어 ML Infra팀은 고품질의, 검증되고, 재사용 가능한 변수를 사용자가 모형에 활용할 수 있게끔 범용 변수 저장소를 구축했다. 데이터 과학자는 여러 AutoML 도구를 작업흐름에 통합시켜 모형 선택과 성능 벤치마킹 작업을 빠르게 만들었다. 또한 ML Infra팀은 Jupyter 노트북을 Airflow 파이프라인으로 변환시키는 새로운 프레임워크를 만들었다.
이 문서에서는 LTV 모델링, 즉, Airbnb에 올라온 숙소 가치를 예측하는 특정 활용 사례를 통해 이런 도구들이 어떻게 함께 작동하며 모델링 절차를 어떻게 빠르게 만들고 전체적인 개발 비용을 어떻게 낮추는지 설명하겠다.
LTV란 무엇인가?
전자 상거래와 마켓플레이스 기업에서 인기 있는 개념인 고객 생애 가치(LTV)는 사용자가 고정 시간 동안 발생시키는 추정 가치를 뜻하며 대개 달러 단위로 측정된다.
Spotify와 Netflix 등 전자 상거래 회사는 LTV를 구독료 설정 등 가격 결정에 자주 사용한다. Airbnb 같은 마켓플레이스 기업에서 사용자 LTV를 알면 다양한 마케팅 채널에 예산을 효율적으로 할당하고 키워드 기반 온라인 마케팅에 대해 보다 정확한 입찰 가격을 제시하고 숙소 세그먼트를 보다 잘 만들 수 있다.
과거 데이터를 사용해서 기존 숙소 과거 가치를 계산할 수 있지만 새 숙소의 LTV를 예측하기 위해 기계 학습을 적용해보았다.
LTV 모델링을 위한 기계학습 작업 흐름
데이터 과학자는 일반적으로 피쳐 엔지니어링, 프로토타이핑 및 모형 선택 같은 기계학습 관련 작업에 익숙하다. 그러나 모형 프로토타입을 제품화하려면 종종 데이터 과학자가 익숙하지 않은 데이터 엔지니어링 기술이 필요하다.
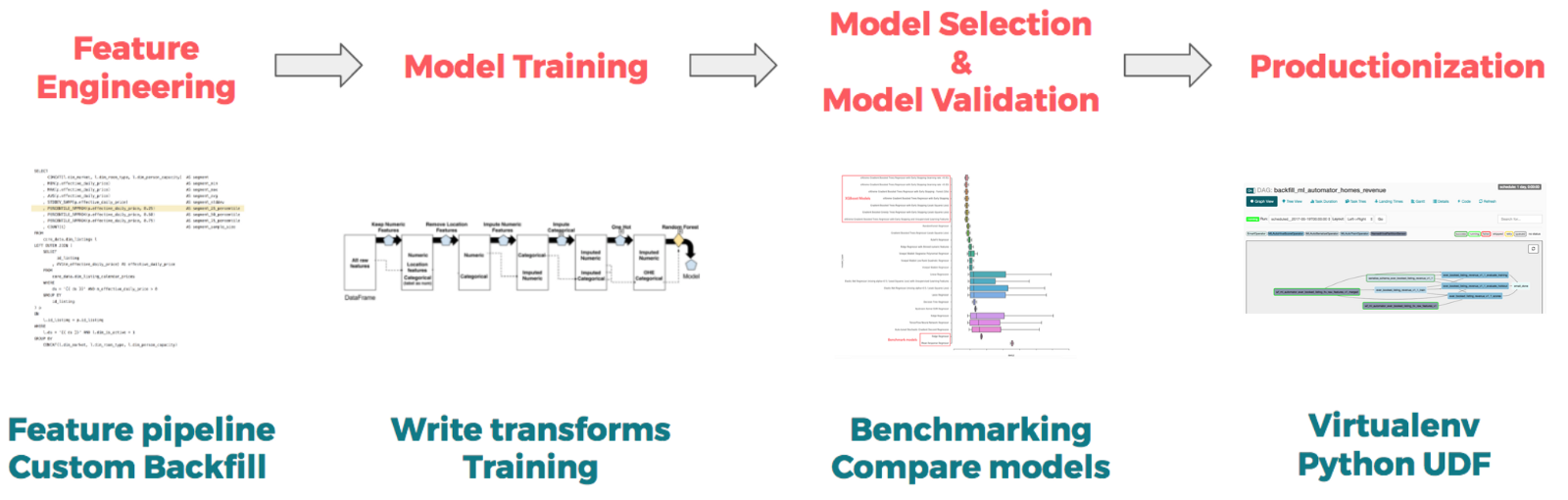
다행히 Airbnb에는 기계학습 모형의 제품화 뒤편으로 엔지니어링 작업을 일반화시켜주는 기계 학습 도구가 있다. 사실 이런 놀라운 도구가 없었다면 모형을 제품화시키기 어려웠을 거다. 게시물 나머지 부분에서 각 과제를 해결하는 데 사용한 도구를 함께 제시할 것이다. 총 네 가지 주제를 다룬다.
