하이브에서의 조인 유형
by Weidong Zhou
Weidong Zhou의 Join Type in Hive: Common Join 외 3편을 번역했습니다.
1. 일반 조인
하이브 쿼리 성능 튜닝에서 신경 써야 할 부분 중 하나는 쿼리 실행 시 이뤄지는 조인 유형이다. 오라클의 조인 유형과 마찬가지로 여러 다른 유형에 따라 실행 시간이 크게 달라질 수 있다. 몇 번의 연재에 걸쳐 하이브의 조인 유형에 대해 논의할 것이다. 조인 유형의 첫 번째는 일반 조인이다.
일반 조인은 하이브의 기본적인 조인 유형으로 셔플 조인, 분산 조인 또는 정렬 병합 조인이라고도 한다. 조인 작업 동안 두 테이블의 모든 행을 조인 키 기반으로 전체 노드에 분산시킨다. 이 과정을 통해 조인 키가 동일한 값들은 동일한 노드에서 작업이 종료된다. 해당 조인 작업은 맵 / 리듀스의 온전한 주기를 갖는다.
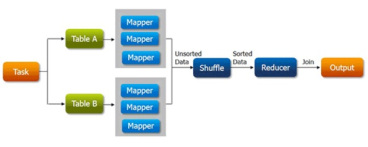
작동 원리
- 맵 단계에서 매퍼는 테이블을 읽고 조인 칼럼 값을 키로 정해 출력한다. 키 - 값 쌍을 중간 파일에 기록한다.
- 셔플 단계에서 이러한 쌍을 정렬하고 병합한다. 동일한 키의 모든 행을 동일한 리듀스 인스턴스로 전송한다.
- 리듀스 단계에서 리듀서는 정렬한 데이터를 가져와 조인을 수행한다.
일반 조인의 장점은 테이블 크기와 상관없이 작동한다는 점이다. 그러나 셔플은 비용이 매우 큰 작업이기에 자원을 많이 잡아먹는다. 데이터에서 소수의 조인 키가 차지하는 비율이 매우 클 경우 해당 리듀서에 과부하가 걸리게 된다. 대다수의 리듀서에서 조인 작업이 완료됐지만 일부 리듀서가 계속 실행되는 식으로 문제의 증상이 나타난다. 쿼리의 총 실행 시간은 실행 시간이 가장 긴 리듀서가 결정한다. 이건 전형적으로 데이터가 편중된 문제이다. 이어지는 내용에서 이러한 데이터 편중 문제를 다루는 특수 조인에 관해 논할 것이다.
조인 유형을 식별하는 방법
EXPLAIN 명령을 사용하면 리듀스 연산자 트리 바로 아래에 조인 연산자가 표시된다.
2. 맵 조인
지금까지 하이브의 기본 조인 유형인 일반 조인에 관하여 이야기를 나눴다. 이제 맵 조인에 대해 논의할 것이다. 자동 맵 조인, 맵 사이드 조인 또는 브로드캐스트 조인이라고도 불린다.
일반 조인 또는 정렬 병합 조인의 가장 큰 문제점 중 하나는 데이터 셔플링에 너무 많은 공을 들인다는 점이다. 하이브 쿼리 속도를 높이기 위해 맵 조인을 사용해볼 수 있다. 조인할 테이블 중 하나가 크기가 작아 메모리에 올릴 수 있으면 맵 조인을 사용해볼 수 있다.
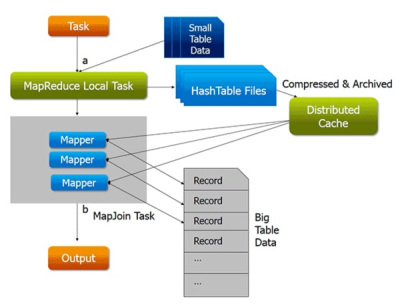
맵 조인의 첫 번째 단계로 본격적인 맵 리듀스 작업을 하기 전에 맵 리듀스 로컬 작업을 수행한다. 이 맵 / 리듀스 작업은 작은 크기의 테이블 데이터를 HDFS에서 읽어와 메모리 내 해시 테이블에 저장하고 다시 해시 테이블을 파일로 내린다. 본격적인 맵 리듀스 조인 작업이 시작되면 해시 테이블 파일은 Hadoop 분산 캐시로 옮겨진다. Hadoop 분산 캐시는 각 매퍼의 로컬 디스크마다 파일을 저장한다. 모든 매퍼는 이 해시 테이블 파일을 메모리에 올린 다음 맵 단계에서 조인을 수행한다. 예를 들어 크기가 큰 테이블 A와 작은 테이블 B를 조인할 때 테이블 A를 위한 모든 매퍼는 테이블 B 전체를 읽어둔다. 맵 리듀스 작업의 맵 단계에서 더 작은 테이블을 메모리에 올린 후 조인을 수행하면 리듀서가 필요하지 않으므로 리듀서 단계를 건너뛴다. 맵 조인은 기본적인 일반 조인보다 빠르게 수행된다.