-
피쳐 엔지니어링: 관계있는 변수를 정의
-
프로토타이핑과 훈련: 모형 프로토타입을 훈련
-
모형 선택과 평가: 모형을 선택하고 조정
-
제품화: 선택한 모형 프로토타입을 제품으로 바꿈
피쳐 엔지니어링
사용한 도구: Airbnb 사내 변수 저장소 — Zipline
지도 학습 프로젝트 첫 번째 단계 중 하나는 선택한 결과 변수와 상관성이 있을 만한 관련 변수를 정의하는 일이다. 이 과정을 피쳐 엔지니어링이라고 한다. 예를 들어 LTV를 예측할 때 다음 180 달력일 중 숙소를 이용할 수 있는 일자 비율 또는 동일한 시장에서 비교 가능한 숙소 대비 현 숙소의 가격을 계산해볼 수 있다.
Airbnb에서 피쳐 엔지니어링은 종종 Hive 쿼리를 작성하여 처음부터 변수 만드는 걸 의미한다. 특정 도메인 지식과 비즈니스 로직이 필요하기 때문에 이 작업은 지루하고 시간이 오래 걸린다. 따라서 변수 파이프라인은 쉽게 공유되거나 재사용할 수 없는 경우가 많다. 이 작업을 보다 확장 가능하게 하기 위해 우리는 호스트, 게스트, 숙소 또는 시장 수준 같이 다양하게 세분화된 수준에서 변수를 제공하는 훈련용 변수 저장소 Zipline을 개발했다.
이 사내 도구의 크라우드 소스적 특징으로 인해 데이터 과학자는 다른 사람들이 과거 프로젝트에서 준비했던 고품질의 검증된 변수를 다양하게 사용할 수 있다. 원하는 변수를 사용할 수 없는 경우 사용자는 다음과 같은 변수 구성 파일을 이용하여 자신만의 변수를 만들 수 있다.
source: {
type: hive
query:"""
SELECT
id_listing as listing
, dim_city as city
, dim_country as country
, dim_is_active as is_active
, CONCAT(ds, ' 23:59:59.999') as ts
FROM
core_data.dim_listings
WHERE
ds BETWEEN '' AND ''
"""
dependencies: [core_data.dim_listings]
is_snapshot: true
start_date: 2010-01-01
}
features: {
city: "숙소가 위치한 도시."
country: "숙소가 위치한 국가."
is_active: "날짜 파티션에 관한 숙소 활성화 여부."
}
훈련 데이터 구성에 다수의 변수가 필요한 경우 Zipline은 지능적 키 조인을 자동으로 수행하고 뒤편으로 훈련 데이터를 채워 넣는다. 숙소 LTV 모형을 위해 기존 Zipline 변수를 사용했고 나만의 변수를 일부 추가했다. 결론적으로 모형에 아래 변수를 포함해 150개 이상의 변수가 사용되었다.
-
장소: 국가, 시장, 이웃과 다양한 지리학적 변수
-
가격: 야간 요금, 청소 비용, 유사한 숙소 대비 가격 점수
-
이용 가능성: 숙박 가능한 총 일수, 직접 예약을 막아놨던 일수 백분율
-
예약 가능성: 예약 횟수 또는 지난 X일간 예약되었던 날 수
-
품질: 리뷰 점수, 리뷰 개수와 어메니티
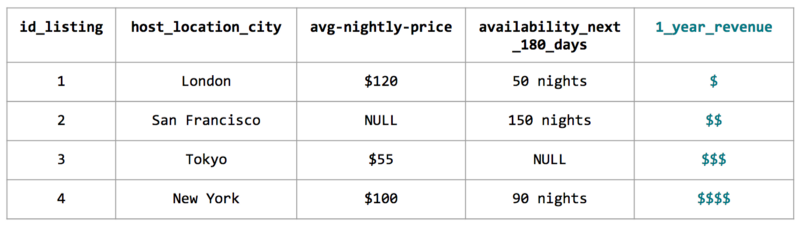
예측 변수와 결과 변수가 정의되면 과거 데이터로부터 학습하게끔 모형 훈련을 시작해볼 수 있다.
프로토타이핑과 훈련
사용한 도구: Python 기계학습 라이브러리 — scikit-learn
위 훈련 데이터셋 예제처럼 모형 적합시키기 전에 데이터 처리를 종종 해줘야 한다.
-
결측 값 대체: 데이터 결측이 있는지, 있다면 데이터 결측이 무작위로 발생했는지 확인해야 한다. 무작위로 발생하지 않았다면 어떤 연유로 발생했는지 조사하고 근본 원인을 이해해야 한다. 무작위로 발생했다면 결측 값 대체를 수행한다.
-
범주형 변수 인코딩: 문자열 값에 모형을 적합시킬 수 없기 때문에 모형은 종종 범주를 그대로 사용할 수 없다. 범주 수가 적으면 one-hot 인코딩 사용을 고려할 수 있다. 그러나 차원 수가 높으면 서수 인코딩을 사용하여 각 범주의 빈도 수로 인코딩하는 게 좋다.
이 단계에서는 사용할 변수 조합 중 무엇이 가장 적합한지 모르기 때문에 신속한 반복을 가능케 하는 코드를 작성하는 것이 중요하다. Scikit-Learn과 Spark 같은 오픈 소스 도구에서 일반적으로 사용할 수 있는 파이프라인 구조는 프로토타이핑을 위한 매우 편리한 도구이다. 파이프라인을 사용하여 데이터 과학자는 변수 변환 방법과 훈련시킬 모형을 기술하는 높은 수준의 청사진을 정할 수 있다. 좀 더 구체화하기 위해 LTV 모형 파이프라인 코드 스니펫을 아래 제시한다.
transforms = []
transforms.append(
('select_binary', ColumnSelector(features=binary))
)
transforms.append(
('numeric', ExtendedPipeline([
('select', ColumnSelector(features=numeric)),
('impute', Imputer(missing_values='NaN', strategy='mean', axis=0)),
]))
)
for field in categorical:
transforms.append(
(field, ExtendedPipeline([
('select', ColumnSelector(features=[field])),
('encode', OrdinalEncoder(min_support=10))
])
)
)
features = FeatureUnion(transforms)
높은 수준에서 파이프라인을 사용하여 다양한 유형의 변수에 대해 유형이 불리언, 범주형 또는 수치형인지에 따라 데이터 변환을 지정한다. FeatureUnion은 변수를 칼럼 단위로 결합하여 최종 훈련 데이터셋을 생성한다.
프로토타입을 파이프라인을 통해 작성하면 데이터 변환기를 사용하여 지루한 데이터 변환을 추상화시킬 수 있다는 이점이 있다. 총괄하자면 이러한 변환을 통해 훈련 및 평가 과정에서 일관성 있게 데이터가 변환되므로 프로토타입 제품화할 때 데이터 변환에 관한 보편적인 문제를 해결할 수 있다.
또한 파이프라인은 모형 적합과 데이터 변환을 분리한다. 위 코드에 나와있지 않지만 데이터 과학자는 모형 적합 추정기를 마지막에 정하여 추가할 수 있다. 데이터 과학자는 표본 외 오차를 개선하기 위해 여러 추정 기를 탐색하며 최적 모형을 선택하는 모형 선택 과정을 수행할 수 있다.