매개 변수
- 맵 조인의 가장 중요한 매개 변수는 hive.auto.convert.join이다. true로 설정해야 한다.
- 조인할 때 작은 테이블인지 판단하는 기준은 매개 변수 hive.mapjoin.smalltable.filesize에 의해 조절 가능하다. 기본적으로 25MB이다.
- 3개 이상의 테이블을 조인하면 하이브는 모든 테이블의 크기를 작은 것으로 가정하고 3개 이상의 맵 사이드 조인을 생성한다. n-1개 테이블 크기가 기본값인 10MB보다 작은 경우 조인 속도를 더 높이기 위해 세 개 이상의 맵 사이드 조인을 단일 맵 사이드 조인으로 결합할 수 있다. 이를 위해서는 hive.auto.convert.join.noconditionaltask 매개 변수를 true로 설정하고 매개 변수 hive.auto.convert.join.noconditionaltask.size를 지정해야 한다.
제약
전체 외부 조인에 맵 조인을 절대 사용할 수 없다. 오른쪽 테이블 크기가 25MB보다 작으면 왼쪽 외부 조인에 맵 조인을 사용할 수 있다. 오른쪽 외부 조인에 사용할 수 없다.
조인 유형을 식별하는 방법
EXPLAIN 명령을 사용하면 맵 연산자 트리 바로 아래에 맵 조인 연산자가 표시된다.
기타
맵 조인을 사용하는 쿼리로 지정하기 위해 힌트를 이용할 수 있다. 아래 예제에서 더 작은 테이블을 힌트에 썼고 그 결과 테이블 B를 직접 캐시 하도록 했다.
Select /*+ MAPJOIN(b) */ a.key, a.value from a join b on a.key = b.key
예제
hive> set hive.auto.convert.join=true;
hive> set hive.auto.convert.join.noconditionaltask=true;
hive> set hive.auto.convert.join.noconditionaltask.size=20971520
hive> set hive.auto.convert.join.use.nonstaged=true;
hive> set hive.mapjoin.smalltable.filesize = 30000000;
3. 스큐 조인
지금까지 일반 조인과 맵 조인에 대해 설명했다. 이번 절에서는 스큐 조인에 대해 논의할 것이다. 일반 조인에서 했던 이야기를 기억해보자. 일반 조인의 중요한 문제점 중 하나는 데이터가 편중되어 있을 때 조인을 제대로 수행하지 못한다는 점이다. 리듀서 대부분에서 조인 작업을 완료했어도 쿼리는 편중된 키에서 돌아가는, 실행 시간이 가장 긴 리듀서를 기다리게 된다.
스큐 조인은 해당 문제 해결을 목표로 한다. 수행 시간 동안 데이터를 스캔해서 hive.skewjoin.key 매개 변수로 제어하는, 데이터가 굉장히 편중된 키를 감지해낸다. 해당 키를 처리하는 대신 HDFS 디렉터리에 임시로 저장한다. 그다음 후속 맵 리듀스 작업을 통해 편중된 해당 키를 처리한다. 해당 키가 모든 테이블 데이터에 대해 편중되어있지는 않을 것이고 맵 조인 처리가 가능할 것이기에 후속 맵 리듀스 작업(편중된 키의 경우)이 보통은 훨씬 빠르다.
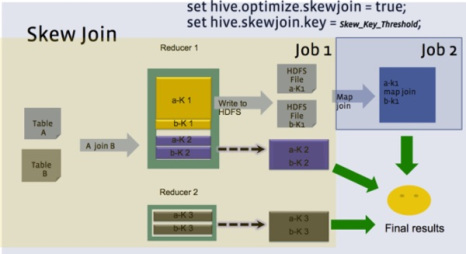
예를 들어 테이블 A와 B를 조인한다고 하자. 테이블 A와 B 모두 조인하는 칼럼에 “mytest” 데이터가 편중되어있다. 테이블 B가 테이블 A보다 편중된 데이터 행 수가 적다면 첫 단계는 B를 스캔하고 “mytest”키가 있는 모든 행을 메모리 내 해시 테이블에 저장하는 일이다. 그런 다음 매퍼 집합을 실행하고 테이블 A를 읽으며 다음을 수행한다.