모형 선택 수행
사용한 도구: 다양한 AutoML 프레임워크
이전 구문에서 언급했듯이 우리는 어떤 모형 후보가 제품화에 가장 적합한지 결정해야 한다. 이러한 결정을 내리기 위해서는 모형 해석 가능성과 모형 복잡도 간의 절충점을 고려해야 한다. 예를 들어, 희소 선형 모형은 해석하기 쉽지만 데이터를 일반화하기에는 복잡도가 충분하지 않다. 트리 기반 모형은 비선형 패턴을 잡아낼 만큼 충분히 유연하지만 해석하기가 어렵다. 이를 편의 - 분산 트레이드오프이라고 한다.
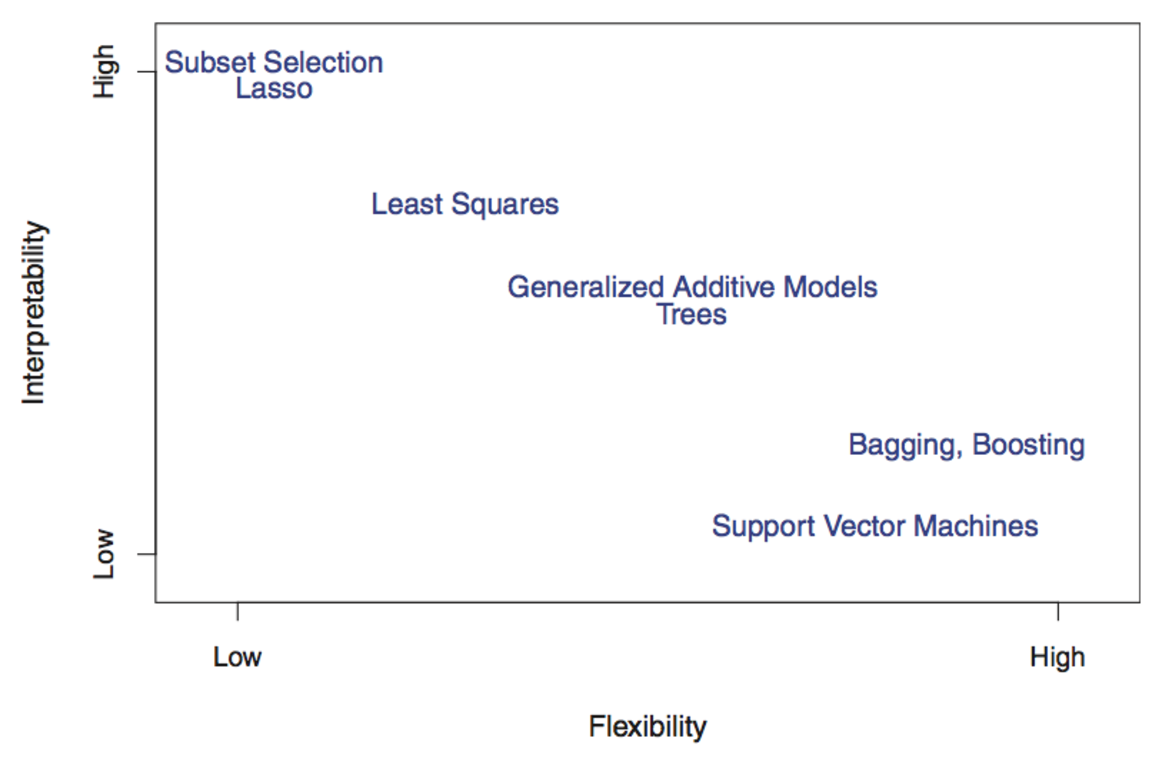
보험 또는 신용 심사와 같은 적용 사례는 모형이 의도적으로 특정 고객을 차별해선 안되기 때문에 모형이 해석 가능해야 한다. 그러나 이미지 분류 같은 적용 사례는 해석 가능한 모형보다 성능이 뛰어난 분류기를 갖는 게 훨씬 더 중요하다.
모형 선택에 많은 시간이 소요될 수 있으므로 다양한 AutoML 도구를 사용하여 수행 속도를 향상하는 방법을 실험했다. 다양한 모형을 탐색하여 어떤 유형의 모형 성능이 일반적으로 우수한지 조사했다. 예를 들어, eXtreme gradient boosted trees(XGBoost)가 평균 응답 모형, 능선 회귀 모형 및 단일 의사 결정 트리와 같은 벤치마크 모형보다 월등히 뛰어나다는 점을 알게 되었다.
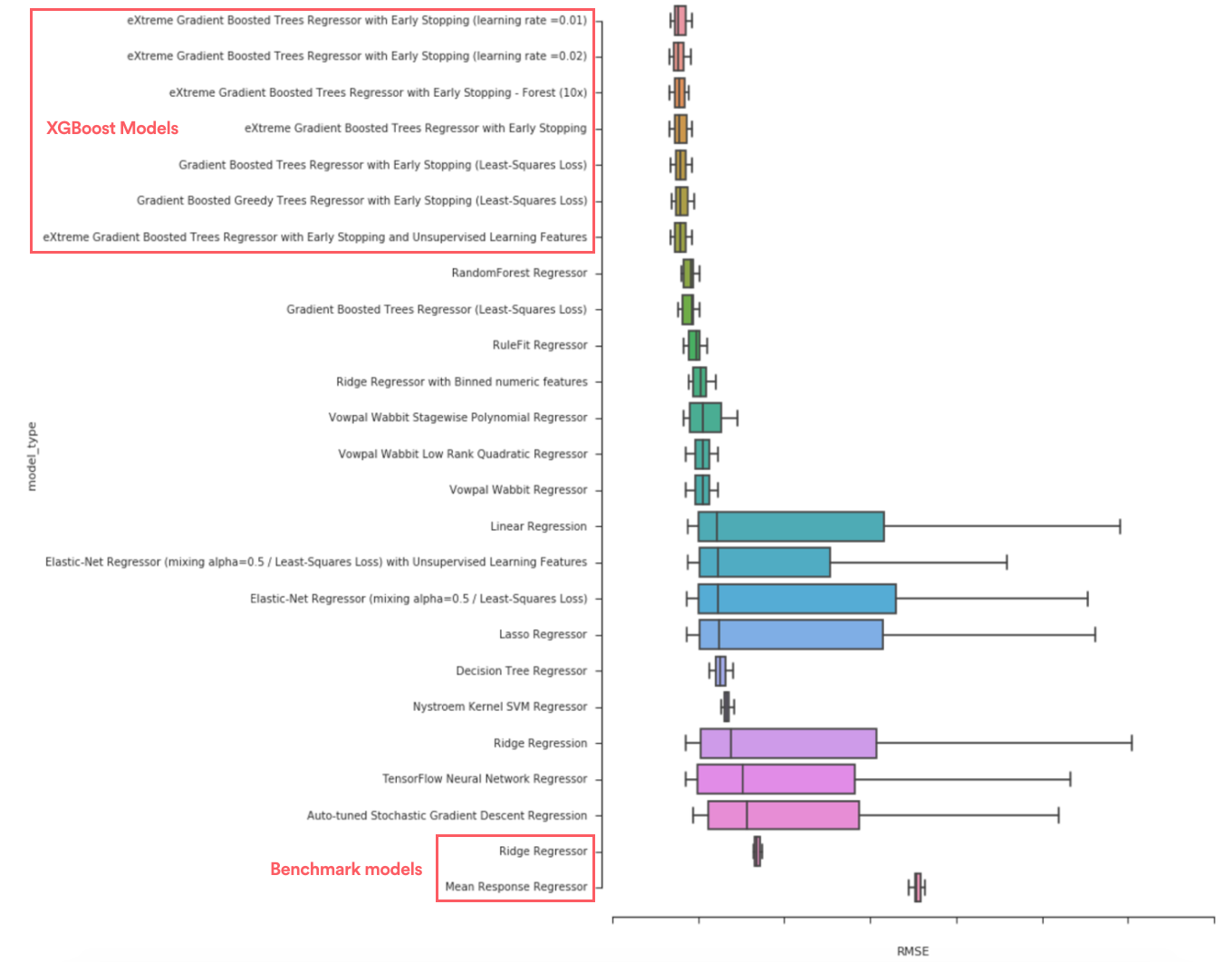
주된 목표가 숙소 가치 예측이기 때문에 해석 가능성보단 유연성을 고려하여 XGBoost를 최종 모형으로 이견 없이 선택했다.