-
편중된 키 “mytest”의 경우 조인에 B의 해시 버전을 사용한다.
-
그 외 다른 키의 경우 조인을 수행하는 리듀서에 행을 보낸다. 동일한 리듀서가 테이블 B를 탐색한 매퍼에서 행을 가져온다.
스큐 조인 중에 테이블 B를 두 번 스캔함을 알 수 있다. 테이블 A의 편중된 키는 매퍼가 읽고 처리하면서 맵 사이드 조인을 수행한다. 테이블 A의 키가 편중된 행을 리듀서로 전송하지 않는다. 테이블 A의 나머지 키에 대해서는 일반 조인 방식을 사용한다.
스큐 조인을 사용하려면 데이터와 쿼리를 이해해야 한다. 매개 변수 hive.optimize.skewjoin을 true로 설정하라. 매개 변수 hive.skewjoin.key는 선택 사항이고 기본적으로 100000이다.
조인 유형을 식별하는 방법
EXPLAIN 명령을 사용하면 조인 연산자와 리듀스 연산자 트리 바로 아래에 handleSkewJoin: true가 표시된다.
예제
set hive.optimize.skewjoin = true;
set hive.skewjoin.key=500000;
set hive.skewjoin.mapjoin.map.tasks=10000;
set hive.skewjoin.mapjoin.min.split=33554432;
4. 버킷 조인
지금까지 일반 조인, 맵 조인과 스큐 조인에 대해 설명했다. 일반 조인은 기본적인 조인 유형이다. 맵 조인은 조인할 테이블 중 하나가 작아서 메모리 크기에 맞을 때 가장 잘 사용할 수 있다. 스큐 조인은 조인 키 기준으로 데이터가 편중되어있을 때 쿼리 성능이 향상한다. 조인할 양쪽 테이블 크기가 모두 크고 위에서 말한 세 조인 유형 중 어느 한 개도 동작하지 않는다면 어떻게 해야 할까? 만일 그렇다면 버킷 조인을 써볼 차례이다.
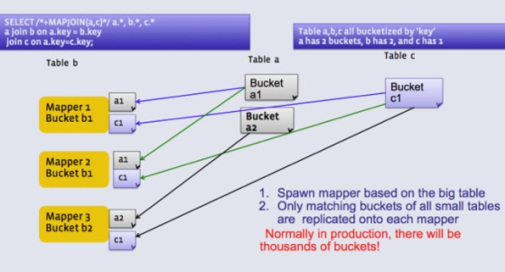
버킷 조인은 공동 배열 조인이라고도 한다. 조인할 모든 테이블의 크기가 크고 테이블 데이터가 조인 키에 대해 고르게 분포한 경우 사용된다. 이 경우 데이터 복사가 필요하지 않다. 맵 사이드 조인이며 조인은 로컬 노드에서 이뤄질 수 있다. 버킷 조인의 또 다른 조건은 한 테이블의 버킷 수가 다른 테이블의 버킷 수와 동일하거나 배수여야 한다는 것이다.
테이블을 생성할 때 조인 칼럼을 이용하여 버킷을 만들고 테이블에 데이터를 삽입하기 전에 버킷이 만들어졌는지 확인하자. 또 데이터를 삽입하기 전에 매개 변수 hive.optimize.bucketmapjoin과 hive.enforce.bucketing을 모두 true로 설정하자. 버킷 테이블을 생성하는 예시는 아래에 나와 있다.
CREATE TABLE mytable (
name string,
city string,
employee_id int )
PARTITIONED BY (year STRING, month STRING, day STRING)
CLUSTERED BY (employee_id) INTO 256 BUCKETS
;
위의 조인을 버킷 맵 조인이라고도 한다. 조인 테이블의 버킷 수가 같고 데이터를 조인 칼럼으로 정렬한 경우 정렬 병합 맵 조인을 사용한다.
조인 유형을 식별하는 방법
EXPLAIN 명령을 사용하면 맵 연산자 트리 바로 아래에 정렬 병합 버킷 맵 조인 연산자가 표시된다.
예제
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
Subscribe via RSS