모형 프로토타입을 제품화시키기
사용한 도구: Airbnb의 노트북 변환 프레임워크 — ML Automator
이전에 언급했듯이 제품화 파이프라인을 구축하는 건 로컬 랩탑에서 프로토타입을 만드는 것과 상당히 다르다. 예를 들어 재훈련을 어떻게 주기적으로 수행할 수 있을까? 대용량 표본을 어떻게 효율적으로 스코어링 할 수 있을까? 모형 성능 추이를 모니터링하는 파이프라인은 어떻게 구축할 수 있을까?
Airbnb는 Jupyter 노트북을 Airflow 기계 학습 파이프라인으로 자동 변환하는 ML Automator라는 프레임워크를 구축했다. 이 프레임워크는 Python으로 프로토타입을 작성하는데 익숙하지만 제한된 데이터 엔지니어링 경험을 갖고 있는, 자신의 모형을 제품화시키고 싶은 데이터 과학자를 위해 특별히 설계됐다.
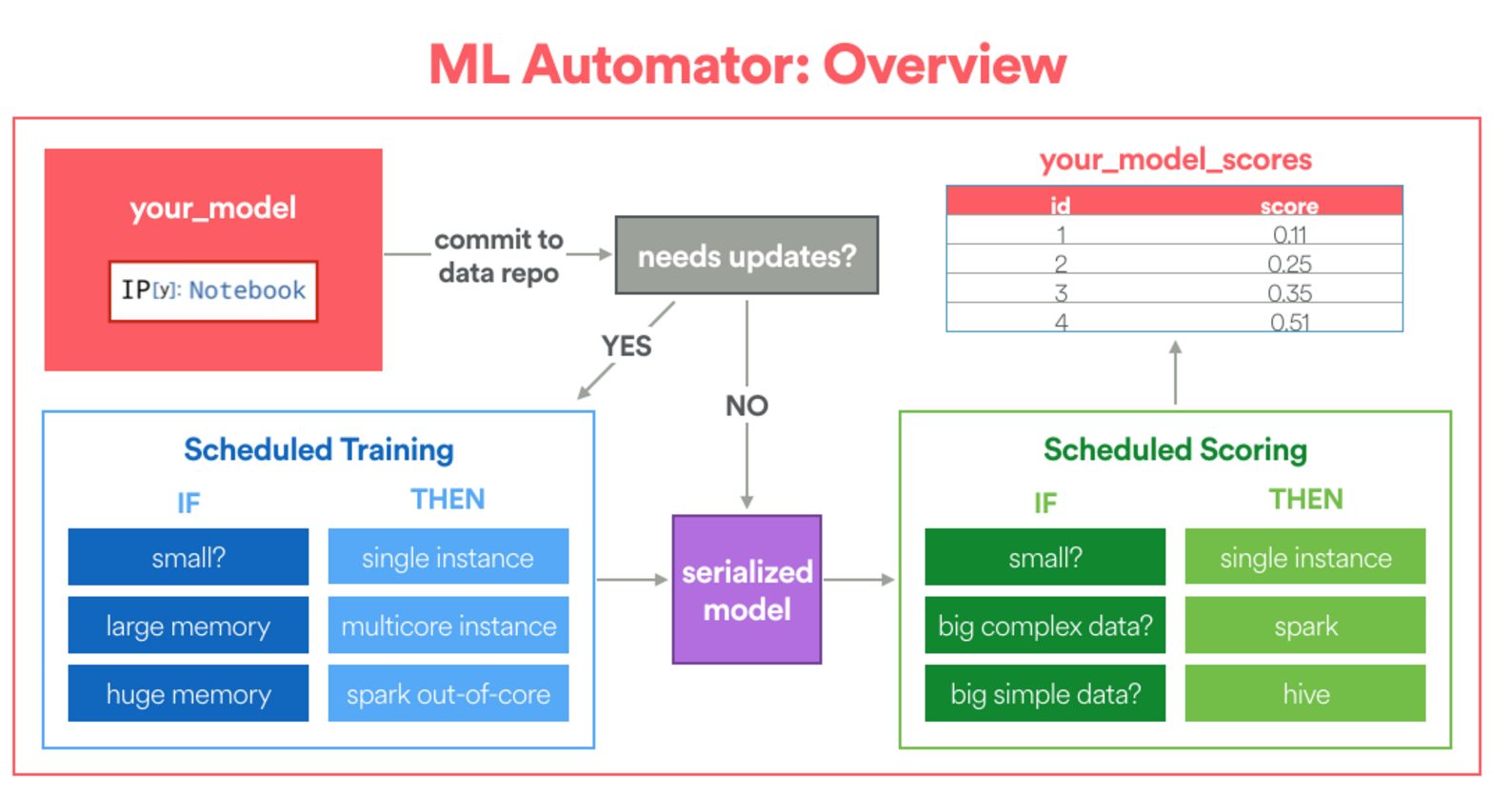
-
첫째, 프레임워크를 사용하기 위해선 사용자가 노트북에 모형 환경설정을 지정해야 한다. 이 모형 환경설정의 목적은 프레임워크에 훈련 테이블의 위치, 훈련을 위해 할당할 계산 자원의 수 그리고 스코어 계산 방법을 알려주는 것이다.
-
또한 데이터 과학자는 특정한 적합 및 변환 함수를 작성해야 한다. 적합 함수는 훈련이 정확하게 수행될 방법을 지정하며 변환 함수는 (필요한 경우) 분산 스코어링을 위해 Python UDF로 감싸 진다.
다음은 LTV 모형에서 적합 함수 및 변환 함수 정의한 방법을 보여주는 코드 스니펫이다. 적합 함수는 프레임워크에 XGBoost 모형으로 훈련되고 이전에 정의한 파이프라인에 따라 데이터 변환이 수행됨을 알려준다.
def fit(X_train, y_train):
import multiprocessing
from ml_helpers.sklearn_extensions import DenseMatrixConverter
from ml_helpers.data import split_records
from xgboost import XGBRegressor
global model
model = {}
n_subset = N_EXAMPLES
X_subset = {k: v[:n_subset] for k, v in X_train.iteritems()}
model['transformations'] = ExtendedPipeline([
('features', features),
('densify', DenseMatrixConverter()),
]).fit(X_subset)
# 병렬로 변환 적용하기
Xt = model['transformations'].transform_parallel(X_train)
# 병렬로 모형 적합시키기
model['regressor'] = XGBRegressor().fit(Xt, y_train)
def transform(X):
# 딕셔너리 반환하기
global model
Xt = model['transformations'].transform(X)
return {'score': model['regressor'].predict(Xt)}
노트북이 병합되면 ML Automator는 훈련된 모형을 Python UDF로 감싸고 아래와 같은 Airflow 파이프라인을 만든다. 데이터 직렬화, 주기적인 재훈련 스케줄링 및 분산 스코어링 같은 데이터 엔지니어링 작업 모두가 일 배치 작업의 일부로 캡슐화된다. 결과적으로 이 프레임워크는 데이터 과학자와 함께 모형을 제품화시키는 전담 데이터 엔지니어가 있는 것처럼 데이터 과학자를 위한 모형 개발 비용을 크게 절감시킨다!
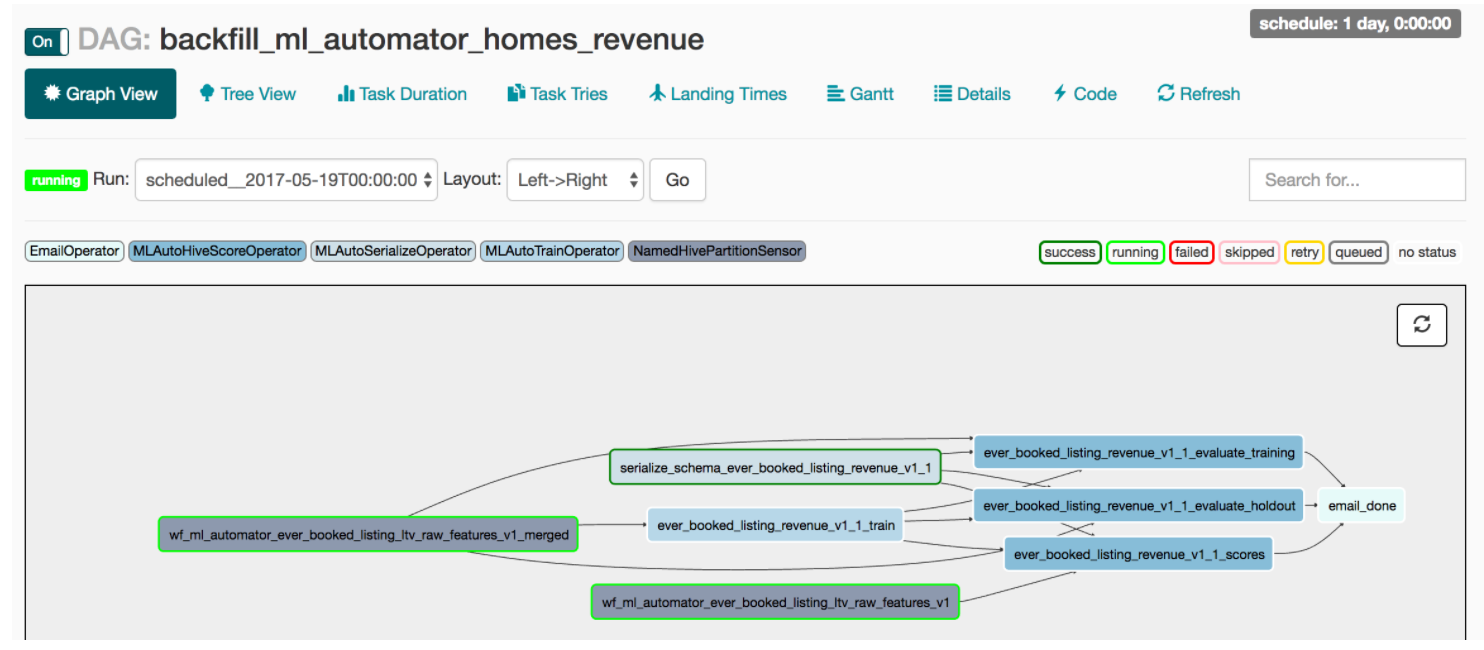
참고: 제품화를 넘어서 모형 성능 추이를 추적하거나 모델링 위해 계산 환경을 탄력적으로 활용하기 같은 다른 주제가 있지만 이 게시물에서 다루진 않을 것이다. 모두 활발하게 개발 중인 분야라는 건 믿어도 좋다.
배운 교훈과 전망
지난 몇 달간 ML Infra는 데이터 과학자와 매우 밀접하게 일했으며 협력을 통해 훌륭한 패턴과 아이디어가 많이 생겨났다. 이렇게 만든 도구가 기계 학습 모형 개발 방법에 대한 새로운 지평을 Airbnb에 열어주리라 믿는다.
-
첫째, 모형 개발 비용이 현저하게 낮다: 피쳐 엔지니어링을 위한 Zipline, 모형 프로토타이핑을 위한 파이프라인, 모형 선택 및 벤치마킹을 위한 AutoML, 그리고 최종적으로 제품화를 위한 ML Automator와 같이 개별 도구의 서로 다른 강점을 결합하여 개발 주기를 대폭 단축시켰다.
-
둘째, 노트북 주도 설계는 진입 장벽을 줄여준다: 프레임워크에 익숙하지 않은 데이터 과학자도 대량 실생활 사례에 즉각 접근할 수 있다. 제품에 사용하는 노트북은 정확하고, 자체 문서화되며, 최신성을 보장한다. 이런 설계는 신규 사용자의 유입을 강력하게 유도한다.
-
결과적으로 팀은 기계학습 제품 아이디어에 더 많은 투자를 할 수 있다: 이 글을 쓰는 시점에 숙소 조사 큐 우선순위 지정하기, 동업 호스트 추가하기, 낮은 품질의 숙소를 자동으로 표시하기 같은 기계학습 제품 아이디어를 유사한 접근 방식을 통해 탐색하는 여러 다른 팀들이 있다.
우리는 이 프레임워크의 미래 그리고 동반한 새로운 패러다임에 매우 열광하고 있다. 프로토타입 구현과 제품화 간의 격차를 줄임으로써 데이터 과학자와 엔지니어는 종단 간 기계학습 프로젝트를 추구하고 제품을 더욱 효과적으로 만들 수 있게 되었다.
Subscribe via RSS